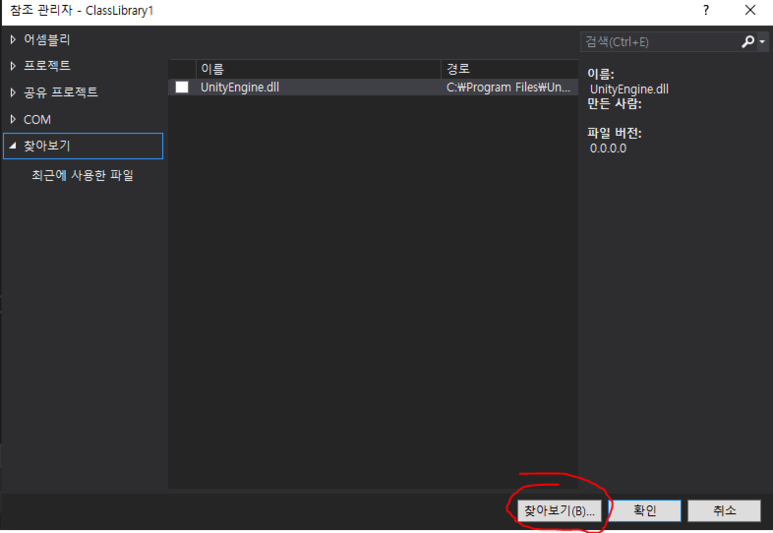
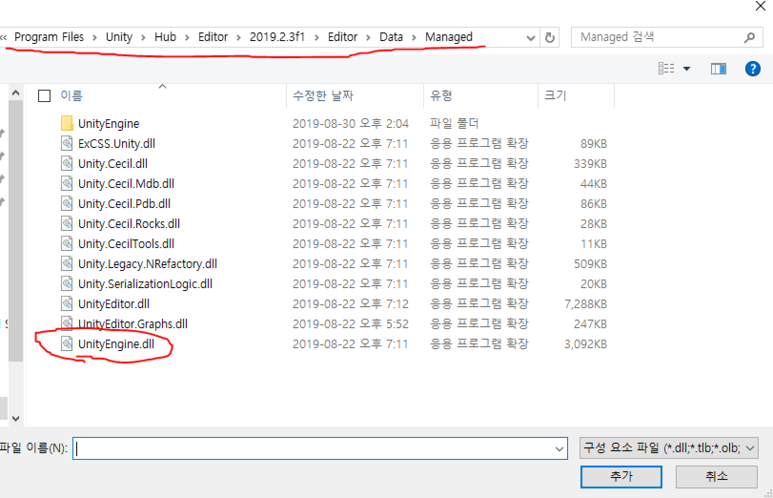
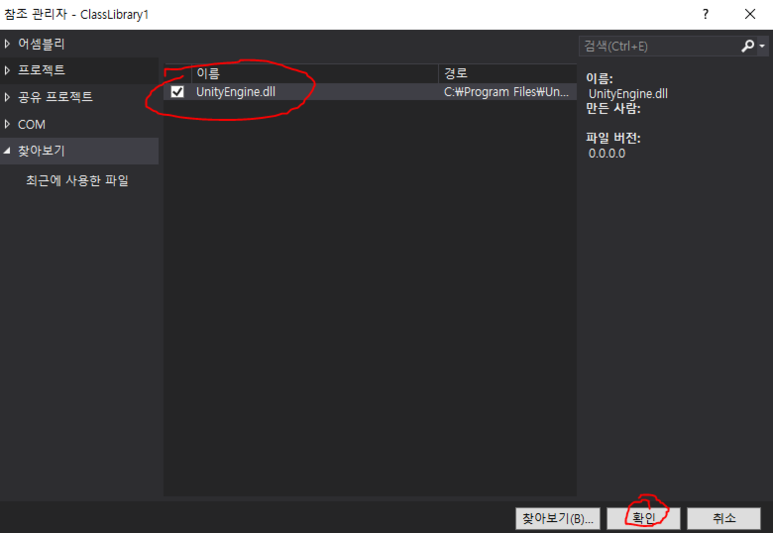
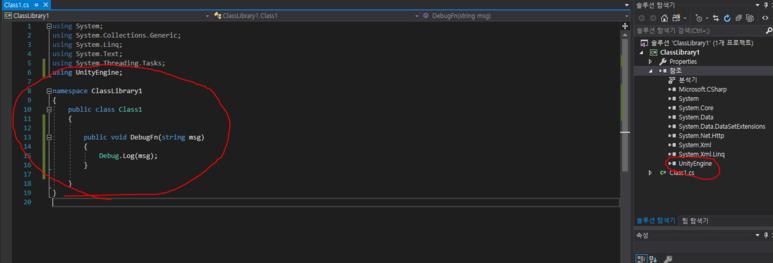
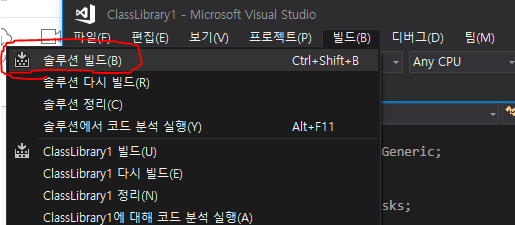
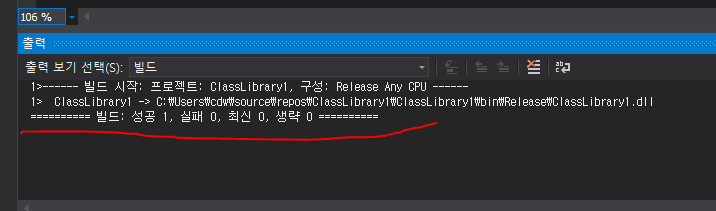
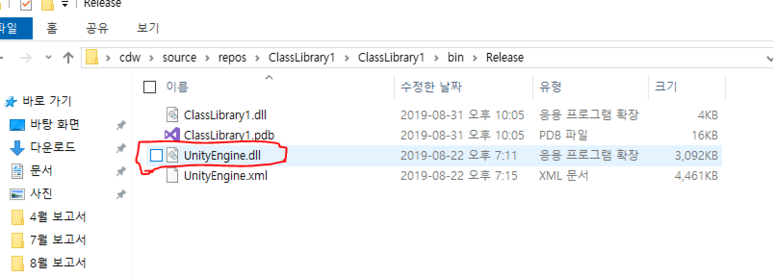
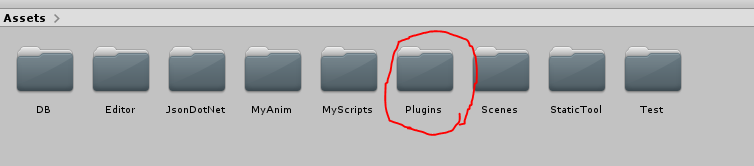
여기저기빛의세기에관해찾아보니“Radiance”와“Irradiance”라는용어가먼저튀어나옵니다.아~몰랑몰랑~~일단한국물리학회(The Koran Physics Society)에서발간한물리학용어집을찾아보니“Radiance”는“(복사)휘도”라고번역해놓았지만아쉽게도“Irradiance”라는용어에대해서는물리학용어집에서번역어를찾을수가없군요.참고로 Journal of the Korean Physics Society는 SCI(SCI IF=0.493)입니다. 한 14~15년 전에 논문 3편 실은 기억이 있네요... 그 때는 SCI IF 1.0 이상이었는데... 쩝!! 만일 JKPS의 IF가 3.0 이상으로 올라가면 이 곳에 논문을 다시 낼 의향은 충분히 있습니다... ^_^!!
강의를하다보면 대학생들임에도 불구하고 학생들이각도가단위를가지는물리량으로착각을하는경우가 상당히 많은데각도는단위를가지지않는무차원(Dimensionless)입니다.즉,단순히숫자를나타내는것입니다.지금 내가 말하고 있는숫자가 그냥 단순히 숫자를 나타내는 것이 아니고각도의의미로사용하고 있다는 것을 상대방에게 알려주기 위해서 편의상o, rad, sr을붙여주는것에불과합니다.
......
중략..
......
제 기준에서만 말하자면 “Radiance”와“Irradiance”의 단위로부터 강도 혹은 세기(Intensity)라는 용어보다는 단위시간당(per unit time) 단위면적당(per unit area)의 에너지량이라는 용어가 더 어울릴 것 같습니다. 일종의 유속(Flux)입니다.
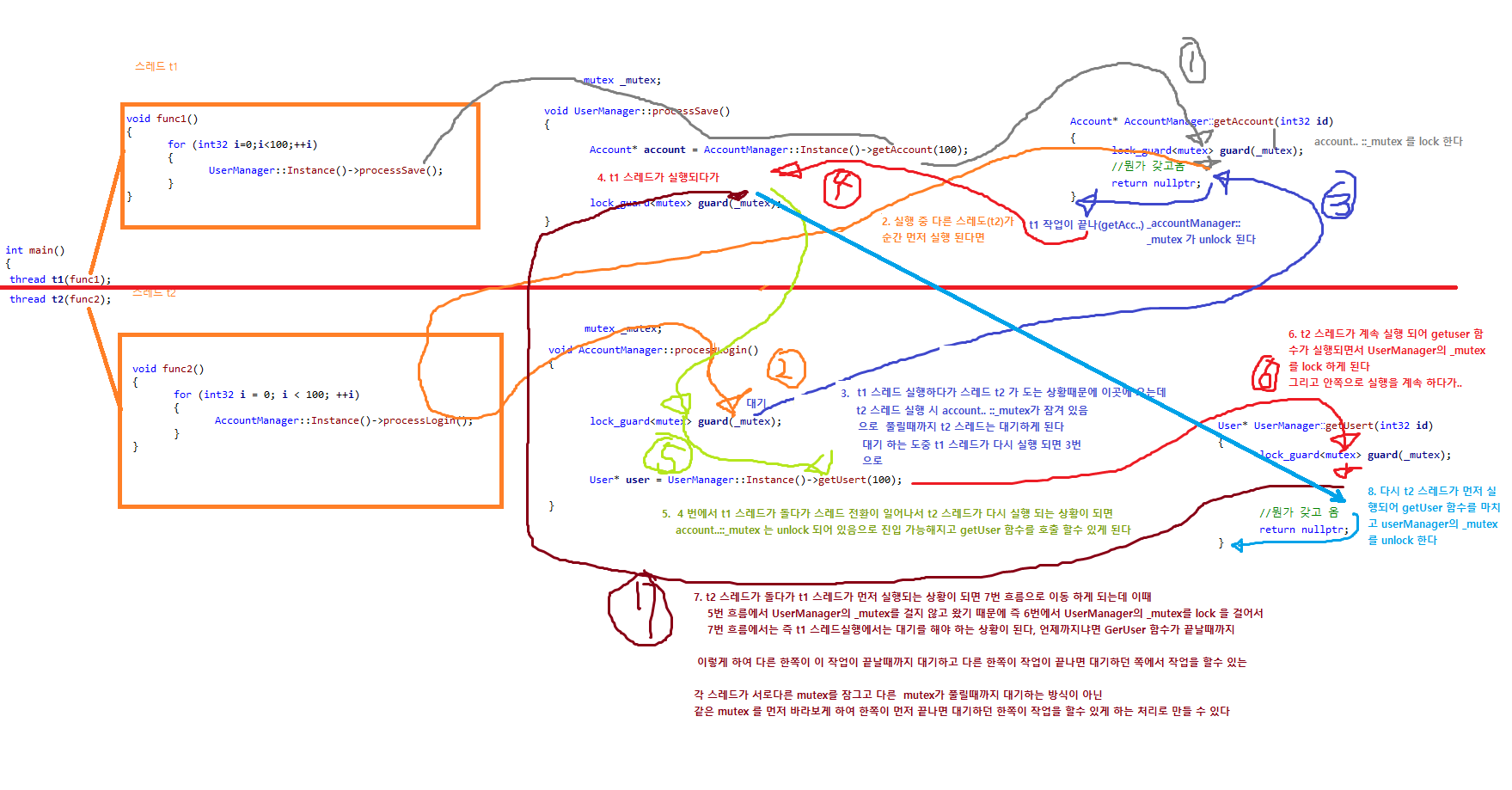
ProcessSave 에서 lock_guard 를 getAccount 함수와 실행 순서를 바꿔주어 DeadLock 현상을 피하게 한다
요약 :
t1 스레드가 getaccount 작업을 마칠때까지 t2 스레드는 아무것도 하지 않고 대기만 하다가 t1 작업이 끝나면 t2 가 작업 되게 한다
t2 스레드가 getUser 함수 작업이 완료 될되고 processLogin 함수가 완료 될떄까지 t1 을대기시키고 완료 되면 t1 이 실행되게 허용한다
t2 스레드가 실행되고 processLogin 에서 AccountManager::_mutex 를 lock 하고 getuser 작업을 하려는 직전에 ( UserManager::_mutex lock 못함) t1 스레드가 먼저 실행되어 getAccount가 실행 되는 경우 AccountManager 의 _Mutex 는 이미 lock 되어 있어서 t1 은대기 하게 되고 다시 t2가 실행 되어 UserManager::_mutex 를 lock 한다음 getUser 처리하고 processLogin 함수가 완료가 된 이후에야 AccountManager::_mutex가 unlock 이 되기 때문에 이때서야 t1 스레드의 getAccount 가 호출이 되고 processSave 함수또한 마무리 된다
ProcessSave 함수에서 UserManager::_mutex 를 lock_guard 한것은 Dead lock 을 피하기 위해 순서를 바꾸다 보니 이처럼 된것, 즉 AccountManager::_mutex 를 t1, t2 스레드에서 먼저 바라보게 처리해야지 Dead lock 을 피할 수 있으니 로직이 이처럼 순서가 바뀐것일 뿐
하지만 이렇게 순서를 바꾸는것은 보통 로직상 이런 경우가 잘 나오진 않는다
방법 2.
Dead lock 이 발생했을 경우 mutex 를 감싸는 warp 클래스를 만들어서 현재 mutex lock 되는 count 가 같은지 다른지를 판별해서 언제 문제가 발생하는지 파악할 수도 있다
방법.3
lock 을 거는 것을 각 상태별 graph state를 만들어 순환 구조가 나오면 Dead lock임으로 이걸 구조화하여 코드로 만들어서 순환이 일어나면 Dead lock 이 일어난다는 것을 디버깅을 통해 알 수 있게 할 수도 있다
push_back 하면서 capacity가 증가함 하지만 vector 자체는 멀티스레드호환 가능으로 만들어지지 않았음
용량이더 큰 것이 추가 되면서 재할당이 될 수 있는데 다른 두개 중 추가하는 스레드 외에 스레드에서 이미 벡터의 메모리를 제거했을 수 있음 재할당으로 => crash
reserve 20000 을 해 줘도 size 변수를 갱신 할때 문제가 발생 할 수 있음 => 제대로 추가가 되지 않음
atomic<vector<int32>> 이것도 불가 atomic.load 등의 atomic 자체의 기능을 사용 하는것이기 vector 와 연결(연동)되지 않음
어쨌든 문제가 발생 할 수 있음
그럼 추가 할때 한번에 한 스레드만 허용가능하도록 lock 처리를 해줘야 함 lock 으로 잠그면 다른 스레드가 접근 불가 unlock 하기 전까지
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic> //멀티 플랫폼에서 작동 가능
#include <vector>
#include <mutex>
using namespace std;
vector<int32> v;
mutex m; //화장실의 자물쇠 같은것
void push()
{
for (int32 i = 0; i < 10000; ++i)
{
m.lock(); //자물쇠로 잠그고 하나의 스레드만 진입 가능
v.push_back(i);
m.unlock(); //자물쇠 품
}
}
int main()
{
thread t1(push);
thread t2(push);
t1.join();
t2.join();
cout << v.size() << endl;
return 0;
}
하지만 lock 을 쓸때 병합이 너무 심해지면 일반 적인 상황보다는 느려지게 된다
재귀적으로 lock 을 걸면?
불가능 함, 하지만 recursive mutex 로 가능해짐
=> 코드가 복잡해지면 이함수 안에서 다른 함수를 호출 할때 재귀적으로 락을 걸고 싶을 때가 있을 수 있음
문제가 발생 할수 있는 또 다 른 상황
for 문에서
if(i==10)
{
break;
}
로 빠져나올때 unlock() 을 안하면 무한대기 상태가 됨 (Dead lock) 상황이 됨
수동으로 lock, unlock 하는건 실수가 발생 할수 이씩 때문에
RAII (Resource Acqusition Is Initialization)
warp 클래스를 만들어 생성자에서 mutex를 받아 잠그고 소멸자에서 풀어주는 방식으로 사용함
표준적으로 std::lock_guard<> 가 제공 됨
unique_lock 이 존재하는데 lock 하는 시점이 lock_guard 처럼 생성함고 동시에 lock 이 아닌
지연 시켜 lock 을 할 수 있다
The classunique_lockis a general-purpose mutex ownership wrapper allowing deferred locking, time-constrained attempts at locking, recursive locking, transfer of lock ownership, and use with condition variables. The classunique_lockis movable, but not copyable -- it meets the requirements ofMoveConstructibleandMoveAssignablebut not ofCopyConstructibleorCopyAssignable.
The classunique_lockmeets theBasicLockablerequirements. IfMutexmeets theLockablerequirements,unique_lockalso meets theLockablerequirements (ex.: can be used instd::lock); ifMutexmeets theTimedLockablerequirements,unique_lockalso meets theTimedLockablerequirements.
"unique_lock과 lock_guard의 차이점은 lock을 걸 수 있는 시점이다. 둘 다 소멸 시점에 lock이 걸려 있다면 unlock을 수행한다. lock_guarud는 lock과 unlock 사이에서 lock과 unlock을 할 수 없지만 unique_lock은 소멸하기 전에 unlock과 lock을 걸 수 있다.
unique_lock은 lock_guard에 기능이 추가된 버전이라고 생각하면 된다."
void push()
{
for (int32 i = 0; i < 10000; ++i)
{
unique_lock<mutex> uniquLock(m, defer_lock); //이때 잠기지 않고
uniquLock.lock(); //이때 mutex 를 잠군다
v.push_back(i);
}
}
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread> //11부터 thread 가 다른 플랫폼에서도 구현 가능되도롯 멀티플랫폼으로 지원 됨 => linux 에서도 실행 가능
#include <vector>
using namespace std;
void HelloThread(int a)
{
std::cout << "Hello Thread " << a << std::endl;
}
int main()
{
vector<std::thread> t;
t.resize(1);
auto idtest = t[0].get_id(); //관리하고 있는 스레드가 없다면 id 는 0
t[0] = std::thread(HelloThread, 10);
if (t[0].joinable())
{
t[0].join();
}
std::cout <<" main " << std::endl;
return 0;
}
int main() { //cout 은 os 커널에 요청하여 요청된 처리가 다시 콘솔화면으로 오는 느린 실행이다 //HelloWorld();
//std::thread t(HelloThread); std::thread t;
auto idtest = t.get_id(); //관리하고 있는 스레드가 없다면 id 는 0
t = std::thread(HelloThread);
int32 count = t.hardware_concurrency(); //CPU 코어 개수는 몇개인지 힌트를 줌 => 논리적으로 실행할 수 있는 프로세스 개수 , 100% 확실한 동작이 되진 않을 수있어서 경우에따라 0 을리턴하면 제대로 조사가 안된 것
auto id = t.get_id(); // 각 쓰레드마다 부여되는 id , 쓰ㅜ레드 사이에서는 id 가 겹치지 않는다 t.detach(); //join 반대로 std::thread 객체에서 실제 스레드를 분리 => 스레드 객체 t 와 연결을 끊어줌 => 만들어진 스레듸이 정보를 더이상 사용 할수 없음
//쓰레드를 떼어내면, 쓰레드가 독립적으로 실행됩니다. 프로그램이 종료되면 떼어진 쓰레드는 동작이 멈추게 됩니다.
bool states = t.joinable(); //detach 되거나 연동된 슬레드가 없는 상태를 판별하기 위한 함수
//t.join(); //스레드가 끝날때까지 대기
if (t.joinable()) { t.join(); }
std::cout << "Hello Main" << std::endl;
return 0; }
위 코드에선 detach 하여 Join 을 하지 못하기 때문에 Hello Main 이 높은 확률로 나오는 것을 알 수 있다
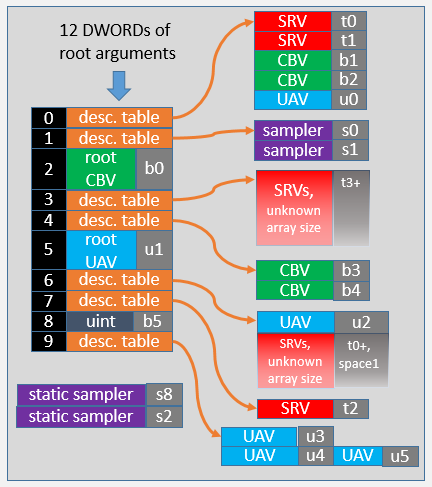
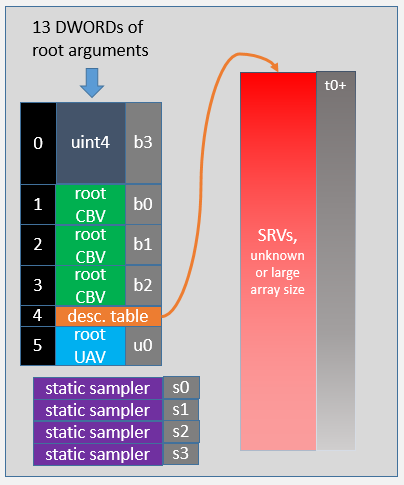
빈 루트 서명은 별로 유용하지 않을 수 있지만, 입력 어셈블러만 사용하는 간단한 렌더링 패스와 설명자에 액세스하지 않는 최소 꼭짓점 및 픽셀 셰이더에 사용할 수 있습니다. 또한 혼합 단계, 렌더링 대상 및 깊이 스텐실 단계에서도 빈 루트 서명을 사용할 수 있습니다.
단일 상수
API 바인딩 슬롯에서는 이 매개 변수의 루트 인수가 명령 목록 기록 시에 바인딩됩니다. API 바인딩 슬롯 수는 루트 서명의 매개 변수 순서에 따라 암시적입니다(첫 번째는 항상 0). HLSL 바인딩 슬롯에서 셰이더는 루트 매개 변수가 표시되는 것을 알 수 있습니다. 형식(위 예제의 "uint")은 하드웨어에 알려지지 않으며 이미지의 주석으로만 표시됩니다. 하드웨어는 콘텐츠로 단일 DWORD만 알 수 있습니다.
명령 목록 기록 시간에 상수를 바인딩하려면 다음과 비슷한 명령을 사용할 수 있습니다.
syntax복사
pCmdList->SetComputeRoot32BitConstant(0,seed); // 0 is the parameter index, seed is used by the shaders
루트 상수 버퍼 뷰 추가
이 예제에서는 두 개의 루트 상수와 DWORD 슬롯 2개에 상응하는 루트 CBV(상수 버퍼 뷰)를 보여 줍니다.
상수 버퍼 뷰를 바인딩하려면 다음과 같은 명령을 사용합니다. 첫 번째 매개 변수(2)는 이미지에 표시되는 슬롯입니다. 일반적으로 상수 배열이 설정된 후 셰이더의 b0에서 CBV로 사용할 수 있게 됩니다.
루트 서명의 또 다른 기능은 크기가 4개 DWORD인 float4 루트 상수입니다. 다음 명령은 4개 중에서 가운데에 있는 두 DWORD만 바인딩합니다.
syntax복사
pCmdList->SetComputeRoot32BitConstants(0,2,myFloat2Array,1); // 2 constants starting at offset 1 (middle 2 values in float4)
좀 더 복잡한 루트 서명
이 예제에서는 대부분의 항목 형식을 갖는 조밀한 루트 서명을 보여 줍니다. 설명자 테이블 중 2개(슬롯 3 및 6)에는 바인딩되지 않은 크기 배열이 포함됩니다. 여기서는 애플리케이션이 힙의 유효한 설명자에만 연결해야 합니다. 바인딩되지 않은 배열 또는 아주 큰 배열에는 하드웨어 계층 2보다 높은 리소스 바인딩 지원이 필요합니다.
2개의 정적 샘플러(루트 서명 슬롯을 요구하지 않고 바인딩됨)가 있습니다.
슬롯 9에서 UAV u4 및 UAV u5는 동일한 설명자 테이블 오프셋에서 선언됩니다. 별칭이 지정된 설명자는 이렇게 사용되며, 메모리에 한 설명자가 HLSL 셰이더에서 u4 및 u5 둘 다로 표시됩니다. 이 경우 셰이더는 fxC의 D3D10_SHADER_RESOURCES_MAY_ALIAS 옵션 또는/res_may_alias옵션으로 컴파일되어야 합니다. 설명자에 별칭을 지정하면 셰이더를 변경하지 않고도 여러 바인딩 요소에 하나의 설명자를 바인딩할 수 있습니다.
스트리밍 셰이더 리소스 뷰
이 루트 서명은 모든 SRV가 하나의 큰 배열 내/외부로 스트리밍되는 시나리오를 보여 줍니다. 실행 시 설명자 테이블은 루트 서명이 설정될 때 한 번만 설정할 수 있습니다. 그러면 첫 번째 일부 루트 인수를 통해 공급되는 상수를 통해 배열로 인덱싱하여 모든 텍스처 읽기가 수행됩니다. 단일 설명자 힙만 필요하며, 텍스처가 사용 가능한 설명자 슬롯 내/외부로 스트리밍될 때만 업데이트됩니다.
큰 힙의 설명자 오프셋은 상수 버퍼 뷰의 상수를 사용하여 셰이더에서 식별됩니다. 예를 들어, 셰이더에 재료 ID가 지정되면 해당 상수를 사용하여 하나의 큰 배열로 인덱싱함으로써 필요한 설명자(필수 텍스처 참조)에 액세스할 수 있습니다.
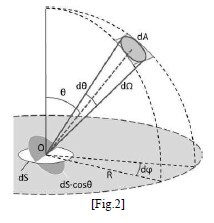
BSDF (Bidrectional ScatteringDistribution Function, 양반향 산란 분포 함수)
BSDF (Bidrectional ScatteringDistribution Function, 양반향 산란 분포 함수) - 우리가 일반적으로 사용하는 shading model들은 BxDF라는 함수들을 특수화한 model들 이다. BSDF는 빛이 어떤 물체에 부딪쳤을 때 얼마나 많은 빛이 반사되는가를 나타낸다. BSDF는 반사현상을 위한 Reflected 요소와 투과현상을 위한 Transmitted 요소로 나뉘며 이를 각각 BRDF(B Reflectance D F, 양반향 반사율 분포 함수)과 BTDF(B Transmittance D F 양반향 투과율 분포 함수)라고 한다.
즉, BSDF가 BRDF와 BTDF의 상위집합이다.
BRDF는 불투명한 표면에서 빛이 반사하는 방식을 정의하는 4차 함수이며 BSSRDF를 간략화 하였다. 간단하게 말하자면 BSSRDF(Bidirectional Surface Scattering Reflectance Distribution Function)은 8차함수이며, 표면 내부에서의 산란을 표현한다.
BRDF (Bidrectional Reflectance
Function, 양반향 반사율 분포 함수) - 단순하게 말하자면 입사하는 빛에 따른 반사하는 빛의 비율에 대한 함수.
- BRDF는 빛이 표면에서 어떻게 반사되는지 설명해 주는 함수, BTDF는 표면에서 어떻게 투과되는지 설명해 주는 함수.
- BRDF의 양방향성 : 만약 BRDF가 실제 물리법칙을 따르는 함수로 만들어졌다면,
입사와 반사의 방향이 바뀌어도 그 함수값은 바뀌지 않는다.
- BRDF의 비등방성 : 입사와 반사된 방향이 고정되고 표면의 법선을 축으로 표면이 회전된다면
해당 표면요소의 반사되는 비율은 변할 것이다.
즉, 표면의 재질이 들어오는 빛의 방향에 따라 다른 반사율을 가진다는 뜻이다 (알루미늄이나 옷감등).
하지만 다른 많은 재질들이 매끄러워 표면의 위치와 방향에 상관없이 같은 반사율을 가진다 (등방성 재질)
- 일반적인 BRDF를 질적으로 다른 세 개의 컴퍼넌트로 다루는 것이 편리하다.
각각을 완전 거울 반영(perfect mirror specular)반사, 완전 산란 반사(perfect diffuse reflection), 그리고 광택반사(glossy)이다.
BRDF가 왜 중요한가?
예를 들어 물을 물처럼 보이기 위해 Lighting이라는 개념이 들어가는데 렘버트의 단순함 만으로는
사실적인 결과물을 얻기 힘들다. 렘버트는 빛이 입사하는 방향에 관계없이 모든 방향으로 같은 양의 빛을
반사한다고 가정하기 때문이다. (렘버트 모델은 상수 BRDF에 의해 완벽하게 분산 표면을 표현한다).
하지만 실제로 물을 본다면 물을 바라보는 위치에 따라 물의 빛의 반사정도나 투과정도가 다르다는 것을 알 수 있다.
즉, 특정 표면이 현재 내가 바라보는 시점과 빛과의 관계에 따른 특정값을 얻을 필요가 있는 것이다.
BRDF 이론중 특별히 중요한 미립면(microfacet) 이론.
평평해 보이는 면도 사실 세밀하게 거친 면이 있기에 거울처럼 완전 평평한 물체에서 나타나는 정반사가
나타나틑게 아니라, 각 미립자간의 상호 반사나 표면 물질의 자체적인 산란으로 인해 빛의 반사가 희미해 진다.
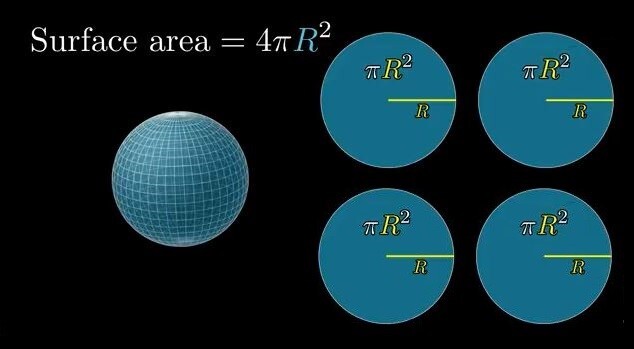
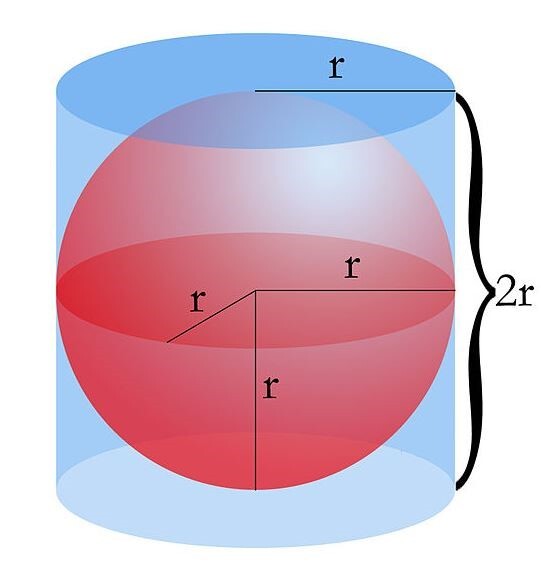
이 미립자 BRDF 샘플의 공식을 보면 아래와 같다.
F는 프레넬, G는 기하감쇠, D는 미세면 분포함수이다.
BSSRDF (B Surface Scattering Reflectance D F, 양방향 표면 분산 반사 분포 함수)에 대한 글.
Hi, I’m wondering why if writing pure virtual methods in my abstract base classes is supported? Currently I’ve got a class that inherits from actor and I’ve marked it as UCLASS(abstract) with a pure virtual method.
I then have a class that inherits from this class, and implements the pure virtual method. When I compile this I get the following error.
Only functions in the second interface class can be declared abstract.
Does that mean if I want to use pure virtual methods in my abstract class that I have to use a separate interface? If that’s the case, then what is the purpose of declaring my class abstract? Aren’t pure virtual methods what make classes abstract?
UClasses cannot really be abstract in the C++ sense, because the UObject sub-system requires that each class can be instantiated (it creates at least one instance of each class as a so called Class Default Object [CDO] that holds the default properties of that class). Therefore, every class method must have an implementation, even if it does nothing.
That being said, you can get similar behavior by decorating your inline method implementations with thePURE_VIRTUALmacro. This will tell the UObject sub-system that your intent is to declare a pure virtual method. So even though the method is not pure virtual in the C++ sense - it has a (possibly empty) function body - the compiler can still ensure that all child classes do supply an actual implementation.
You can find many more examples in the code base, including methods with return values by searching forPURE_VIRTUAL.
I’d like to add to this that the definition of the PURE_VIRTUAL macro is defined as
#define PURE_VIRTUAL(func,extra) { LowLevelFatalError(TEXT("Pure virtual not implemented (%s)"), TEXT(#func)); extra }.
In case you want a pure virtual with return type, the return must be part of the PURE_VIRTUAL macro. as it must be a complete function in the CPP sense.
This code does not compile, but i couldnot find what is wrong with the code. I think shared_ptr matters.
#include <memory>
#include <iostream>
using namespace std;
class A {
public:
virtual const void test() const = 0;
~A() { }
};
class AImpl : public A {
public:
const void test() const {
std::cout << "AImpl.test" << std::endl;
}
};
class B {
public:
B() { }
~B() {
}
shared_ptr<A> CreateA() {
a_ = make_shared<AImpl>(new AImpl());
return a_;
}
private:
shared_ptr<A> a_;
};
int main() {
B *b = new B();
shared_ptr<A> p = b->CreateA();
if (b) {
delete b;
b = NULL;
}
}
ou are usingmake_sharedincorrectly. You dont need to usenewinmake_shared, it defeats the whole purpose of this function template.
This function is typically used to replace the construction std::shared_ptr(new T(args...)) of a shared pointer from the raw pointer returned by a call to new. In contrast to that expression, std::make_shared typically allocates memory for the T object and for the std::shared_ptr's control block with a single memory allocation (this is a non-binding requirement in the Standard), where std::shared_ptr(new T(args...)) performs at least two memory allocations.
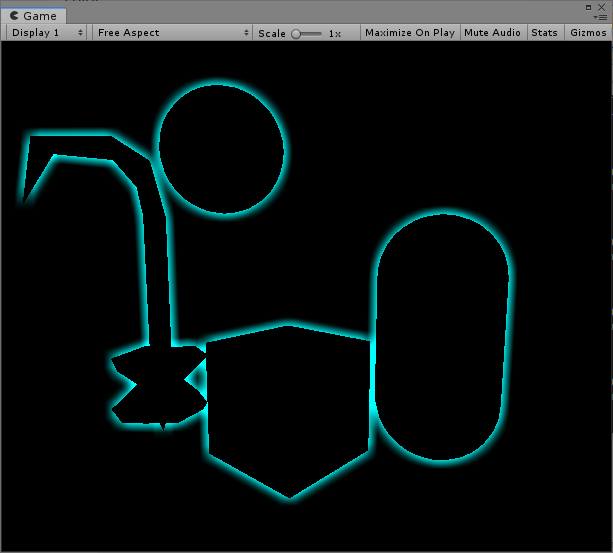
One of the most useful effects that isn’t already present in Unity is outlines.
Screenshot from Left 4 Dead. There are some scripts online that make the geometry bigger and then render it a second time, behind the first. This isn't what we want.
Artifacts from normal extrusion
What we need is a post-processing effect. We'll start by rendering only the objects we want outlined to an image. To do this, we'll use culling masks, which use layers to filter what objects should be rendered.
Make a new 'Outline' layer Then, we attach a script to our camera, which will create and render a second camera, masking everything that isn't to be outlined.
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class outline : MonoBehaviour
{
public Shader DrawAsSolidColor;
public Shader Outline;
Material _outlineMaterial;
Camera TempCam;
void Start(){
_outlineMaterial = new Material(Outline);
//setup the second camera which will render outlined objects
TempCam = new GameObject().AddComponent<Camera>();
}
//OnRenderImage is the hook after our scene's image has been rendered, so we can do post-processing.
void OnRenderImage(RenderTexture src, RenderTexture dst){
//set up the temporary camera
TempCam.CopyFrom(Camera.current);
TempCam.backgroundColor = Color.black;
TempCam.clearFlags = CameraClearFlags.Color;
//cull anything that isn't in the outline layer
TempCam.cullingMask = 1 << LayerMask.NameToLayer("Outline");
//allocate the video memory for the texture
var rt = RenderTexture.GetTemporary(src.width,src.height,0,RenderTextureFormat.R8);
//set up the camera to render to the new texture
TempCam.targetTexture = rt;
//use the simplest 3D shader you can find to redraw those objects
TempCam.RenderWithShader(DrawAsSolidColor, "");
//pass the temporary texture through the material, and to the destination texture.
Graphics.Blit(rt, dst, _outlineMaterial);
//free the video memory
RenderTexture.ReleaseTemporary(rt);
}
}
<<is the bit-shift operator. This takes the bits from the number on the left, and shifts them over by the number on the right. If 'Outline' is layer 8, it will shift 0001 over by 8 bits, giving the binary value 100000000. The hardware can this value to efficiently mask out other layers with a single bitwise AND operation.
We'll also need a shader to redraw our objects. No need for lighting or anything complicated, just a solid color.
Finally, let's make a shader that passes an image through as it received it. We'll use this file for outlines later.
Shader "Custom/Post Outline"
{
Properties
{
//Graphics.Blit() sets the "_MainTex" property to the source texture
_MainTex("Main Texture",2D)="black"{}
}
SubShader
{
Pass
{
CGPROGRAM
sampler2D _MainTex;
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct v2f
{
float4 pos : SV_POSITION;
float2 uvs : TEXCOORD0;
};
v2f vert (appdata_base v)
{
v2f o;
//Despite only drawing a quad to the screen from -1,-1 to 1,1, Unity altered our verts, and requires us to use UnityObjectToClipPos.
o.pos = UnityObjectToClipPos(v.vertex);
//Also, the UVs show up in the top right corner for some reason, let's fix that.
o.uvs = o.pos.xy / 2 + 0.5;
return o;
}
half4 frag(v2f i) : COLOR
{
//return the texture we just looked up
return tex2D(_MainTex,i.uvs.xy);
}
ENDCG
}
//end pass
}
//end subshader
}
//end shader
Put the outline component on the camera, drag the shaders to the component, and now we have our mask!
* Render just the geometry to be outlined
Once we have a mask, let's sample every pixel nearby, and if the mask is present, add some color to this pixel. This effectively makes the mask bigger and blurry.
Shader "Custom/Post Outline"
{
Properties
{
_MainTex("Main Texture",2D)="black"{}
}
SubShader
{
Pass
{
CGPROGRAM
sampler2D _MainTex;
//<SamplerName>_TexelSize is a float2 that says how much screen space a texel occupies.
float2 _MainTex_TexelSize;
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct v2f
{
float4 pos : SV_POSITION;
float2 uvs : TEXCOORD0;
};
v2f vert (appdata_base v)
{
v2f o;
o.pos = UnityObjectToClipPos(v.vertex);
o.uvs = o.pos.xy / 2 + 0.5;
return o;
}
half4 frag(v2f i) : COLOR
{
//arbitrary number of iterations for now
int NumberOfIterations=19;
//turn "_MainTex_TexelSize" into smaller words for reading
float TX_x=_MainTex_TexelSize.x;
float TX_y=_MainTex_TexelSize.y;
//and a final intensity that increments based on surrounding intensities.
float ColorIntensityInRadius=0;
//for every iteration we need to do horizontally
for(int k=0;k < NumberOfIterations;k+=1)
{
//for every iteration we need to do vertically
for(int j=0;j < NumberOfIterations;j+=1)
{
//increase our output color by the pixels in the area
ColorIntensityInRadius+=tex2D(
_MainTex,
i.uvs.xy+float2
(
(k-NumberOfIterations/2)*TX_x,
(j-NumberOfIterations/2)*TX_y
)
).r;
}
}
//output some intensity of teal
return ColorIntensityInRadius*half4(0,1,1,1)*0.005;
}
ENDCG
}
//end pass
}
//end subshader
}
//end shader
* Sampling surrounding pixels, we redraw the previous image but all colored elements are now bigger
Then, sample the input pixel directly underneath, and if it's colored, draw black instead:
*Hey, now it's looking like an outline!
Looking good! Next, we'll need to pass the scene to our shader, and have the shader draw the original scene instead of black.
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
public class outline : MonoBehaviour
{
public Shader DrawAsSolidColor;
public Shader Outline;
Material _outlineMaterial;
Camera TempCam;
void Start()
{
_outlineMaterial = new Material(Outline);
TempCam = new GameObject().AddComponent<Camera>();
}
void OnRenderImage(RenderTexture src, RenderTexture dst){
TempCam.CopyFrom(Camera.current);
TempCam.backgroundColor = Color.black;
TempCam.clearFlags = CameraClearFlags.Color;
TempCam.cullingMask = 1 << LayerMask.NameToLayer("Outline");
var rt = RenderTexture.GetTemporary(src.width,src.height,0,RenderTextureFormat.R8);
TempCam.targetTexture = rt;
TempCam.RenderWithShader(DrawAsSolidColor, "");
_outlineMaterial.SetTexture("_SceneTex", src);
Graphics.Blit(rt, dst, _outlineMaterial);
RenderTexture.ReleaseTemporary(rt);
}
}
Shader "Custom/Post Outline"
{
Properties
{
_MainTex("Main Texture",2D)="black"{}
_SceneTex("Scene Texture",2D)="black"{}
}
SubShader
{
Pass
{
CGPROGRAM
sampler2D _MainTex;
sampler2D _SceneTex;
float2 _MainTex_TexelSize;
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct v2f
{
float4 pos : SV_POSITION;
float2 uvs : TEXCOORD0;
};
v2f vert (appdata_base v)
{
v2f o;
o.pos = UnityObjectToClipPos(v.vertex);
o.uvs = o.pos.xy / 2 + 0.5;
return o;
}
half4 frag(v2f i) : COLOR
{
//if something already exists underneath the fragment, discard the fragment.
if(tex2D(_MainTex,i.uvs.xy).r>0)
{
return tex2D(_SceneTex,i.uvs.xy);
}
int NumberOfIterations=19;
float TX_x=_MainTex_TexelSize.x;
float TX_y=_MainTex_TexelSize.y;
float ColorIntensityInRadius=0;
for(int k=0;k < NumberOfIterations;k+=1)
{
for(int j=0;j < NumberOfIterations;j+=1)
{
ColorIntensityInRadius+=tex2D(
_MainTex,
i.uvs.xy+float2
(
(k-NumberOfIterations/2)*TX_x,
(j-NumberOfIterations/2)*TX_y
)
).r;
}
}
//this value will be pretty high, so we won't see a blur. let's lower it for now.
ColorIntensityInRadius*=0.005;
//output some intensity of teal
half4 color= tex2D(_SceneTex,i.uvs.xy)+ColorIntensityInRadius*half4(0,1,1,1);
//don't want our teal outline to be white in cases where there's too much red
color.r=max(tex2D(_SceneTex,i.uvs.xy).r-ColorIntensityInRadius,0);
return color;
}
ENDCG
}
//end pass
}
//end subshader
}
//end shader
여기까지는 평균내어 블러 처리 한것인데 하단 부터는 가우시안 블러를 적용하여 블러 처리 한 부분으로 변경한 것이다
This is almost where we want it, but we do have one more step! There are some problems with this outline right now. You might notice it looks a little off, and that the outline doesn't contour the corners nicely.
There's also the issue of performance - at 19x19 samples per pixel for the outline, this isn't a big issue. But what if we want a 40 pixel outline? 40x40 samples would be1600 samples per pixel!
We're going to solve both of these issues with a gaussian blur. In a Gaussian blur, a kernel(a weight table) is made and colors are added equal to the nearby colors times the weight.
Gaussian blurs look nice and natural, and they have a performance benefit. If we start with a 1-dimensional Gaussian kernel, we can blur everything horizontally,
and then blur everything vertically after, to get the same result.
This means our 40 width outline will only have 80 samples per pixel.
//http://haishibai.blogspot.com/2009/09/image-processing-c-tutorial-4-gaussian.html
public static class GaussianKernel
{
public static float[] Calculate(double sigma, int size)
{
float[] ret = new float[size];
double sum = 0;
int half = size / 2;
for (int i = 0; i < size; i++)
{
ret[i] = (float) (1 / (Math.Sqrt(2 * Math.PI) * sigma) * Math.Exp(-(i - half) * (i - half) / (2 * sigma * sigma)));
sum += ret[i];
}
return ret;
}
}
The sigma is an arbitrary number, indicating the strength of the kernel and the blur.
The size is to stop generating tiny numbers in an infinite kernel. Technically, Gaussian kernels would have no zeroes, so we want to cut it off once it isn't noticeable. I recommend the width be 4 times the sigma.
We calculate the kernel, and pass it to the shader. I have it set to a fixed size, but you could pass a kernel texture instead to handle varying widths.
using System;
using UnityEngine;
public class outline : MonoBehaviour
{
public Shader DrawAsSolidColor;
public Shader Outline;
Material _outlineMaterial;
Camera TempCam;
float[] kernel;
void Start()
{
_outlineMaterial = new Material(Outline);
TempCam = new GameObject().AddComponent<Camera>();
kernel = GaussianKernel.Calculate(5, 21);
}
void OnRenderImage(RenderTexture src, RenderTexture dst)
{
TempCam.CopyFrom(Camera.current);
TempCam.backgroundColor = Color.black;
TempCam.clearFlags = CameraClearFlags.Color;
TempCam.cullingMask = 1 << LayerMask.NameToLayer("Outline");
var rt = RenderTexture.GetTemporary(src.width, src.height, 0, RenderTextureFormat.R8);
TempCam.targetTexture = rt;
TempCam.RenderWithShader(DrawAsSolidColor, "");
_outlineMaterial.SetFloatArray("kernel", kernel);
_outlineMaterial.SetInt("_kernelWidth", kernel.Length);
_outlineMaterial.SetTexture("_SceneTex", src);
//No need for more than 1 sample, which also makes the mask a little bigger than it should be.
rt.filterMode = FilterMode.Point;
Graphics.Blit(rt, dst, _outlineMaterial);
TempCam.targetTexture = src;
RenderTexture.ReleaseTemporary(rt);
}
}
We make a pass with the kernel, sampling every pixel and adding our pixel's value by the kernel times the sampled value. Call GrabPass to grab the resulting texture, and then make a second pass. The second pass does the vertical blur.
Shader "Custom/Post Outline"
{
Properties
{
_MainTex("Main Texture",2D)="black"{}
_SceneTex("Scene Texture",2D)="black"{}
_kernel("Gauss Kernel",Vector)=(0,0,0,0)
_kernelWidth("Gauss Kernel",Float)=1
}
SubShader
{
Pass
{
CGPROGRAM
float kernel[21];
float _kernelWidth;
sampler2D _MainTex;
sampler2D _SceneTex;
float2 _MainTex_TexelSize;
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct v2f
{
float4 pos : SV_POSITION;
float2 uvs : TEXCOORD0;
};
v2f vert (appdata_base v)
{
v2f o;
o.pos = UnityObjectToClipPos(v.vertex);
o.uvs = o.pos.xy / 2 + 0.5;
return o;
}
float4 frag(v2f i) : COLOR
{
int NumberOfIterations=_kernelWidth;
float TX_x=_MainTex_TexelSize.x;
float TX_y=_MainTex_TexelSize.y;
float ColorIntensityInRadius=0;
//for every iteration we need to do horizontally
for(int k=0;k<NumberOfIterations;k+=1)
{
ColorIntensityInRadius+=kernel[k]*tex2D(
_MainTex,
float2
(
i.uvs.x+(k-NumberOfIterations/2)*TX_x,
i.uvs.y
)
).r;
}
return ColorIntensityInRadius;
}
ENDCG
}
//end pass
//retrieve the texture rendered by the last pass, and give it to the next pass as _GrabTexture
GrabPass{}
//this pass is mostly a copy of the above one.
Pass
{
CGPROGRAM
float kernel[21];
float _kernelWidth;
sampler2D _MainTex;
sampler2D _SceneTex;
sampler2D _GrabTexture;
float2 _GrabTexture_TexelSize;
#pragma vertex vert
#pragma fragment frag
#include "UnityCG.cginc"
struct v2f
{
float4 pos : SV_POSITION;
float2 uvs : TEXCOORD0;
};
v2f vert (appdata_base v)
{
v2f o;
o.pos = UnityObjectToClipPos(v.vertex);
o.uvs = o.pos.xy / 2 + 0.5;
return o;
}
float4 frag(v2f i) : COLOR
{
float TX_x=_GrabTexture_TexelSize.x;
float TX_y=_GrabTexture_TexelSize.y;
//if something already exists underneath the fragment, draw the scene instead.
if(tex2D(_MainTex,i.uvs.xy).r>0)
{
return tex2D(_SceneTex,i.uvs.xy);
}
int NumberOfIterations=_kernelWidth;
float4 ColorIntensityInRadius=0;
for(int k=0;k < NumberOfIterations;k+=1)
{
ColorIntensityInRadius+=kernel[k]*tex2D(
_GrabTexture,
float2(i.uvs.x,
1-i.uvs.y+(k-NumberOfIterations/2)*TX_y)
);
}
//output the scene's color, plus our outline strength in teal.
half4 color= tex2D(_SceneTex,i.uvs.xy)+ColorIntensityInRadius*half4(0,1,1,1);
return color;
}
ENDCG
}
//end pass
}
//end subshader
}
//end shader
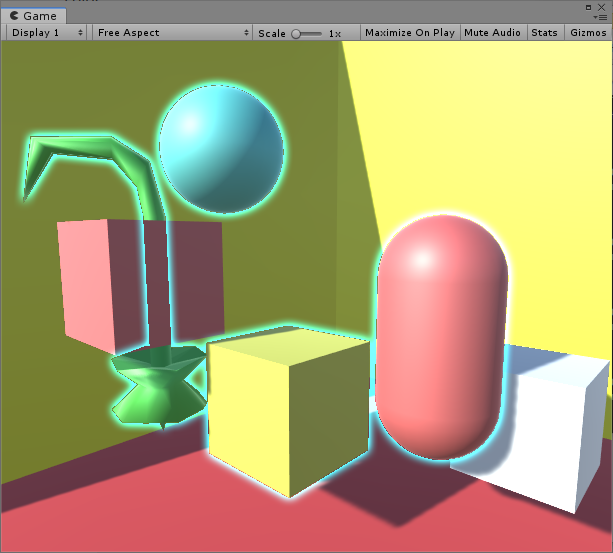
The finished effect!
결과를 보면 좀더 밖으로 빠질 수록 자연스럽게 블러처리가 된 것을 볼 수 있다
Where to go from here
Try adding multiple colors. You could also sample the added color from another texture to make a neat pattern. Regenerate the kernel when the resolution changes to get an effect that scales up.
Help!
My outline looks blocky. Most likely, your sigma is too high and your width too low, so the kernel is cut off earlier than it should be. Or, your kernel isn't being generated or used correctly.
Performance problems/crashes Are you using RenderTexture.GetTemporary() and RenderTexture.ReleaseTemporary()? Unity doesn't release normal RTs for some reason, so you need to use the temporary methods. Check the profiler to see what's up.
Something is upside-down/too big/in the corner of the screen Unity has inconsistenciesand so does OpenGL. There is a pragma,#if UNITY_UV_STARTS_AT_TOP, that can be used.
Something isn't working. Use the frame debugger to see what's happening to your graphics. Otherwise, check for any errors.
std에 존재하는 lock 방법들은 운영체제 단에서 지원하는크리티컬 섹션을 래핑한 mutex를 기반으로 개발자가 쉽게 락을 걸 수 있도록 도와줍니다. 앞서 배운 lock_guard 또한 mutex를 쉽게 사용할 수 있도록 도와 줍니다.
여기서 중요한 점은 mutex와 lock은 분명히 다른 역할을 하는 것입니다. mutex는 다른 쓰레드가 공유자원에 접근을 하지 못하게 만드는 동기화 객체입니다. 공유 자원에 접근하기 위해서는 mutex에 대한 잠금을 획득하고, 접근 후에는 잠금을 해제 해야 합니다.
lock은 이러한 mutex를 기반으로 잠글수 있는 기능을 캡슐화 한 객체 입니다. 쉽게 생각하면 자물쇠가 lock 이고, 자물쇠의 열쇠 구멍을 mutex라고 생각 할 수 있습니다. 이러한 객체들은 개발자가 쉽고 간편하게 공유자원의 동시접근을 막을 수 있도록 도와줍니다.
기본적인 lock의 종류
std::mutex
앞서 정리했던 mutex 역시 가장 기본적이고 핵심이 되는 부분입니다. c++의 lock은 이러한 mutex를 베이스로 개발자가 더 쉽고 간편하게 다양한 기능들을 쓸 수 있도록 도와줍니다.
std::unique_lock은 기본적으로 lock_guard와 비슷한 특징을 가지고 있습니다. 둘 다 자신의 생명주기를 가지며 소멸 될 때 unlock 됩니다. std::unique_lock은 기본적으로 생성과 동시에 lock이 걸리고 소멸시에 unlock되지만 그밖에도 옵션을 통해 생성시 lock을 안 시키기고 따로 특정 시점에 lock을 걸 수도 있습니다.
생성자의 인자로 mutex만 넘겨 준다면 생성 시에 lock이 걸리게 됩니다. 생성자의 인자로 mutex와 함께std::defer_lock,std::try_to_lock,std::adopt_lock을 넘겨 줄 수 있습니다. 세가지 모두 컴파일 타임 상수 입니다.
std::defer_lock : 기본적으로 lock이 걸리지 않으며 잠금 구조만 생성됩니다.lock()함수를 호출 될 때 잠금이 됩니다. 둘 이상의 뮤텍스를 사용하는 상황에서 데드락이 발생 할 수 있습니다.(std::lock을 사용한다면 해결 가능합니다.)
std::try_to_lock : 기본적으로 lock이 걸리지 않으며 잠금 구조만 생성됩니다. 내부적으로try_lock()을 호출해 소유권을 가져오며 실패하더라도 바로 false를 반환 합니다.lock.owns_lock()등의 코드로 자신이 락을 걸 수 있는 지 확인이 필요합니다.
std::adopt_lock : 기본적으로 lock이 걸리지 않으며 잠금 구조만 생성됩니다. 현재 호출 된 쓰레드가 뮤텍스의 소유권을 가지고 있다고 가정합니다. 즉, 사용하려는 mutex 객체가 이미 lock 되어 있는 상태여야 합니다.(이미 lock 된 후 unlock을 하지않더라도 unique_lock 으로 생성 해 unlock해줄수 있습니다.)
위의 예제는unique_lock의 사용 예제 입니다. 각transfer함수를 쓰레드로 실행하며 그때 인자로mutex를 가진 Box 객체를 넘겨줍니다. 각 쓰레드에서는 lock을 걸고 계좌의 돈을 옮기는 로직을 수행합니다.
하지만 이와 같은 상황에서는 주석 친 부분과 같이 unique_lock을 2줄에 걸쳐 잠그는 코드는 사용해서는 안됩니다. 이러한 코드는 문제를 발생 시 킬 수 있는 여지가 존재합니다. 만약에 2줄에 걸쳐unique_lock을 이용해 락을 건다면 이때는 양쪽 다 락이 걸리는 데드락이 발생할 수 있기 때문입니다. 여기서는std::defer_lock을 이용해 생성자에서 잠그는 것이 아니라 잠금 구조만 생성을 하고 후에 잠그도록 하였습니다.
위와 같은 상황이라면쓰레드 1(from = acc1, to = acc2)이from.m(acc1)을 락 걸고 그 다음줄인to.m(acc2)를 수행하기 전에쓰레드 2(from = acc2, to = acc1)가 첫줄에서from.m(acc2)를 건 상황이 될 수 있습니다. 이때 두 쓰레드가 그 다음줄을 수행하려고 하지만 둘다 락이 걸려있는 상태이므로 대기를 하게 됩니다. 하지만 둘다 락을 풀어 주지 않기 때문에 데드락 현상이 발생하게 됩니다.
그래서 이런상환에서는std:lock을 이용해 동시에 락을 걸어 주어야 타이밍 이슈로 데드락이 발생하지 않습니다.
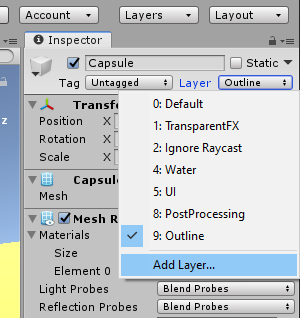
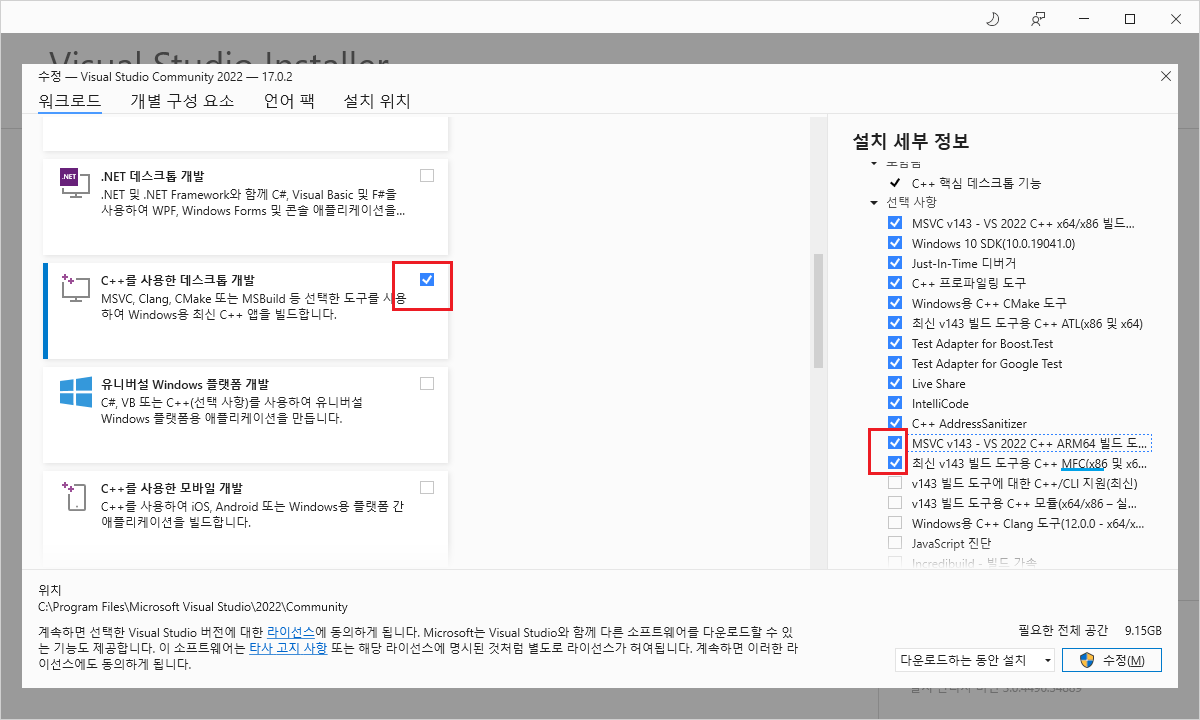
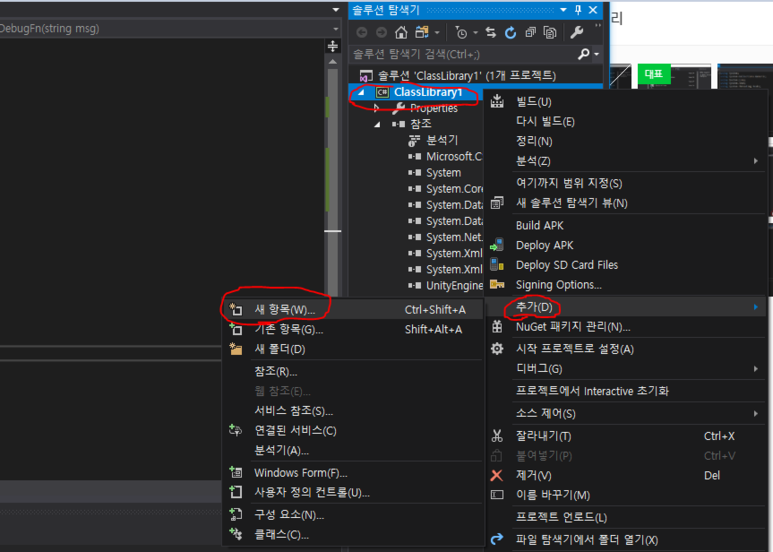
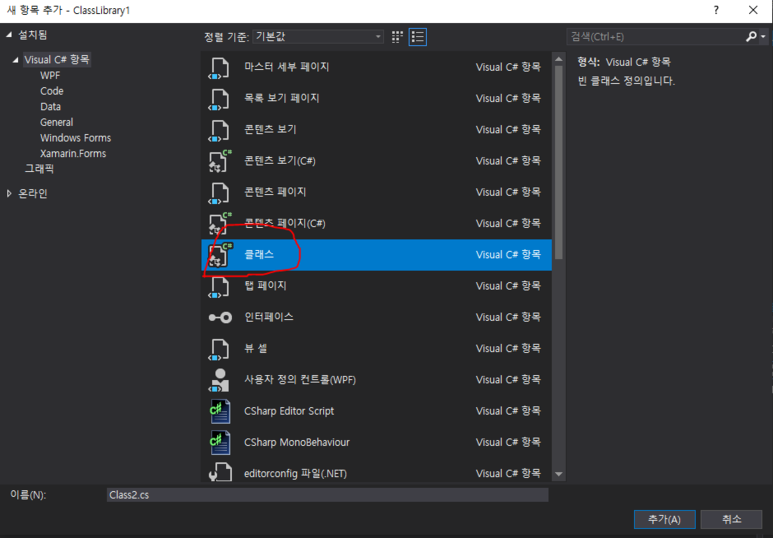
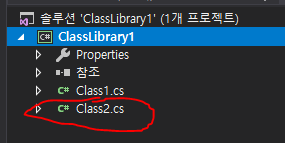
Visual Studio 실행하여 메뉴 : Tools -> Get Tools and Featues... 클릭하여 뜬 아래 창에서 상단 탭 워크로드 에서 C++ 을 사용한 데스크톱 개발 선택하고, 오른쪽 세부 선택에서 붉은 박스 부분 추가 선택하여 버튼 수정 클릭하면 설치완료됨.
Coroutine runningCoroutine = null; //코루틴 변수. 1개의 루틴만 돌리기 위해 저장한다.
//만약 이미 돌고 있는 코루틴이 있다면, 정지시킨 후 코루틴을 실행한다.
if(runningCoroutine != null)
{
StopCoroutine(runningCoroutine);
}
runningCoroutine = StartCoroutine(ScaleUp()); //코루틴을 시작하며, 동시에 저장한다.
정리하자면,
1. String으로 호출한 Coroutine은 String으로 멈출 것.
2. 직접 호출한 코루틴은 반환 값을 저장한 다음에 저장된 반환 값을 사용하여 멈출 것.
# 참고로 코루틴을 여러 개 돌리고 싶다면 변수 방식으로 해야 한다. string방식은 이름이 같은 모든 코루틴을 조작한다.
I feel like this is a pretty simple one, but I can’t wrap my head around it.
In a multiplayer game with a dedicated server and multiple players in the level, what will GetPlayerController(0) return?
What if it’s not a dedicated server game?
Is the answer different when the code runs on the server or on each of the clients?
My first guess is that the first player spawned into the level has the index 0. My second guess is that the index 0 is always with the “local” player for clients; not sure what it would be for the server. I’m edging towards guess 1 at the moment.
A :
Player 0 is the first player created on the machine that is running the code.
So if you have 2 players on the Server and 2 players on a client and 2 players on another client for a total of 6 players in the game over 3 computers,
then the server’s 2 players will be at index 0 and 1, and client A’s 2 players will be at index 0 and 1 on their machine. they will also be on the server’s machine but who knows what index they’ll be at there, and they’ll have IDs of -1 because they dont belong to the server machine.
client B, exact same situation.
So server will see 6 player controllers but only its own will have IDs >= 0 the others have IDs == -1
Each client will only see its own playercontrollers.
언리얼 엔진 4 는 다수의 멀티플레이어 함수성이 내장되어 있어, 네트워크를 통해 플레이 가능한 기본적인 블루프린트 게임을 쉽게 구성할 수 있습니다.간단히 뛰어들어멀티플레이어 게임 플레이를 시작해 볼 수 있습니다. 기본적인 멀티플레이어 기능이 지원되는 로직 대부분은 Character 클래스 및 삼인칭 템플릿에서 사용하는 CharacterMovementComponent 에 내장된 네트워킹 기능 지원 덕입니다.
게임플레이 프레임워크 검토
게임에 멀티플레이어 함수성을 추가하려면, 엔진에 제공되는 주요 게임플레이 클래스의 역할과 서로, 특히나 멀티플레이어 컨텍스트에서 어떻게 작동하는지를 이해하는 것이 중요합니다:
GameInstance 게임 인스턴스
GameMode 게임 모드
GameState 게임 스테이트
Pawn (및 거기서 상속되는 Character), 폰과 캐릭터
PlayerController 플레이어 컨트롤러
PlayerState 플레이어 스테이트
자세한 정보는게임플레이 프레임워크문서를 참고하시고, 멀티플레이어 게임을 디자인할 때는 최소한 다음의 팁 정도는 유념해 주시기 바랍니다:
GameInstance 는 엔진 세션 도중에만 존재합니다. 즉 엔진 시작 시 생성되며, 종료될 때까지 소멸 또는 대체되지 않습니다. 서버와 각 클라이언트마다 별도의 GameInstance 가 존재하며, 이 인스턴스는 서로 통신하지 않습니다. GameInstance 는 게임 세션 외부에 존재하므로, 특정 유형의 지속성 데이터를 저장하기에 좋은 곳입니다. 이를테면 플레이어 전반적인 통계 (지금까지 이긴 게임 횟수), 계정 정보 (특수 아이템 잠김/해제 상태), 언리얼 토너먼트같은 경쟁형 게임에서 돌아가며 플레이할 맵 목록 등을 말합니다.
GameMode 오브젝트는 서버에서만 존재합니다. 일반적으로 클라이언트가 명시적으로 알 필요가 없는 게임 관련 정보를 저장합니다. 예를 들어 "로켓 런처만" 나오는 특수 규칙 게임에서, 클라이언트는 이 정보를 알 필요가 없지만, 맵에 무기를 무작위로 스폰할 때 서버는 "로켓 런처" 카테고리에서만 선택해야한다 알아야 할 것입니다.
GameState 는 서버와 클라이언트에 존재하며, 서버는 GameState 상의 리플리케이티드 변수를 사용하여 모든 클라이언트에서 게임에 대한 데이터를 최신 상태로 유지할 수 있습니다. 예로, 야구 게임에서 GameState 를 통해 각 팀의 점수와 현재 이닝을 리플리케이트할 수 있습니다.
각 클라이언트에는 그 머신의 플레이어마다 하나의 PlayerController 가 존재합니다. 이는 서버와 연결된 클라이언트 사이에 리플리케이트되지만, 다른 클라이언트에는 리플리케이트되지 않으므로, 서버는 모든 플레이어에 대한 PlayerController 를 갖고 있고, 로컬 클라이언트는 로컬 플레이어에 대한 PlayerController 만 갖습니다. 클라이언트가 접속되어 있는 도중에는 PlayerController 가 존재하여 Pawn 에 할당되지만, Pawn 과는 달리 소멸되거나 리스폰되지는 않습니다. 특정 플레이어에게만 감지된 게임 이벤트에 반응하여 미니맵에 핑을 찍도록 서버가 클라이언트에게 알리는 등의 작업처럼, 다른 클라이언트에 리플리케이트할 필요 없는 클라이언트와 서버 사이 통신에 적합합니다.
PlayerState 는 게임에 접속된 모든 플레이어에 대해 서버와 클라이언트 양쪽에 존재합니다. 이 클래스는 소유중인 클라이언트만이 아닌 모든 클라이언트가 알아야 하는, 이를테면 프리-포-올 게임에서 각 플레이어의 현재 점수와 같은 리플리케이티드 프로퍼티에 사용할 수 있습니다. PlayerController 처럼 개별 Pawn 에 할당되지만, Pawn 과는 달리 소멸 및 리스폰되지 않습니다.
Pawn (및 Character 포함) 역시 서버와 모든 클라이언트에 존재하며, 리플리케이티드 변수 및 이벤트를 갖고 있습니다. 특정 변수나 이벤트에 대해 PlayeyController 를 쓸 것이냐, PlayerState 를 쓸 것이냐, Pawn 을 쓸 것이냐 하는 것은 상황에 따라 다르지만, 주로 고려할 것은 PlayerController 와 PlayerState 는 플레이어가 접속된 시간동안 그리고 게임이 새 레벨을 로드하지 않는 한 내도록 유지되는 반면, Pawn 은 그렇지 않을 수 있습니다. 예를 들어 Pawn 이 게임플레이 도중 죽는 경우, 보통 소멸되고 새로운 Pawn 으로 대체되는 반면, PlayerController 와 PlayerState 는 계속해서 존재하며 새로운 Pawn 의 스폰이 끝나면 거기에 할당됩니다. Pawn 의 생명력은 그래서 Pawn 자체에 저장되는데, 실제 그 Pawn 인스턴스에만 해당되며, 새로운 Pawn 으로 대체되면 리셋시켜야 하기 때문됩니다.
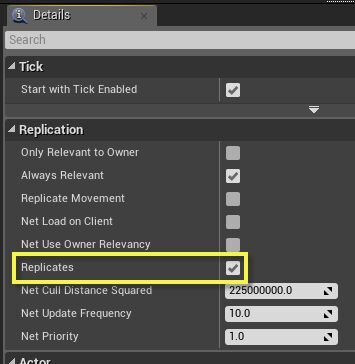
액터 리플리케이션
UE4 의 네트워킹 기술의 핵심은 액터 리플리케이션입니다. "Replicates" (리플리케이트) 옵션이 True 로 설정된 액터는 서버에서 그 서버에 연결된 클라이언트로 자동 동기화됩니다. 꼭 이해해야 할 점은, 액터는 서버에서 클라이언트로만 리플리케이트되지, 클라이언트에서 서버로 액터를 리플리케이트시키는 것은 불가능하다는 점입니다. 물론, 클라이언트에서 서버로 데이터를 전송하는 것이 가능은 하며, 리플리케이트되는 "Run on server" 이벤트를 통해 이루어집니다.
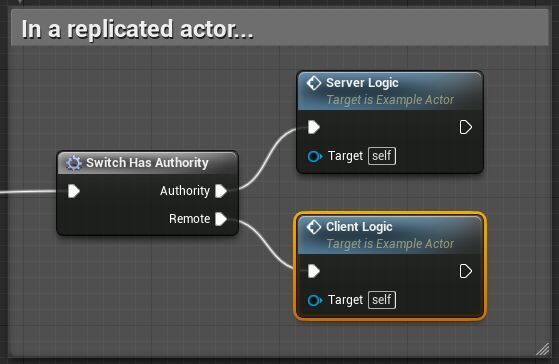
월드의 모든 액터에 대해서, 접속된 플레이어 중 하나는 해당 액터에 대해 오소리티가 있는 것으로 간주됩니다. 서버에 존재하는 모든 액터에 대해서, 서버는 모든 리플리케이티드 액터를 포함해서 해당 액터에 대해 오소리티를 갖습니다. 결과적으로 클라이언트에서Has Authority함수가 실행되고, 타깃이 그에게 리플리케이트된 액터인 경우, False 를 반환하게 됩니다. 또한Switch Has Authority편의 매크로를 사용하여 리플리케이트되는 액터에서 서버와 클라이언트에 따라 다른 동작을 하도록 하는 분기를 빠르게 만들 수도 있습니다.
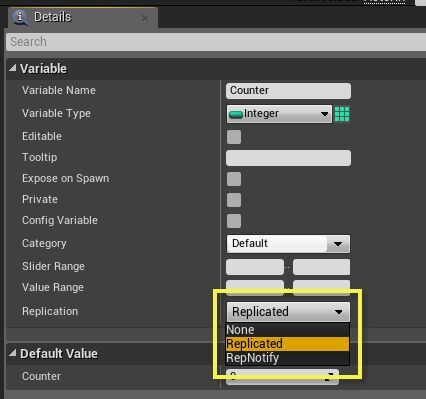
변수
액터상의 변수에 대한 디테일 패널에 보면리플리케이션드롭다운이 있어 변수 리플리케이션 방법을 조정할 수 있습니다.
옵션설명
None
없음 - 새 변수의 기본값으로, 이 값을 네트워크를 통해 클라이언트에 전송하지 않는다는 뜻입니다.
Replicated
리플리케이트됨 - 서버가 이 액터를 리플리케이트하면, 이 변수를 클라이언트에 전송합니다. 받는 클라이언트의 변수 값은 자동으로 업데이트되어, 다음 번 접근할 때 서버상에 있던 값을 반영합니다. 물론 실시간 네트워크를 통해 플레이할 때는, 네트워크 지연시간만큼 업데이트에 걸리는 시간이 지연됩니다. 기억할 것은 리플리케이티드 변수는 한 방향, 즉 서버에서 클라이언트로만 갑니다! 클라이언트에서 서버로 데이터를 전송하는 방법은 "이벤트" 부분을 확인하세요.
RepNotify
리플 알림 -Replicated옵션처럼 변수 리플리케이션은 하지만, 추가로 블루프린트에OnRep_<변수명>함수가 생성됩니다. 이 함수는 이 변수의 값이 변할 때마다 서버와 클라이언트에서 엔진에 의해 자동 호출됩니다. 이 함수는 게임의 필요에 따라 원하는 대로 자유롭게 구현해도 됩니다.
엔진의 내장 클래스 내 변수 다수에는 이미 리플리케이션이 켜져 있어서, 여러가지 기능이 멀티플레이어 상황에서도 자동으로 작동합니다.
리플리케이트되는 액터가 서버에 스폰되면, 클라이언트에 통신하여 거기서도 자동으로 그 액터 사본을 스폰합니다. 하지만 일반적으로 리플리케이션은 클라이언트에서 서버로 이루어지지 않기에, 리플리케이트되는 액터가 클라이언트에 스폰되는 경우 그 액터는 해당 클라이언트에만 존재하게 됩니다. 서버도 다른 클라이언트도 그 액터 사본을 받지 않습니다. 하지만 스폰하는 클라이언트는 그 액터에 대한 오소리티를 갖게 됩니다. 게임플레이에 영향을 끼치지 않는 장식성 액터같은 것에는 유용할 수 있지만, 게임플레이에 영향을 끼치고 리플리케이트시켜야 하는 액터의 경우 서버에서 스폰되도록 하는 것이 가장 좋습니다.
리플리케이트되는 액터를 소멸(destroy)시키는 상황도 비슷합니다: 서버가 하나를 소멸시키면, 모든 클라이언트에서도 각자의 사본을 소멸시킵니다. 클라이언트는 오소리티를 가진, 즉 직접 스폰시킨 액터를 자유롭게 소멸시킬 수 있는데, 다른 플레이어에 리플리케이트되지도 않았고 영향을 끼치지도 않을 것이기 때문입니다. 클라이언트가 오소리티를 갖지 않은 액터를 소멸 시도하는 경우, 그 소멸 요청은 무시됩니다. 여기서의 핵심 요점은 액터 스폰에도 마찬가지입니다: 리플리케이트되는 액터를 소멸시켜야 하는 경우, 서버에서 소멸시켜 주세요.
이벤트 리플리케이션
블루프린트에서 액터와 그 변수 리플리케이트에 추가로, 클라이언트와 서버 너머로 이벤트를 실행시킬 수도 있습니다.
RPC (Remote Procedure Call) 이라는 용어가 보이는데, 블루프린트에서 리플리케이트되는 이벤트는 본질적으로 엔진 내에서 RPC 로 (보통 C++ 에서는 그렇게 불립니다) 컴파일된다는 점만 알아두시면 됩니다.
오너십
멀티플레이어 작업시 이해해야 할 중요한 개념, 특히나 리플리케이트되는 이벤트 관련해서는, 어떤 접속을특정 액터 또는 컴포넌트의 오너로 간주할 것인지입니다. 우리 용도상 "Run on server" 이벤트는 클라이언트가 소유하는 액터 (또는 그 컴포넌트)에서만 호출 가능하다는 것을 압니다. 이게 무슨 뜻이냐면, 다음 액터 또는 그 액터 중 하나의 컴포넌트에서 "Run on server" 이벤트를 전송할 수만 있다는 뜻입니다:
클라이언트의 PlayerController 자체,
클라이언트의 PlayerController 가 빙의된 Pawn, 또는
클라이언트의 PlayerState.
마찬가지로 "Run on owning client" 이벤트를 전송하는 서버의 경우, 그 이벤트 역시 이 액터 중 하나에서 호출되어야 합니다. 그렇지 않으면 서버는 이벤트를 전송할 클라이언트를 알지 못하게 되어, 서버에서만 실행될 것입니다!
이벤트
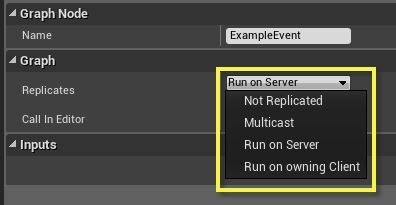
커스텀 이벤트의 디테일 패널에서, 이벤트 리플리케이션 방식을 설정할 수 있습니다.
옵션설명
Not Replicated
리플리케이트 안됨 - 기본값으로, 이 이벤트에 대한 리플리케이션이 없다는 뜻입니다. 클라이언트에서 호출되는 경우 해당 클라이언트에서만 실행되고, 서버에서 호출되는 경우 서버에서만 실행됩니다.
Multicast
멀티캐스트 - 서버에서 멀티캐스트 이벤트가 호출되면, 타깃 오브젝트를 어느 접속에서 소유했는지와 무관하게 접속된 모든 클라이언트에 리플리케이트됩니다. 클라이언트가 멀티캐스트 이벤트를 호출하는 경우, 리플리케이트되지 않은 것으로 간주, 호출한 클라이언트에서만 실행합니다.
Run on Server
서버에서 실행 - 이 이벤트가 서버에서 실행된 경우, 서버에서만 실행됩니다. 클라이언트에서 클라이언트가 소유한 타깃으로 실행된 경우, 서버에 리플리케이트되어 실행됩니다. "Run on Server" 이벤트는 클라이언트가 서버에 데이터를 전송하기 위한 주요 메서드입니다.
Run on Owning Client
소유 클라이언트에서 실행 - 서버에서 호출된 경우, 이 이벤트는 타깃 액터를 소유한 클라이언트에서 실행됩니다. 서버는 액터 자체를 소유할 수 있으므로, "Run on Owning Client" 이벤트는 그 이름과 무관하게 서버에서 실행 가능합니다. 클라이언트에서 호출된 경우, 이벤트는 리플리케이트되지 않은 것으로 간주, 호출한 클라이언트에서만 실행됩니다.
다음 표는 이벤트 호출 방법에 따라 여러가지 리플리케이션 모드가 이벤트 실행 위치에 어떠한 영향을 끼치는지 나타냅니다.
서버에서 이벤트가 호출된 경우, 타깃이 왼쪽 열이라 한다면, 실행되는 곳은...
리플리케이트 안됨멀티캐스트서버에서 실행소유 클라이언트에서 실행
클라이언트 소유 타깃
서버
서버와 모든 클라이언트
서버
타깃의 소유 클라이언트
서버 소유 타깃
서버
서버와 모든 클라이언트
서버
서버
미소유 타깃
서버
서버와 모든 클라이언트
서버
서버
이벤트가 클라이언트에서 호출된 경우, 타깃이 왼쪽 열이라 한다면, 실행되는 곳은...
리플리케이트 안됨멀티캐스트서버에서 실행소유 클라이언트에서 실행
호출 클라이언트에 소유된 타깃
호출 클라이언트
호출 클라이언트
서버
호출 클라이언트
다른 클라이언트에 소유된 타깃
호출 클라이언트
호출 클라이언트
버림
호출 클라이언트
서버 소유 타깃
호출 클라이언트
호출 클라이언트
버림
호출 클라이언트
미소유 타깃
호출 클라이언트
호출 클라이언트
버림
호출 클라이언트
위 표에서 볼 수 있듯이, 클라이언트에서 호출되면서서버에서 실행설정되지 않은 이벤트는 리플리케이트되지 않는 것으로 간주됩니다.
클라이언트에서 서버로 리플리케이트되는 이벤트를 전송하는 유일한 방법은 클라이언트에서 서버로 정보를 통신하는 방법뿐인데, 일반적인 액터 리플리케이션은 서버에서 클라이언트로만 이루어지도록 디자인되었기 때문입니다.
또한 멀티캐스트 이벤트는 서버에서만 전송 가능하다는 점도 눈여겨 봅시다. 언리얼의 클라리언트-서버 모델로 인해, 클라이언트는 다른 클라이언트와 직접 접속되지 않으며, 서버에만 접속됩니다. 그러므로 클라이언트에서 다른 클라이언트로 멀티캐스트 이벤트를 직접 전송하는 것은 불가능하고, 서버와의 통신이 반드시 있어야만 합니다.
리플리케이트되는 이벤트를서버에서 실행이벤트 하나,멀티캐스트이벤트 하나, 총 두 개를 사용하여 이러한 작동방식을 흉내낼 수는 있습니다.서버에서 실행이벤트의 구현은 필요하다면 인증을 거친 후 멀티캐스트 이벤트를 호출합니다.
그러면 멀티캐스트 이벤트 구현은 접속된 모든 플레이어에게 실행시키고자 하는 로직을 수행합니다.
인증을 전혀 하지 않는 예제의 경우, 다음 그림을 참고하세요:
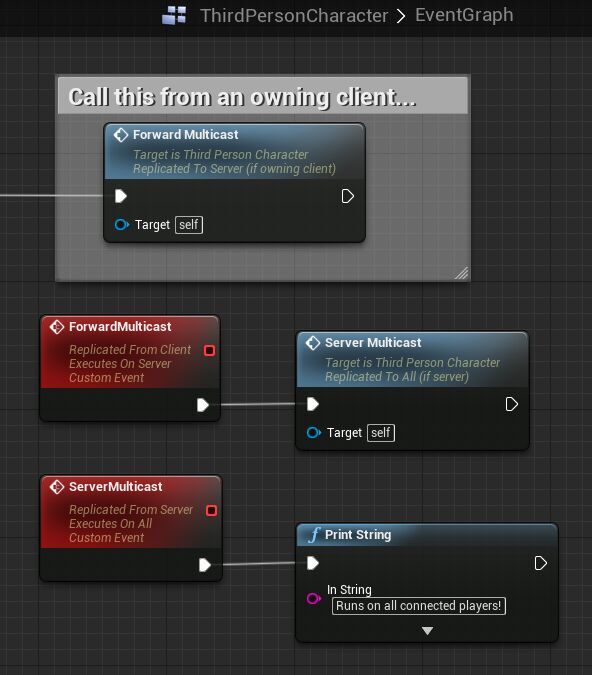
소유중인 클라에서 서버로 ForwardMulticast 를 콜하고 서버에선 전체 클라로 Server Multicast 를 보내는 예제이다
참가중 고려사항
게임 상태 변화 통신시 리플리케이티드 이벤트 사용시 염두에 둬야 할 점 한 가지는, 참가중 상태를 지원하는 게임을 어떻게 처리할 것인지 입니다. 플레이어가 진행중인 게임에 참가할 때, 참가 전에 일어난 리플리케이트되는 이벤트는 새 플레이어에게 실행되지 않을 것입니다. 여기서 한 가지 중요한 점은, 게임이 참가중 상태 처리를 제대로 하도록 하기 위해서는, 리플리케이트되는 변수를 통해 중요 게임플레이 데이터를 동기화시키는 것이 최선이라는 점입니다. 꽤 자주 겪게 되는 패턴은 클라이언트가 월드에서 어떤 동작을 하고, 서버는 "서버에서 실행" 이벤트를 통해 그 동작을 알린 뒤, 그 이벤트의 구현에서 서버는 그 동작에 따른 몇 가지 리플리케이트되는 변수를 업데이트합니다. 그러면 그 동작을 수행하지 않은 다른 클라이언트에서도 리플리케이트되는 변수를 통해 동작의 결과를 확인할 수 있게 됩니다. 추가로 동작이 벌어진 이후 참가중 상태였던 클라이언트도 월드 상태를 제대로 확인할 수 있게 되는데, 서버에서 리플리케이트되는 변수의 가장 최신 값을 받게 되기 때문입니다. 서버가 이벤트 전송만 했다면, 참가중 상태의 플레이어는 그런 동작이 있었는지 알지 못할 것입니다!
신뢰성
리플리케이트되는 이벤트에 대해Reliable(신뢰성)인지Unreliable(비신뢰성)인지 선택할 수 있습니다.
신뢰성이벤트는 (위의 오너십 규칙을 따른다는 가정하에) 목적지에 반드시 도달한다는 보장이 있습니다만, 그로 인해 보다 많은 대역폭을 필요로 하고, 지연시간이 길어질 수 있습니다. 신뢰성 이벤트를 너무 자주, 이를테면 매 틱마다 전송하지 않도록 하세요. 신뢰성 이벤트에 대한 엔진의 내부 버퍼가 넘칠(overflow) 수가 있으며, 그러한 현상이 발생하면 관련된 플레이어는 접속이 끊어질 것입니다!
비신뢰성이벤트는 이름이 암시하는 바대로 목적지에 도달하지 못할 수 있는데, 예를 들면 네트워크에서의 패킷 손실이라든가 엔진에서 우선권이 높은 부분을 먼저 전송하기 위해 트래픽을 차지하기로 결정한 경우입니다. 그에 따라 비신뢰성 이벤트는 신뢰성보다 대역폭을 적게 차지하며, 자주 호출해도 보다 안전합니다.
루멘은 씬과 라이트 변화에 즉각적으로 반응하는 완전 다이내믹 글로벌 일루미네이션 및 리플렉션 솔루션입니다. 아티스트와 디자이너는 루멘을 활용하여 더욱 다이내믹한 씬을 제작할 수 있습니다. 태양의 각도를 바꾸거나, 손전등을 켜거나, 외부의 문을 열거나, 벽에 구멍을 내면 상황에 따라 간접광과 리플렉션이 적용됩니다.
이 시스템은 밀리미터 단위의 디테일한 환경에서 킬로미터 단위의 광활한 환경까지 무한한 바운스와 간접 스펙큘러 리플렉션으로 디퓨즈 인터리플렉션을 렌더링합니다.
이제 아티스트와 디자이너는 사전 연산된 라이팅이 텍스처에 베이크되어 있는 스태틱 씬에 얽매이지 않습니다. 개별 스태틱 메시에 대한 라이트 맵 UV를 구성하거나 라이팅을 다시 빌드할 필요 없이 에디터 내에서 변화를 바로 확인할 수 있어 시간이 크게 절약됩니다.
루멘은 효율적인 소프트웨어 레이 트레이싱을 구현하여 글로벌 일루미네이션 및 리플렉션이 다양한 그래픽 카드에서 실행되도록 지원하는 동시에 고급 비주얼을 위한 하드웨어 레이 트레이싱도 지원합니다.
나나이트 가상화 지오메트리
나나이트의 가상화된 마이크로폴리곤 지오메트리 시스템을 사용하면 방대한 양의 지오메트릭 디테일이 포함된 게임을 만들 수 있습니다. ZBrush 스컬프트에서 사진측량 스캔까지 수백만 개의 폴리곤으로 구성된 영화 수준의 소스 아트를 바로 임포트하고, 리얼타임 프레임 레이트를 유지한 채로 눈에 띄는 퀄리티 손실 없이 수백만 번 배치할 수 있습니다.
나나이트는 인식 가능한 디테일만 스마트하게 스트리밍 및 처리하여 트라이앵글 수와 드로 콜의 제약을 크게 줄입니다. 노멀 맵에 디테일을 굽거나 디테일 레벨을 직접 작성하는 등 시간이 걸리는 작업을 제거하여 창작에만 집중할 수 있습니다.
언리얼 엔진 5 얼리 액세스 출시 이후로 나나이트에서 향상된 사항은 다음과 같습니다.
디스크에서 나나이트 메시의 크기를 줄이는 최적화 컨트롤
가장 중요도가 낮은 데이터를 제거함으로써 손실 압축에 가깝게 만들어 개발 과정에서 메시를 최적화할 수 있습니다. 예를 들어 테크 데모 ‘나나이트 세계의 루멘'에서는 조각상 중 하나의 가슴 부분에서 눈에 띄는 차이 없이 트라이앵글의 88%(및 디스크 크기)를 줄일 수 있었습니다.
압축 기능을 향상해 동일한 퀄리티의 나나이트 메시를 사용할 때 차지하는 공간을 20%까지 줄일 수 있었습니다.
UE4에서 UE5로 프로젝트 변환 시나나이트 검사 툴(Nanite Auditing Tool)이 나나이트를 활용할 수 있도록 기존 콘텐츠의 대량 이동을 보조하고, 지원되지 않는 기능이 활성화되는 것 처럼 개발 과정에서 깨지게 되는 나나이트 콘텐츠를 진단합니다.
버추얼 섀도 맵(베타)
버추얼 섀도 맵은 언리얼 엔진 5의 나나이트, 월드 파티션 기능을 활용해 차세대 다이내믹 섀도잉을 실시간으로 제공합니다. 영화 수준의 에셋과 대규모 오픈 월드를 지원하는 데 필요한 높은 퀄리티의 섀도를 일관되게 제공합니다.
기존 다이내믹 섀도잉 기법은 소규모 또는 중간 규모의 월드로 제한되는 경우가 많고 디자이너와 아티스트가 퍼포먼스를 위해 퀄리티를 희생해야 했습니다. 반면 버추얼 섀도 맵은 가장 필요한 곳의 퀄리티를 자동으로 높여 주는 단일 통합 섀도잉 메서드를 제공합니다. 이제 사실적이고 부드러운 반그림자 및 컨택트 하드닝을 통해 먼 거리에 걸쳐 작은 오브젝트 및 큰 오브젝트에 일관된 퀄리티의 섀도를 적용할 수 있습니다.
템포럴 슈퍼 해상도
나나이트 마이크로폴리곤 지오메트리와 차세대 게임의 퀄리티에 대한 기대로 화면에 표시할 수 있는 디테일이 그 어느 때보다 높아졌습니다. 이 기대감을 충족시키기 위해, 언리얼 엔진 4의 하이엔드 플랫폼용 템포럴 안티 에일리어싱(Temporal Anti-Aliasing, TAA)의 대안으로 템포럴 슈퍼 해상도 알고리즘을 새로 개발했습니다.
템포럴 슈퍼 해상도는 언리얼 엔진에 기본 내장되어 높은 퀄리티의 업샘플링을 제공하고 폭넓은 하드웨어를 지원합니다. 템포럴 슈퍼 해상도는 디폴트 안티 에일리어싱 메서드이며 모든 프로젝트에서 활성화되어 있습니다.
DirectX 12
이제 언리얼 엔진 5의 기능을 사용해 Windows PC의 RHI를 구현할 때는 Microsoft의 DirectX 12(DX12)를 권장합니다. 에픽에서는 엔진에서 DX12 지원을 강화하는 동안 메모리 관리, 기능 무결성, 안전성을 최우선으로 고려할 예정입니다. 언리얼 엔진 5에서 새로 생성한 프로젝트는 기본적으로 DX12를 사용합니다.
Vulkan
언리얼 엔진 5의 Vulkan RHI는 여러 번의 안정성 및 기능 업데이트를 통해 데스크톱 및 모바일에서의 효율이 향상되었습니다. Linux에 나나이트, 루멘(소프트웨어 레이 트레이싱 전용) 등 언리얼 엔진 5 기능이 지원됩니다.
새로운 액터당 한 개의 파일(One File Per Actor) 시스템은 월드 파티션과 함께 작동하여 대규모 월드에서 공동 편집을 더욱 쉽게 만들어 줍니다. 레벨 에디터는 개별 액터를 단일 모놀리식 레벨 파일로 그룹화하지 않고 자체적인 파일로 저장합니다. 즉, 전체 레벨이 아닌 소스 컨트롤에서 필요한 액터만 체크아웃하면 됩니다.
이제 대규모 월드 좌표(Large World Coordinates, LWC)가 언리얼 엔진 5에서 더블 정밀도 데이터 베리언트 타입을 지원합니다. 부동 소수점 정밀도를 향상하기 위해 UE5의 모든 엔진 시스템 전반에서 커다란 변화가 이루어졌습니다. 새로운 엔진 시스템에는 건축 시각화, 시뮬레이션, 렌더링(나이아가라 및 HLSL 코드), 대규모 월드 스케일 프로젝트 등이 있습니다. 대규모 월드 좌표를 UE의 모든 곳에서 실행하고 노출하도록 많은 개발 작업을 진행했지만, 원래 지점에서 멀리 떨어진 일부 시스템의 경우 아직 해결하지 않은 정밀도 문제 때문에 몇 가지 제한이 존재합니다.
라이선스 이용자는 코드를 바로 이 신규 데이터 타입으로 옮기기 시작할 수 있으나, 엔진의 전 시스템이 대규모에서도 지금처럼 효율적으로 작동하는지 확인한 후, 5.1 버전에서 대규모 월드에 대한 생성 및 배치를 정식으로 지원할 예정입니다. 이후 최대 월드 크기의 디폴트 값을 매우 큰 수치로 설정할 것입니다.
언리얼 엔진 4에서는 32비트 플로트 정밀도 타입으로 인해 월드의 크기가 제한되었습니다. LWC는 코어 데이터 타입으로 64비트 더블을 제공하여 프로젝트 크기를 크게 향상시킵니다. 이 변화로 대규모 월드를 구축할 수 있게 되었으며, 액터 배치 정확도 및 오리엔테이션 정밀도가 크게 향상되었습니다. 대규모 월드 좌표는 더블 타입을 사용하기 때문에,PhysX 피직스 시스템은 UE5와 호환되지 않습니다.
대규모 월드 실험에 관련된 자세한 정보는 대규모 월드 좌표 문서를 참조하세요.
PhysX 및 카오스 피직스 시스템
UE5는 피직스 시뮬레이션에 대해카오스 피직스엔진을 사용하며, 기본값인PhysX를 대체합니다. PhysX가 여전히 UE5에 있지만 향후 버전에서 제거될 예정입니다. 카오스 피직스의 피직스 시뮬레이션은 PhysX와 다르게 작동하며, 일관적인 물리 동작을 위해선 개발자의 조정이 필요합니다.
피직스 틱 속도는 기본적으로 새로 생성된 프로젝트에 따라 변경됩니다. 틱 속도 변화는 프로젝트 세팅(메뉴:수정(Edit) > 프로젝트 세팅(Project Settings) )내에 있는 틱 비동기 피직스에서 액세스할 수 있습니다. 이 신기능은 게임 스레드 대신 자체 스레드에서 피직스를 시뮬레이션합니다.
PhysX는 UE5에서 제거될 예정이나, 필요한 경우 PhysX가 활성화된 소스에서 컴파일할 수 있습니다.
게임플레이 프레임워크
제거
블루프린트 네이티브화(Blueprint Nativization)는 UE5에 없습니다. 이 기능을 활용한 프로젝트에는 변경사항이 없습니다. 성능에 영향을 미칠 수 있으나 적절하게 작동하려면 수정이 필요합니다. 이 경우 개발자는 다른 최적화 접근 방식을 수행해야 합니다.
네트워킹
지원 중단
AES, RSA, RSA 키 AES 암호화 핸들러(AES, RSA, and RSA Key AES Encryption Handler)는 UE5 5.0에서 지원 중단되고, UE5의 향후 버전에서 제거될 예정입니다. 현재는 DTLS만 사용됩니다.
AES GCM은 UE5 5.0 이전에는 사용되지만 UE5의 후속 릴리스에서는 제거됩니다. 사용자는 이 변경사항으로 인해 프로젝트를 수정할 필요가 없습니다.
코어
제거
젠 로더(Zen Loader)가이벤트 중심 로더(Event-Driven Loader)를 대체합니다. 대부분의 사용자는 이벤트 주도형 로더와 직접 접속하지 않으므로 이 변경사항에 따라 프로젝트 마이그레이션 도중 작업을 수행할 필요가 없습니다.
지원 중단
언리얼 인사이트(Unreal Insights)시스템은 UE5 5.0 정식 출시 이후통계 시스템(Stats System)을 대체합니다. 통계 시스템은 UE5 5.0에 계속 존재하지만 언리얼 인사이트를 위해 제거될 예정입니다.
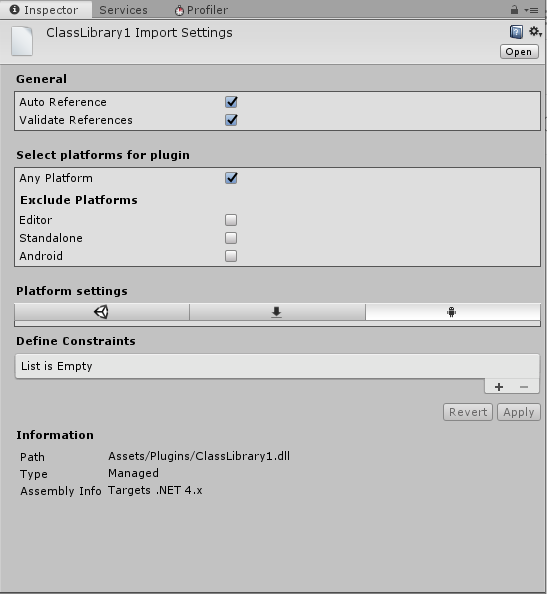
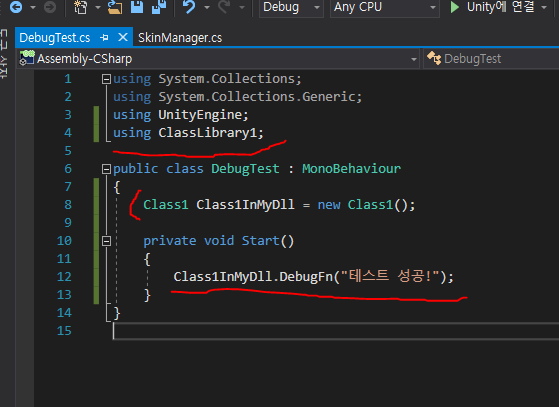
Namespace Photon.Pun missing + RoomSettings not found Realtime and Chat are available I'm using PUN 2 - Free Photon.Pun is only accessable when creating Scripts inside of Photon/PUN/Code
Someone has the same problem or know how to fix this?
RoomSettings is not a class or namespace in Photon code. You probably mean RoomOptions which is under Photon.Realtime.
Photon.Pun is only accessable when creating Scripts inside of Photon/PUN/Code

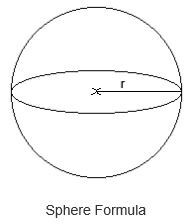
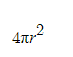
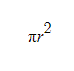
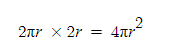





















 bssrdf.pdf
bssrdf.pdf