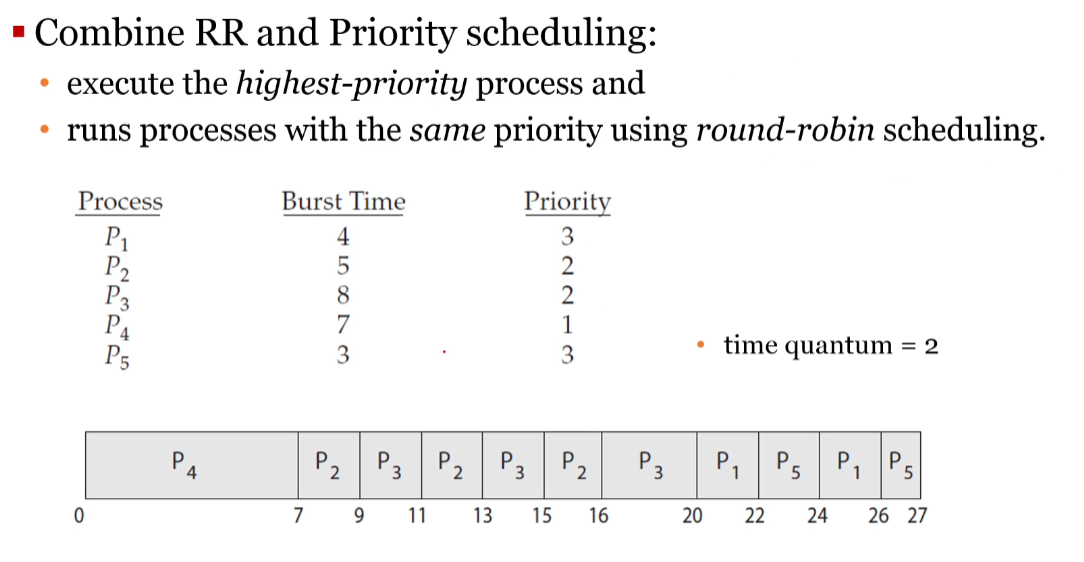
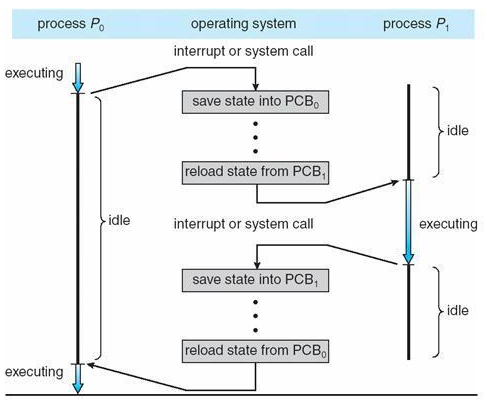
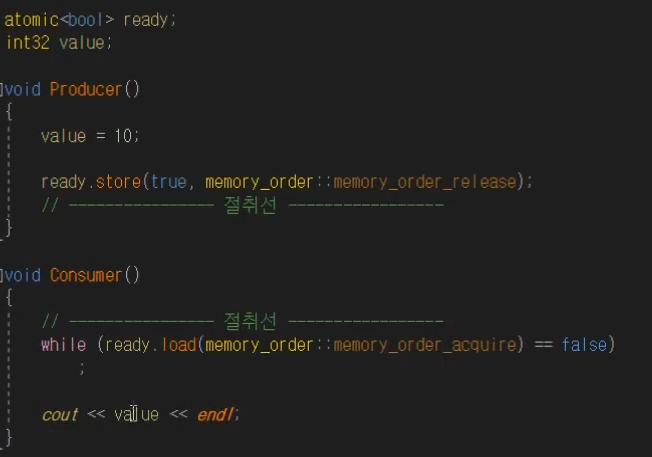
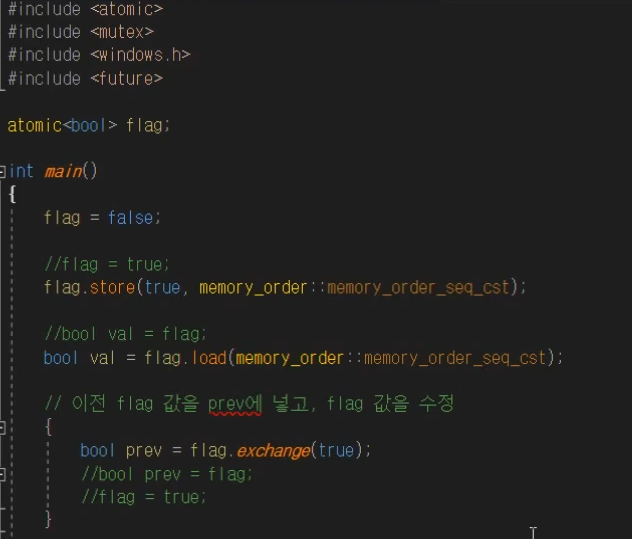
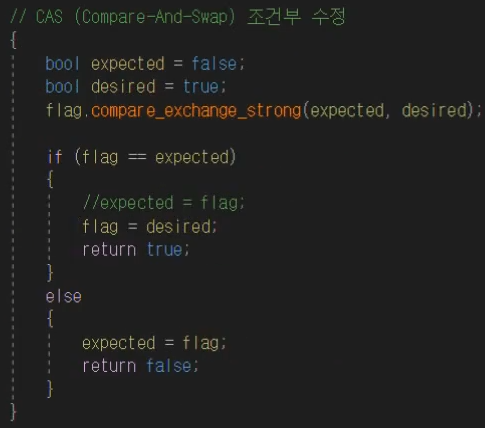
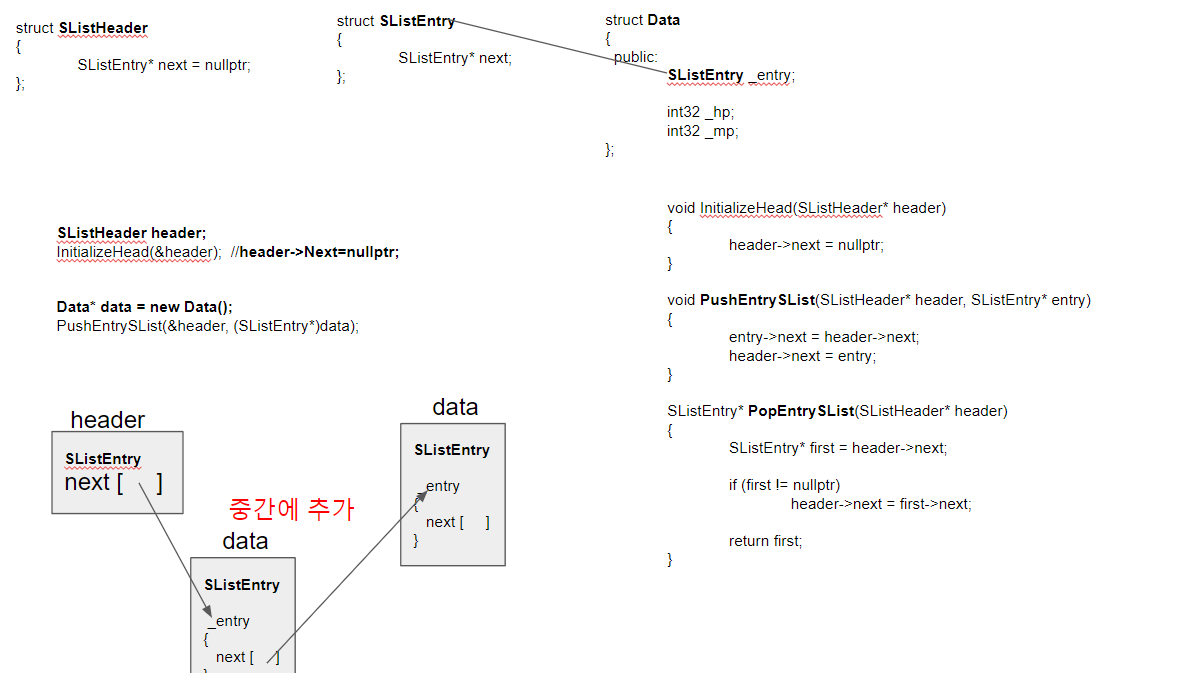
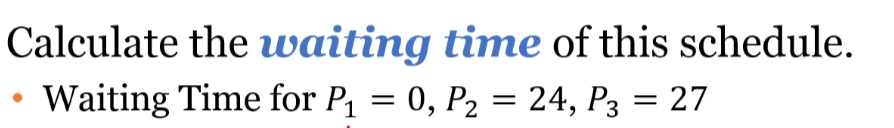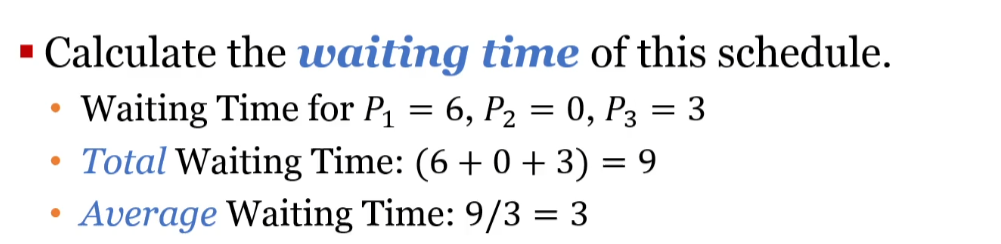Multithreading your game has the potential to massively increase performance. You are getting an entire new thread to work with, so you can offload heavy tasks to your worker thread while your game thread keeps running at a high framerate.
Getting started with multithreading is daunting, at least it was for me, so I'm writing this to help out any fellow devs who might be interested in using this for your own project.
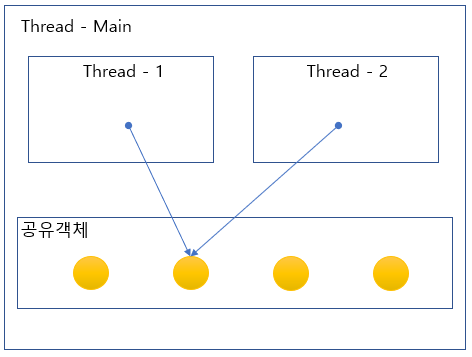
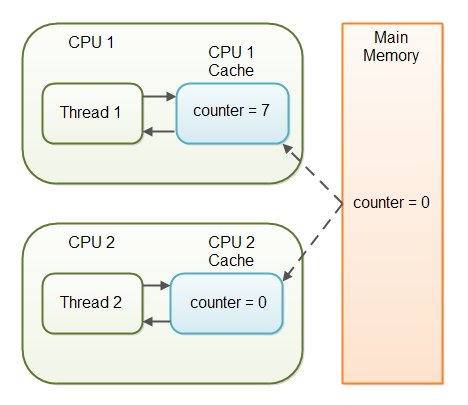
First off: is multithreading the right solution for you?The use case is quite limited, since there are a lot of things you can't do on the other thread. You can't read or write data that lives on your game thread, this includes modifying any UObjects. Doing so will result in undefined behavior - usually access violation errors.
So, what can you use it for? Think of it like an isolated part of your code, you can give it inputs, and then it will go off on it's own and calculate something only using the inputs you gave it. You can only (easily) multithread parts of your code that can be decoupled from the rest of the program.
For example, the way I used it was to calculate a custom lightmap using a recursive flood fill algorithm, the result is a dynamic 2D lightmap like the one in Terraria. First, the game thread prepares the data for the worker thread; it gets the details of every light on screen. Then, it gives the data to the worker thread, which performs the expensive calculations. Finally, the worker thread gives back the finished lightmap, and the cycle continues.
If you think your expensive task can be performed like this, you're in luck, because this guide will show you exactly how to implement it - without worrying about locking variables and mutexes.
Flip flop threading paradigm
I have no idea if that's a real paradigm, but that's what I'm going to call this system I created. This paradigm can be summarized by one video:
The game thread is the person flicking the switch, and the worker thread is the thing that switches it off. The switch itself is a boolean.
Basically, when the switch is off, the worker thread does nothing but check if the switch is on. This is when the game thread reads and writes to the worker thread. Once the game thread has finished, it flips the switch to on. When the worker thread sees that it's on, it will perform all of the calculations using the fresh data is received, and flips the switch off once it has finished.
Let's see how that looks in code.
First, let's lay out the foundations to get a FRunnable thread up and running. It won't do anything yet, other than log messages so we can see it working.
Header File
// Copyright notice
#pragma once
#include "CoreMinimal.h"
#include "HAL/Runnable.h"
/**
*
*/
class GAMENAME_API FMyWorker : public FRunnable
{
public:
// Constructor, create the thread by calling this
FMyWorker();
// Destructor
virtual ~FMyWorker() override;
// Overriden from FRunnable
// Do not call these functions youself, that will happen automatically
bool Init() override; // Do your setup here, allocate memory, ect.
uint32 Run() override; // Main data processing happens here
void Stop() override; // Clean up any memory you allocated here
private:
// Thread handle. Control the thread using this, with operators like Kill and Suspend
FRunnableThread* Thread;
// Used to know when the thread should exit, changed in Stop(), read in Run()
bool bRunThread;
};C++ File
// Copyright notice
#include "MyWorker.h" // Change this to reference the header file above
#pragma region Main Thread Code
// This code will be run on the thread that invoked this thread (i.e. game thread)
FMyWorker::FMyWorker(/* You can pass in inputs here */)
{
// Constructs the actual thread object. It will begin execution immediately
// If you've passed in any inputs, set them up before calling this.
Thread = FRunnableThread::Create(this, TEXT("Give your thread a good name"));
}
FMyWorker::~FMyWorker()
{
if (Thread)
{
// Kill() is a blocking call, it waits for the thread to finish.
// Hopefully that doesn't take too long
Thread->Kill();
delete Thread;
}
}
#pragma endregion
// The code below will run on the new thread.
bool FMyWorker::Init()
{
UE_LOG(LogTemp, Warning, TEXT("My custom thread has been initialized"))
// Return false if you want to abort the thread
return true;
}
uint32 FMyWorker::Run()
{
// Peform your processor intensive task here. In this example, a neverending
// task is created, which will only end when Stop is called.
while (bRunThread)
{
UE_LOG(LogTemp, Warning, TEXT("My custom thread is running!"))
FPlatformProcess::Sleep(1.0f);
}
return 0;
}
// This function is NOT run on the new thread!
void FMyWorker::Stop()
{
// Clean up memory usage here, and make sure the Run() function stops soon
// The main thread will be stopped until this finishes!
// For this example, we just need to terminate the while loop
// It will finish in <= 1 sec, due to the Sleep()
bRunThread = false;
}Creating and controlling the thread
This part is easy, just create an instance of the class above using regular C++:
The example is set up to run straight away, so if you want to pass it some data, you can either use the constructor, or move the Create() command to another function you can invoke when ready.
Remember to hold onto the pointer so you can delete it when no longer needed.
When finished, use the normal delete command:
When you've done this, you should have a new thread that announces when it has been created, and will print a message to the log every second. The code should be stable and crash free.
Implementing the Flip Flop
Now that we have a basic thread, we can give it more functionality.
We need to create the boolean that acts as the switch, and the loop that reads this bool.
It's fairly straightforward, here is the code you need to add:
Header File
class GAMENAME_API FMyWorker : public FRunnable
{
public:
[...]
// ----------
// The boolean that acts as the main switch
// When this is false, inputs and outputs can be safely read from game thread
bool bInputReady = false;
// Declare the variables that are the inputs and outputs here.
// You can have as many as you want. Remember not to use pointers, this must be
// plain old data
// For example:
int ExampleIntInput = 0;
float ExampleFloatOutput = 0.0f;
private:
[...]
};C++ File
uint32 FMyWorker::Run()
{
// Peform your processor intensive task here. In this example, a neverending
// task is created, which will only end when Stop is called.
while (bRunThread)
{
if (bInputReady)
{
// Do your intensive tasks here. You can safely modify all input variables.
// For the example, I'm just going to convert the input int to a float
ExampleFloatOutput = ExampleIntInput;
FPlatformProcess::Sleep(1.0f); // Simulate a heavy workload
// Do this once you've finished using the input/output variables
// From this point onwards, do not touch them!
bInputReady = false;
// I hear that it's good to let the thread sleep a bit, so the OS can utilise it better or something.
FPlatformProcess::Sleep(0.01f);
}
}
return 0;
}That's all you need on the thread side of things. To access it from the game thread, do something like this:
// You need a function like Tick. You can also use timers
void AMyClass::Tick(float DeltaTime)
{
if (Worker)
{
if (!Worker->bInputReady)
{
// Read and write the variables here
Worker->ExampleIntInput = 3141592;
UE_LOG(LogTemp, Warning, TEXT("Game thread: value gotten from worker thread: %f"), Worker->ExampleFloatOutput)
// Flick the switch to let the worker thread run
// Do not read/write variables from thread from here on!
Worker->bInputReady = true;
}
}
}Note: the variable Worker needs to be initialized before, like in BeginPlay(). Scroll up a bit to see how to initialize it.
ref : https://unrealcommunity.wiki/multithreading-with-frunnable-2a4xuf68
'운영체제 & 병렬처리 > Multithread' 카테고리의 다른 글
| Walkthrough: Debug a multithreaded app using the Threads window (0) | 2023.01.12 |
|---|---|
| How to: Flag and Unflag Threads (0) | 2023.01.12 |
| atomic 과 가시성, 메모리 재배치의 해결 (0) | 2022.11.27 |
| MemoryPool 4 : 기존 메모리풀을 MS 로 변경 (0) | 2022.10.13 |
| MemoryPool 3 (MS-lock-free stack, ABA 문제 해결방안 128bit) (0) | 2022.10.13 |