언리얼 에서 델리게이트는 C++ 객체에만 사용할 수 있는 델리게이트와 C++, 블루프린트 객체가 모두 사용할 수 있는 델리게이트로 나뉜다. 블루프린트 오브젝트는 멤버 함수에 대한 정보를 저장하고 로딩하는 직렬화 매커니즘이 들어있기 때문에 일반 C++ 언어가 관리하는 방법으로 멤버 함수를 관리 할수 없다.
그래서 블루프린트와 관련된 C++함수는 모두 UFUNCTION 매크로를 사용해야 한다.
이렇게 블루프린트 객체와도 연동하는 델리게이트를 언리얼 엔진에서는 다이내믹 델리게이트라고 한다.
Delegate란?
함수를 바인딩하는 형태로 등록시켜 CallBack함수와 같이 활용 할 수 있습니다.

언리얼 C++에서 충돌감지 컴포넌트 개열에서 AddDynamic 메크로를 통해 출돌시 등록한 CallBack함수를 호출하는 것이 구현 되어 있습니다.
언리얼 C++에는 총 4가지 종류의 Delegate가 있습니다.
| 델리게이트(싱글 케스트) | 가장 기본적인 Delegate로 함수 1개를 바인드하여 사용합니다. |
| 멀티 케스트 | 싱글 케스트와 동일하지만 여러 함수를 바인드 할 수 있습니다. |
| 이벤트 | 멀티 케스트와 동일하지만 전역으로 설정할 수 없어 외부 클래스에서 추가 델리게이트 선언이 불가능합니다. |
| 다이나믹 멀티케스트(다이나믹) | 다이나믹은 싱글과, 멀티 두개다 존재하며 다이나믹 델리게이트는 직렬화(Serialize)화 되어 블루프린트에서 사용 가능합니다. |
바인딩(Bind)란 Delegate에 특정 바인드 함수를 통해 콜백함수를 등록하는 것을 의미합니다.

공식문서에는 여러 형태의 바인드함수가 있지만 이 포스팅에서는 함수 바인딩을 중심적으로 설명하겠습니다.
샘플 프로젝트 소개
샘플 프로젝트는 포스팅 상단에 업로드했습니다.

샘플 프로젝트는 폭탄 오브젝트가 하나 있으며 키보드 "B"키는 누르면 점화되어 3초 뒤에 폭발합니다.
프로젝트의 구현 형태는 폭탄 클래스에다 함수들을 바인드시켜놓고 폭탄이 터지면 바인드한 함수들을 호출하여
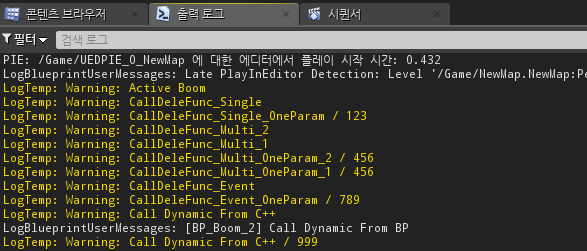
출력 로그에 해당 함수 내에서 로그 코드가 발동되게 구현했습니다.
기본적인 Delegate 세팅법은 먼저 싱글케스트를 예시로 먼저 설명하겠습니다.
헤더 파일 설명
//! ABoom.h
#include "Boom.generated.h"
//! SingleCast
DECLARE_DELEGATE(FDele_Single);
DECLARE_DELEGATE_OneParam(FDele_Single_OneParam, int32);
UCLASS()
class DELEGATETEST_API ABoom : public AActor
{
GENERATED_BODY()
........
public :
FDele_Single Fuc_DeleSingle;
FDele_Single_OneParam Fuc_DeleSingle_OneParam;
};
헤더 파일에서 Delegate함수를 만들고 DECLARE_DELEGATE()메크로를 통해 델리게이트화 시킵니다.
DECLARE_DELEGATE는 인자 값 없는 함수에 사용하고 DECLARE_DELEGATE_OneParam는 1개의 인자값이 있는 함수에 사용합니다, 만약 인자 값이 2개면 TwoParam을 사용합니다.
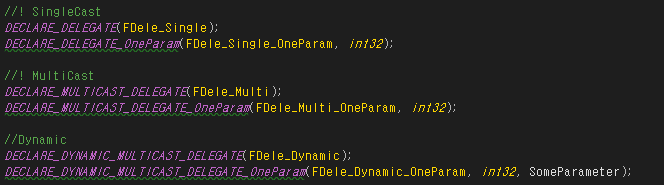
델리게이트는 자료형 이름 앞에 "F"를 붙여야합니다.

안 그러면 위 에러가 뜨게 됩니다.
Cpp 파일 설명
//! ABoom.cpp
void ABoom::EndPlay(const EEndPlayReason::Type EndPlayReason)
{
Super::EndPlay(EndPlayReason);
//! 델리게이트 해제
Fuc_DeleSingle.Unbind();
Fuc_DeleSingle_OneParam.Unbind();
}
void ABoom::Tick_Boom(float DeltaTime)
{
//! Delegate호출하는 부분
if(Fuc_DeleSingle.IsBound()==true) Fuc_DeleSingle.Execute();
if(Fuc_DeleSingle_OneParam.IsBound() == true) Fuc_DeleSingle_OneParam.Execute(123);
}

EndPlay함수에 Unbind()함수는 일종의 메모리 해제 함수입니다, 해당 델리게이트에 바인드된 함수를 제거합니다.

실제 델리게이트에 등록된 Callback 함수를 호출하는 부분입니다.
IsBound()를 통해 바인드가 되어있는지 확인하고 리턴값이 True이면 Execute()함수를 통해 호출합니다.
인자 값이 있는 함수는 Execute함수의 인자 값으로 입력합니다.
Delegate에 함수 등록 & 싱글케스트(Single cast)
이 챕터는 Delegate가 세팅된 ABoom 클래스에 ATestPlayer클래스의 함수를 등록하는 과정입니다.
//! ATestPlayer.h
UCLASS()
class DELEGATETEST_API ATestPlayer : public AActor
{
GENERATED_BODY()
public:
//! Delegate에 의해 호출될 함수
UFUNCTION()
void CallDeleFunc_Single();
UFUNCTION()
void CallDeleFunc_Single_OneParam(int32 nValue);
먼저 ABoom클래스에 등록할 함수는 인자값에 맞춰 함수를 만듭니다.
Delegate에 등록할 함수는 UFUNCTION()메크로를 붙여야 합니다.
//! ATestPlayer.cpp
//! Delegate에 의해 호출될 함수
void ATestPlayer::CallDeleFunc_Single()
{
UE_LOG(LogTemp, Warning, TEXT("CallDeleFunc_Single"));
}
void ATestPlayer::CallDeleFunc_Single_OneParam(int32 nValue)
{
UE_LOG(LogTemp, Warning, TEXT("CallDeleFunc_Single_OneParam / %d"), nValue);
}해당 함수에 단순하게 로그를 출력하는 코드를 작성했습니다.
//! ATestPlayer.cpp
void ATestPlayer::BeginPlay()
{
m_pBoom->Fuc_DeleSingle.BindUFunction(this, FName("CallDeleFunc_Single"));
m_pBoom->Fuc_DeleSingle_OneParam.BindUFunction(this, FName("CallDeleFunc_Single_OneParam"));
}함수를 바인드하는 코드입니다, ABoom.h에서 만든 Delegate 변수에 접근하여 함수를 바인드하는 함수를 통해 함수를 등록합니다.
이로서 Delegate의 기본 형태인 싱글케스트 구현이 완료됬으며, 폭탄이 터지면 로그가 출력될 것입니다.

멀티 케스트(Multi cast)
멀티케스트가 델리게이트(싱글케스트)와 차이점은 함수를 여러개 바인드 할 수 있습니다.
//! ABoom.h
//! MultiCast
DECLARE_MULTICAST_DELEGATE(FDele_Multi);
DECLARE_MULTICAST_DELEGATE_OneParam(FDele_Multi_OneParam, int32);
UCLASS()
class DELEGATETEST_API ABoom : public AActor
{
GENERATED_BODY()
public :
FDele_Multi Fuc_DeleMulti;
FDele_Multi_OneParam Fuc_DeleMulti_OneParam;
};멀티 케스트는 싱글케스트와 비슷하게 헤더파일에서 작성됩니다.
//! ABoom.cpp
void ABoom::EndPlay(const EEndPlayReason::Type EndPlayReason)
{
Super::EndPlay(EndPlayReason);
//! 델리게이트 해제
Fuc_DeleMulti.Clear();
Fuc_DeleMulti_OneParam.Clear();
}
void ABoom::Tick_Boom(float DeltaTime)
{
if(Fuc_DeleMulti.IsBound() == true) Fuc_DeleMulti.Broadcast();
if(Fuc_DeleMulti_OneParam.IsBound() == true) Fuc_DeleMulti_OneParam.Broadcast(456);
}cpp파일입니다.

싱글케스트와 차이점은 Unbind가 Clear로 되고 Execute가 Broadcast로 바뀌었습니다.
//! ATestPlayer.cpp
void ATestPlayer::BeginPlay()
{
Super::BeginPlay();
//! SingleCast
m_pBoom->Fuc_DeleSingle.BindUFunction(this, FName("CallDeleFunc_Single"));
m_pBoom->Fuc_DeleSingle_OneParam.BindUFunction(this, FName("CallDeleFunc_Single_OneParam"));
//! MultiCast
m_pBoom->Fuc_DeleMulti.AddUFunction(this, FName("CallDeleFunc_Multi_1"));
m_pBoom->Fuc_DeleMulti.AddUFunction(this, FName("CallDeleFunc_Multi_2"));
m_pBoom->Fuc_DeleMulti_OneParam.AddUFunction(this, FName("CallDeleFunc_Multi_OneParam_1"));
m_pBoom->Fuc_DeleMulti_OneParam.AddUFunction(this, FName("CallDeleFunc_Multi_OneParam_2"));함수를 등록하는 부분입니다, 싱글케스트와 쓰임세는 비슷하지만 함수는 BindUFunction->AddUFunction으로 변경되었습니다.

결과를 확인하면 폭탄이 터질때 해당 델리게이트에 .BroadCast()함수를 한번 호출하면 안에 등록된 모든 함수가 호출이 되는 것을 확인 할 수 있습니다.
없으면 아무것도 실행 안됨
이벤트(Event)
이벤트는 멀티 케스트와 유사하지만 전역으로 설정할 수 없어 외부 클래스에서 추가 델리게이트 선언이 불가능합니다.
캡슐화 개념으로 사용하면 될것 같습니다.
//! ABoom.h
UCLASS()
class DELEGATETEST_API ABoom : public AActor
{
GENERATED_BODY()
public :
//! Event
DECLARE_EVENT(ABoom, FDele_Event);
DECLARE_EVENT_OneParam(ABoom, FDele_Event_OneParam, int32);
public :
FDele_Event Fuc_DeleEvent;
FDele_Event_OneParam Fuc_DeleEvent_OneParam;
전역에 작성했던 이전 Delegate와 달리 Event는 클래스 내부에 작성하고 인자값으로 주인클래스의 클래스를 입력합니다.
이외에는 이전 멀티케스트와 사용법이 동일합니다.
다이나믹 멀티캐스트 (다이나믹(Dynamic))
다이나믹 델리게이트는 직렬화(Serialize)화 되어 블루프린트에서 사용 가능합니다.
//! ABoom.h
//Dynamic
DECLARE_DYNAMIC_MULTICAST_DELEGATE(FDele_Dynamic);
DECLARE_DYNAMIC_MULTICAST_DELEGATE_OneParam(FDele_Dynamic_OneParam, int32, SomeParameter);
UCLASS()
class DELEGATETEST_API ABoom : public AActor
{
GENERATED_BODY()
public :
UPROPERTY(BlueprintAssignable, VisibleAnywhere, BlueprintCallable, Category = "Event")
FDele_Dynamic Fuc_Dynamic;
UPROPERTY(BlueprintAssignable, VisibleAnywhere, BlueprintCallable, Category = "Event")
FDele_Dynamic_OneParam Fuc_Dynamic_OneParam;이전 델리게이트와 비슷하지만 변수 작성부분에서 BlueprintAssignable 등 UPROPERTY 메크로를 작성합니다.
해당 포스팅에서는 DYNAMIC_MULTICAST만 사용했습니다,
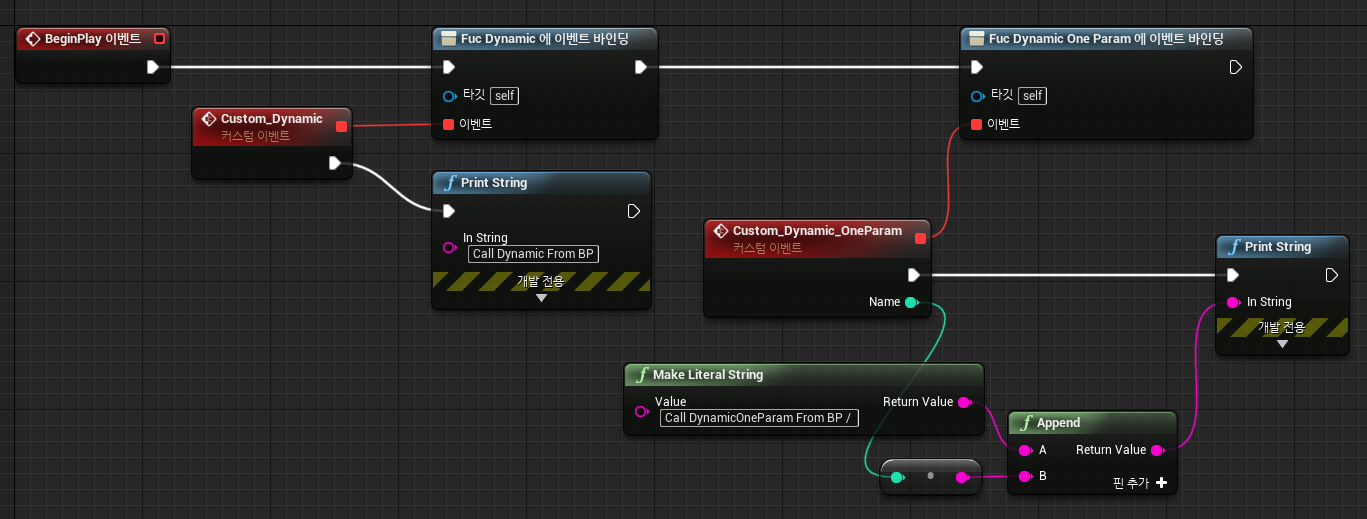
다이나믹 델리게이트는 직렬화(Serialize)화가 가능하고 UPROPERTY 메크로를 통해서 블루프린트에서 델리게이트 바인드가 가능합니다.
이 기능은 블루프린트 디스패처랑 비슷하게 사용이 가능합니다.

그리고 Cpp에서는 이전 멀티케스트와 동일하게 사용합니다.
//! ATestPlayer.cpp
void ATestPlayer::BeginPlay()
{
Super::BeginPlay();
m_pBoom->Fuc_Dynamic.AddDynamic(this, &ATestPlayer::CallDeleFunc_Dynamic);
m_pBoom->Fuc_Dynamic_OneParam.AddDynamic(this, &ATestPlayer::CallDeleFunc_Dynamic_OneParam);다이나믹 델리게이트는 이전과는 다르게 위 .AddDynamic 메크로함수로 바인드를 합니다.

폭탄이 터지고 로그를 확인하면 블루프린트에서 바인드한 Custom함수와, C++에서 바인드한 함수가 동시에 호출되는 것을 확인 할 수 있습니다.
핵심 코드
1. 델리게이트 세팅
//! SingleCast
DECLARE_DELEGATE(FDele_Single);
DECLARE_DELEGATE_OneParam(FDele_Single_OneParam, int32);
//! MultiCast
DECLARE_MULTICAST_DELEGATE(FDele_Multi);
DECLARE_MULTICAST_DELEGATE_OneParam(FDele_Multi_OneParam, int32);
//Dynamic
DECLARE_DYNAMIC_MULTICAST_DELEGATE(FDele_Dynamic);
DECLARE_DYNAMIC_MULTICAST_DELEGATE_OneParam(FDele_Dynamic_OneParam, int32, SomeParameter);
UCLASS()
class DELEGATETEST_API ABoom : public AActor
{
GENERATED_BODY()
public :
//! Event
DECLARE_EVENT(ABoom, FDele_Event);
DECLARE_EVENT_OneParam(ABoom, FDele_Event_OneParam, int32);
//---------------------------------------------------------------------
public :
FDele_Single Fuc_DeleSingle;
FDele_Single_OneParam Fuc_DeleSingle_OneParam;
FDele_Multi Fuc_DeleMulti;
FDele_Multi_OneParam Fuc_DeleMulti_OneParam;
FDele_Event Fuc_DeleEvent;
FDele_Event_OneParam Fuc_DeleEvent_OneParam;
UPROPERTY(BlueprintAssignable, VisibleAnywhere, BlueprintCallable, Category = "Event")
FDele_Dynamic Fuc_Dynamic;
UPROPERTY(BlueprintAssignable, VisibleAnywhere, BlueprintCallable, Category = "Event")
FDele_Dynamic_OneParam Fuc_Dynamic_OneParam;
2. 델리게이트에 바인드된 함수 호출 & 해제
void ABoom::EndPlay(const EEndPlayReason::Type EndPlayReason)
{
Super::EndPlay(EndPlayReason);
//! 델리게이트 해제
Fuc_DeleSingle.Unbind();
Fuc_DeleSingle_OneParam.Unbind();
Fuc_DeleMulti.Clear();
Fuc_DeleMulti_OneParam.Clear();
Fuc_DeleEvent.Clear();
Fuc_DeleEvent_OneParam.Clear();
Fuc_Dynamic.Clear();
Fuc_Dynamic_OneParam.Clear();
}
void ABoom::Tick_Boom(float DeltaTime)
{
//! Delegate호출하는 부분
if(Fuc_DeleSingle.IsBound()==true) Fuc_DeleSingle.Execute();
if(Fuc_DeleSingle_OneParam.IsBound() == true) Fuc_DeleSingle_OneParam.Execute(123);
if(Fuc_DeleMulti.IsBound() == true) Fuc_DeleMulti.Broadcast();
if(Fuc_DeleMulti_OneParam.IsBound() == true) Fuc_DeleMulti_OneParam.Broadcast(456);
if(Fuc_DeleEvent.IsBound() == true) Fuc_DeleEvent.Broadcast();
if(Fuc_DeleEvent_OneParam.IsBound() == true) Fuc_DeleEvent_OneParam.Broadcast(789);
if (Fuc_Dynamic.IsBound() == true) Fuc_Dynamic.Broadcast();
if (Fuc_Dynamic_OneParam.IsBound() == true) Fuc_Dynamic_OneParam.Broadcast(999);
}
3. 델리게이트 함수 바인드
void ATestPlayer::BeginPlay()
{
Super::BeginPlay();
//! Delegate 등록하기
if (m_pBoom != nullptr)
{
m_pBoom->Fuc_DeleSingle.BindUFunction(this, FName("CallDeleFunc_Single"));
m_pBoom->Fuc_DeleSingle_OneParam.BindUFunction(this, FName("CallDeleFunc_Single_OneParam"));
m_pBoom->Fuc_DeleMulti.AddUFunction(this, FName("CallDeleFunc_Multi_1"));
m_pBoom->Fuc_DeleMulti.AddUFunction(this, FName("CallDeleFunc_Multi_2"));
m_pBoom->Fuc_DeleMulti_OneParam.AddUFunction(this, FName("CallDeleFunc_Multi_OneParam_1"));
m_pBoom->Fuc_DeleMulti_OneParam.AddUFunction(this, FName("CallDeleFunc_Multi_OneParam_2"));
m_pBoom->Fuc_DeleEvent.AddUFunction(this, FName("CallDeleFunc_Event"));
m_pBoom->Fuc_DeleEvent_OneParam.AddUFunction(this, FName("CallDeleFunc_Event_OneParam"));
m_pBoom->Fuc_Dynamic.AddDynamic(this, &ATestPlayer::CallDeleFunc_Dynamic);
m_pBoom->Fuc_Dynamic_OneParam.AddDynamic(this, &ATestPlayer::CallDeleFunc_Dynamic_OneParam);
}
}
'게임엔진(GameEngine) > Unreal4' 카테고리의 다른 글
| 리플렉션 (0) | 2023.03.07 |
|---|---|
| Damage in Unreal Engine 1: Introduction (Instigator, Causer) (0) | 2023.03.05 |
| 애니메이션 디스턴스매칭 (0) | 2023.02.20 |
| TSharedPtr<.... , ESPMode::ThreadSafe> 스레드 안정성 (0) | 2023.01.20 |
| Widget for painting (0) | 2022.11.23 |