

이글을 읽기 위해서 이 글들에 대한 선행 이해가 필요합니다
https://3dmpengines.tistory.com/2210?category=511467
LockFree - Stack (1)
경우의 수는 이것보다 훨씬 많을 수 있지만 몇개만 추려보았고 크래쉬기 나지 않고 Lock free를 시도 하려는 중간 과정이라 보면 되겠다 스택이기 때문에 끝에서 추가되고 삭제 된다는것과 다른
3dmpengines.tistory.com
https://3dmpengines.tistory.com/2212?category=511467
LockFree - Stack (2) - 삭제 처리
삭제의 핵심은 분리를 미리하고 분리한 대상을 현재 스레드의 스택 메모리에 삭제할 주소를 지역변수로 들고 있다가 다시 자신의 스레드로 돌아왔을때 분리된 삭제할 메모리를 그때서야 삭제
3dmpengines.tistory.com
[Queue] 컨셉
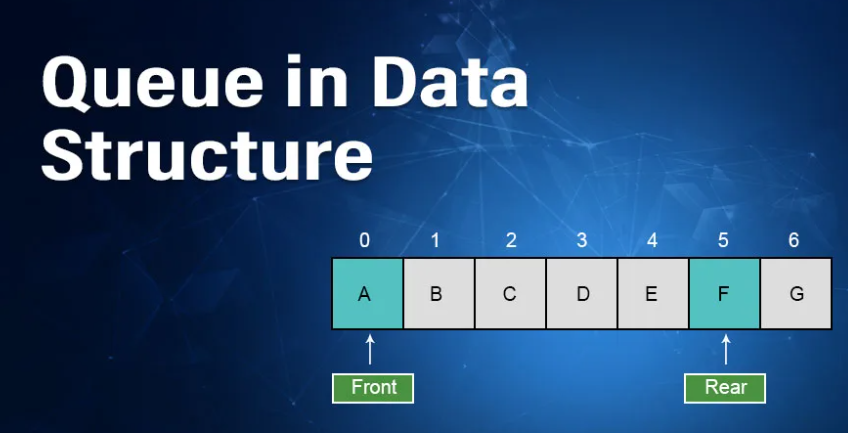
기본 적인 Queue 의 컨셉은
[data][data][value][dummy]
[head][tail]
head 와 tail 이 있고 추가는 tail 에서 추가를 하며
제거는 head 에서 처리한다
그런데 최초에는
[dummy]
[head][tail]
아무것도 빈 노드가 아닌

최초에 head 와 tail 은 dummy 노드를 가리키고 있는 상태에서 시작된다
push 노드에 추가 할떄는 dummy 에 데이터를 넣고 그다음 tail의 next 노드에
새로운 더미를 만들어 추가해 나가는 방식이다
제거 반대로 head 에서 제거 해 나가는 방식
[Lock-Free Queue]
- lock free stack 과 동일하게 노드는 shared_ptr 로 구현하지 않는다 ref count 는 수동으로 구현, shared_ptr 자체가 lock free 가 아님으로
- Non blocking thread 는 여러 쓰레드에서 공용이 되는 데이터를 쓸려고 할때 atomic compare-and-swap (CAS) 로 연산을 해서 다른 스레드에 영향을 주지 않고 한방에 연산 처리 하는부분이 중요하다
- 그런 부분들에서 문제가 생길 수 있기 때문에 경합 지점이 있는 부분에선 CAS 함수인 atomic.compare_exchange_strong 함수로 해결을 해야한다 (atomic 은 가시성, 원자성 해결)
- 그리고 아무도 참조 하고 있지 않은 데이터를 shared_ptr 을 사용하는건 아니지만 ref count를 수동으로 구현하였기에 이 수치가 0이 되면 Node 를 제거하는 방식으로 처리가 되어 있다
- push 쪽은 여러 스래드가 동시에 실행된다 가정 했을 때 참조권을 먼저 획득하고 그다음 실제 노드에 대한 소유권을 획득한 스레드가 tail 에 새로운 dummy 노드를 추가하여 노드를 연결해 나가는 방식으로 진행 된다
- 찰나의 순간에 추가된 노드가 바로 삭제될 수도 있기에 그 부분을 위한 처리가 필요하다
[설명] Push
* 큐이다 보니 head 오 tail 이 있고 head 와 tail 사이에 데이터를 넣는 방식
* 데이터를 넣을때는 tail 즉 data 의 끝에 추가하고
* 빼올때는 head 데이터의 제일 앞에서 빼온다
[data][data][value][]
[head][tail]
그런데 최초에 head 와 tail 은 dummy [] 노드를 가르키는 방식으로 처리한다
그래서 head 와 tail 이 같은 노드를 가리키고 있다면 비어 있는 것으로 판단할 것이다
[]
[head][tail]
void Push(const T& value)
{
문제는 head 에서 삭제를 하고 tail 쪽에서 양쪽에서는 삭제를 하기 때문에 양쪽에서 변화가 생길 수 있다는 것
좀더 정확히는 tryPop 에서 삭제 하는건 맞는데 push 에서 찰나의 순간때문에 push 된 데이터가 바로 삭제 되는 경우가 발생 할수 있기에 push 에도 삭제 가능성이 있는 로직이 들어가게 된다 (설명은 이후에..)
먼저 tail 쪽 먼저 보자..
새로운 데이터를 준비한다
unique_ptr<T> newData = make_unique<T>(value);
CountedNodePtr dummy;
dummy.ptr = new Node;
dummy.externalCount = 1;
최초에 _tail 을 가져오긴 하지만
최초의 _tail 은 dummy node 이다
CountedNodePtr oldTail = _tail.load();
queue 방식이 tail 에다가 계속 추가하는 방식이라 dummy 이기도함
oldTail 변수는 스레드별로 별도로 존재 (스택에 존재하는 변수 임으로)
while (true)
{
[참조권 획득 과정]
참조권 획득 => externalCount를 현시점 기준 +1 한 스레드가 참조권을 획득한다
현재 스레드는 IncreaseExternalCount 함수 내에서 참조 권을 획득하지 못하면 획득 할때까지
참조권을 획득하기 위해서 루프를 돌며 반복 시도 함
IncreaseExternalCount(_tail, oldTail);
=> 결국 여기선 참조권을 획득한 스레드가 내려옴, 하지만 데이터에 대한 소육권은 아님
하지만 간발의 차이로 두 스레드가 참조권을 획득 할 수도 있다는 로직상 가정을 해야 한다
// 소유권 획득 (data를 먼저를 교환한 애가 이김)
T* oldData = nullptr;
여기서 가정을 하면서 본다
=>모든 스레드가 T* oldData = nullptr; 까지 실행 됐다는 가정 하에..
하단 로직에서 현재 스레드는 data 가 null 이면 if 안을 실행하겠지만
다른 스레드들에선
oldTail.ptr->data 가 아직 null 이라면 if 문에서 _tail 의 ptr->data 가 null 이 안되어 다른 스레드가
if 문 안쪽으로 실행 되지 못하고 if 문을 벗어나서 루프를 돌게 된다
* tail은 새로운 dummy 가 되기 전까지 oldTail 각 스레드별도의 스텍 상에 있는것이기 때문에
다른 스레드는 oldTail = _tail.exchange(dummy); 이 실행 되기 전까지 계속 이전과 동일한 노드를 가리키게 되어 => 위에서의 변화 가능성이 있지만 우선 이런 경우라 가정
현 스래드의 oldTail.ptr->data 이 뀌어서 newData.get() 가 들어갔다면
다른 스레드에서는 oldTail.ptr->data은 null 이 안되게 된다
//oldTail = _tail.exchange(dummy); 이 실행 된 이후 IncreaseExternalCount(_tail, oldTail); 이 함수가 다시 실행 되면서
// 다른 스레드들의 oldTail 이 dummy 를 가리키기 전까지 계속 while 을 돌게 된다
[소유권 획득 과정]
oldTail 은 dummy 라 데이터를 넣어주는 시도를 먼저 함, 데이터를 넣지 못한 다른 스레드는 이 if 를 건너 뛰게 됨
성공하면 데이터를 먼저 새로운 dummy 노드인 oldTail.ptr->data 포인터가 새로운 데이터를 가리키게함
if (oldTail.ptr->data.compare_exchange_strong(oldData, newData.get()))
{
여기에 들어오게 되면 실제 소유권을 획득하게 된것, 다른 스레드는 data 가 null 이 아니기 때문에 못들어옴
oldTail.ptr->next = dummy;
tip : exchange() 리턴은 바뀌기전 _tail 값을 리턴한다
oldTail = _tail.exchange(dummy); //_tail을 새로운 dummy 로 바꿔준다, 함수 실행 후 oldTail 은 이전 _tail 값이 된다
//이렇게 호출을 하게 되면 IncreaseExternalCount(_tail, oldTail); 새로운노드가 추가 됐어도 에서의 _tail 은 현재 것이 되고 oldTail 은 마찬가지로 이전것이 된다
데이터를 바꾸고 다음 노드를 세팅하게 되면 externalCount를 원상태로 돌려줌 => 감소 처리해서 메모리를 삭제해야 된다는 뜻
그런데 push 에서도 삭제가 있는것인데 push 가 완료 되기 전 찰나에 pop 이 실행되어 노드를 삭제해야 하는 상황에 발생 할수 있는데,
정리하자면 나의 순간에 pop 이 push 보다 먼저 돌게 되면 push 에서는 노드가 없기 때문에 push 처리 도중 문제가 생길 수 있어서 push 완료 된다음 삭제를 하기 위해 externalCountRemaining 이걸로 지워도 되는지 판단하고
문제가 없다면 push 에서도 삭제하게끔 처리를 해주기 위해 push 에서도 삭제가 들어가게 된다
FreeExternalCount(oldTail); //externalCount 를 줄여는 함수
newData.release(); //해제없이 소유권을 놓기만 함, 나중에 delete 는 알아서 해줘야 함
break;
}
[소유권 경쟁 실패]
현재 스레드에서 소유권까지 획득한 다음 자기자신 외에 동시에 실행되는 스레드 개수 만큼
새로운 dummy 로 바뀌기전의 _tail의 internalCount 가 올라 가는데
즉 현재 스레드 외에 나머지 스레드에선 소유권을 획득하지 못하였음으로 internalCount 의 값을 1 씩 낮춰준다, 마지막 internalCount == 0이 되는 스레드에서 삭제 처리를 한다
oldTail.ptr->ReleaseRef();
}
}
[설명] TryPop
// [data][data][ ]
// [head][tail]
shared_ptr<T> TryPop()
{
CountedNodePtr oldHead = _head.load();
while (true)
{
[참조권 획득 과정]
(externalCount를 현시점 기준 +1 한 애가 이김), push 와 동일
//push 에서 _tail 은 같은 곳을 바로보고 있긴 하지만 oldTail 이 지역변수를 통해 별도의 externalCount를 우선 유지한다
// [data][data][ ]
// [head][tail]
//
복습 및 정리 차원에서 써놓음
push 할때 노드가 tail 스레드에서 externalCount를 증가 시켜도 IncreaseExternalCount 의 함수에서 data 노드쪽의 externalCount를 증가시켜야 적요 되는것임으로 head 쪽의 externalCount 이 바로 적용 되는것은 아니다
그리고 만약 서로 같은 노드를 head, tail 이 두개가 같은 노드를 가리킨다 할지라도 externalCountRemaining 이 값을 통해 지워도 되는지를 한번더 판단하게 되어 push 작업이 마무리 되기 전 먼저 삭제 처리 하는 것을 막게 되기도 한다
//IncreaseExternalCount 이 함수내에서 실제 적용 된것이 참조권을 갖는다
IncreaseExternalCount(_head, oldHead);
Node* ptr = oldHead.ptr;
//[dummy]
//[head][tail]
이 부분은 쉽게 최초의 경우를 생각해보면 head와 tail 은 같은 dummy 를 가리키고 있음으로
둘다 같은 곳을 가리킬때에는 삭제 처리 할것이 없다 이럴때는 리턴하고 종료처리하는 부분
if (ptr == _tail.load().ptr)
{
ptr->ReleaseRef();
return shared_ptr<T>();
}
여기까지 실행 됐다면 참조권은 획득한 상태
[소유권 획득 과정]
//(head = ptr->next)
if (_head.compare_exchange_strong(oldHead, ptr->next))
{
소유권이 획득 되면 리턴해서 pop 스레드 종료처리 해버림
여러 스레드가 돌아간다는 것을 상기하고자 하는 차원에서 적자면
=> 어차피 pop 하는 거라 현대 스레드에서 종료 해도
다른 스레드에서 pop 이 돌고 있다고해도 다른 다른 스레드의 pop 들은 이 if 문들을 들어오지 않는 이상 계속 돌고 있음
데이터를 리턴했으면 pop 스레드 역할은 다 한것임으로 리턴처리 한다
//data 포인터를 얻어온다
T* res = ptr->data.load(); // exchange(nullptr); 로 하면 버그 있음!
FreeExternalCount(oldHead); //externalCount 를 줄여는 함수
return shared_ptr<T>(res);
}
ptr->ReleaseRef();
}
}
LockFreeQueue 코드...
#pragma once
#include <mutex>
template<typename T>
class LockFreeQueue
{
struct Node;
struct CountedNodePtr
{
int32 externalCount; // 참조권
Node* ptr = nullptr;
};
struct NodeCounter
{
uint32 internalCount : 30; // 참조권 반환 관련
uint32 externalCountRemaining : 2; // Push & Pop 다중 참조권 관련
};
struct Node
{
Node()
{
NodeCounter newCount;
newCount.internalCount = 0;
newCount.externalCountRemaining = 2;
count.store(newCount);
next.ptr = nullptr;
next.externalCount = 0;
}
void ReleaseRef()
{
NodeCounter oldCounter = count.load();
while (true)
{
NodeCounter newCounter = oldCounter;
newCounter.internalCount--;
// 끼어들 수 있음
if (count.compare_exchange_strong(oldCounter, newCounter))
{
if (newCounter.internalCount == 0 && newCounter.externalCountRemaining == 0)
delete this;
break;
}
}
}
atomic<T*> data;
atomic<NodeCounter> count;
CountedNodePtr next;
};
public:
LockFreeQueue()
{
//초기니깐 head 와 tail 이 같은 노드를 가리키도록 한다
CountedNodePtr node;
node.ptr = new Node;
node.externalCount = 1;
_head.store(node);
_tail.store(node);
}
LockFreeQueue(const LockFreeQueue&) = delete;
LockFreeQueue& operator=(const LockFreeQueue&) = delete;
/*
* 큐이다 보니 head 오 tail 이 있고 head 와 tail 사이에 데이터를 넣는 방식
* 데이터를 넣을때는 tail 즉 data 의 끝에 추가하고
* 빼올때는 head 데이터의 제일 앞에서 빼온다
*/
//[data][data][value][]
//[head][tail]
//그런데 최초에 head 와 tail 은 dummy [] 노드를 가르키는 방식으로 처리한다
//그래서 head 와 tail 이 같은 노드를 가리키고 있다면 비어 있는 것으로 판단할 것이다
//[]
//[head][tail]
void Push(const T& value)
{
//문제는 head 에서 삭제를 하고 tail 쪽에서 양쪽에서는 삭제를 하기 때문에 양쪽에서 변화가 생길 수 있다는 것
unique_ptr<T> newData = make_unique<T>(value);
CountedNodePtr dummy;
dummy.ptr = new Node;
dummy.externalCount = 1;
CountedNodePtr oldTail = _tail.load(); //최초에 _tail 은 dummy node 이다 이다, queue 방식이 tail 에다가 계속 추가하는 방식이라 dummy 이기도함
while (true)
{
//[참조권 획득]
// 참조권 획득 => externalCount를 현시점 기준 +1 한 스레드가 참조권을 획득한다
// 현재 스레드는 IncreaseExternalCount 함수 내에서 참조 권을 획득하지 못하면 획득 할때까지 참조권을 획득하기 위해서 시도를 반복적으로 함
IncreaseExternalCount(_tail, oldTail);
//결국 여기선 참조권을 획득한 스레드가 내려옴,
//하지만 간발의 차이로 두 스레드가 참조권을 획득 할 수도 있다는 로직상 가정을 해야 한다
// 소유권 획득 (data를 먼저를 교환한 애가 이김)
T* oldData = nullptr;
//모든 스레드가 T* oldData = nullptr; 까지 실행 됐다는 가정 하에..
//oldTail.ptr->data 가 아직 null 이라면 여기 그낭하고 if 문안으로 들어가면서 _tail 의 ptr->data 가 null 이 안되어 다른 스레드가
//접근하지 못하고 다음 루프를 돌게 된다
//
// tail은 새로운 dummy 가 되기 전까지 oldTail 각 스레드별도의 스텍 상에 있는것이기 때문에
// 다른 스레드는 oldTail = _tail.exchange(dummy); 이 실행 되기 전까지 계속 이전과 동일한 노드를 가리키게 되어 => 위에서의 변화 가능성이 있지만 우선 이런 경우라 가정
// 현 스래드의 oldTail.ptr->data 이 뀌어서 newData.get() 가 들어갔다면 다른 스레드에서는 oldTail.ptr->data은 null 이 안되게 된다
// oldTail = _tail.exchange(dummy); 이 실행 된 이후 IncreaseExternalCount(_tail, oldTail); 이 함수가 다시 실행 되면서
// 다른 스레드들의 oldTail 이 dummy 를 가리키기 전까지 계속 while 을 돌게 된다
//[소유권 획득]
//oldTail 은 dummy 라 데이터를 넣어주는 시도를 먼저 함, 데이터를 넣지 못한 다른 스레드는 이 if 를 건너 뛰게 됨
//성공하면 데이터를 먼저 새로운 dummy 노드인 oldTail.ptr->data 포인터 가 새로운 데이터를 가리키게함
if (oldTail.ptr->data.compare_exchange_strong(oldData, newData.get()))
{
//여기에 들어오게 되면 실제 소유권을 획득하게 된것
oldTail.ptr->next = dummy;
//exchange 리턴은 바뀌기전 _tail 값을 리턴한다
oldTail = _tail.exchange(dummy); //_tail을 새로운 dummy 로 바꿔준다, 함수 실행 후 oldTail 은 이전 _tail 값이 된다
//이렇게 호출을 하게 되면 IncreaseExternalCount(_tail, oldTail); 에서의 _tail 은 현재 것이 되고 oldTail 은 마찬가지로 이전것이 된다, 새로운노드가 추가 됐어도
//데이터를 바꾸고 다음 노드를 세팅하게 되면 externalCount를 원상태로 돌려줌
//push 에서도 삭제가 있는것인데 push 가 완료 되기 전 찰나에 pop 이 실행되어 노드를 삭제해야 하는 상황에 발생 할수 있는데
// 이때 찰나의 순간에 pop 이 push 보다 먼저 돌게 되면 push 서 는 노드가 없기 때문에 push 처리 도중 문제가 생길 수 있어서
//push 완료 된다음 삭제를 하기 위해 externalCountRemaining 이걸로 지워도 되는지 판단하고
//문제가 없다면 push 에서도 삭제하게끔 처리를 해주기 위해 push 에서도 삭제가 들어가게 된다
FreeExternalCount(oldTail); //externalCount 를 줄여는 함수
newData.release(); //해제없이 소유권을 놓기만 함, 나중에 delete 는 알아서 해줘야 함
break;
}
//소유권 경쟁 실패
//현재 스레드에서 소유권까지 획득한 다음 자기자신 외에 동시에 실행되는 스레드 개수 만큼
//새로운 dummy 로 바뀌기전의 _tail의 internalCount 가 올라 가는데
//즉 현재 스레드 외에 나머지 스레드에선 소유권을 획득하지 못하였음으로 internalCount 의 값을 1 씩 낮춰준다, 마지막 internalCount == 0이 되는 스레드에서 삭제 처리를 한다
oldTail.ptr->ReleaseRef();
}
}
// [data][data][ ]
// [head][tail]
shared_ptr<T> TryPop()
{
CountedNodePtr oldHead = _head.load();
while (true)
{
// 참조권 획득 (externalCount를 현시점 기준 +1 한 애가 이김)
//push 에서 _tail 은 같은 곳을 바로보고 있긴 하지만 oldTail 이 지역변수를 통해 변도의 externalCount를 유지했다가
// [data][data][ ]
// [head][tail]
//
//복습 및 정리 차원에서 써놓음
//push 할때 노드가 tail 스레드에서 externalCount를 증가 시켜도 IncreaseExternalCount 의 함수에서 data 노드쪽의 externalCount를 증가시켜야 적요 되는것임으로
//head 쪽의 externalCount 이 바로 적용 되는것은 아니다
// 그리고 만약 서로 같은 노드를 head, tail 이 두개가 같은 노드를 가리킨다 할지라도 externalCountRemaining 이 값을 통해 지워도 되는지를
// 한번더 판단하게 되어 push 작업이 마무리 되기 전 먼저 삭제 처리 하는 것을 막게 되기도 한다
//IncreaseExternalCount 이 함수내에서 실제 적용 된것이 참조권을 갖는다
IncreaseExternalCount(_head, oldHead);
Node* ptr = oldHead.ptr;
//[dummy]
//[head][tail]
//쉽게 최초의 경우를 생각해보면 head와 tail 은 같은 dummy 를 가리키고 있음으로
//둘다 같은 곳을 가리킬때에는 삭제 처리 할것이 없다 이럴때는 리턴하고 종료처리
if (ptr == _tail.load().ptr)
{
ptr->ReleaseRef();
return shared_ptr<T>();
}
//여기까지 실행 됐다면 참조권은 획득한 상태
// 소유권 획득 (head = ptr->next)
if (_head.compare_exchange_strong(oldHead, ptr->next))
{
//소유권이 획득 되면 리턴해서 pop 스레드 종료처리 해버림
//여러 스레드가 돌아간다는 것을 상기하고자 하는 차원에서 적자면 => 어차피 pop 하는 거라 현대 스레드에서 종료 해도
//다른 스레드에서 pop 이 돌고 있다고해도 다른 다른 스레드의 pop 들은 이 if 문들을 들어오지 않는 이상 계속 돌고 있음
//data 포인터를 얻어온다
T* res = ptr->data.load(); // exchange(nullptr); 로 하면 버그 있음!
FreeExternalCount(oldHead); //externalCount 를 줄여는 함수
return shared_ptr<T>(res);
}
ptr->ReleaseRef();
}
}
private:
//head 삭제 나 ,tail 추가 되기 때문에 문제가 생길수 있는 부분을 방지하기 위해 atomic<...>& 으로 처리한다
//참조 권을 획득하지 못하면 획득 할때까지 계속 루프를 돈다
static void IncreaseExternalCount(atomic<CountedNodePtr>& counter, CountedNodePtr& oldCounter)
{
while (true)
{
CountedNodePtr newCounter = oldCounter;
newCounter.externalCount++;
//1을 증가 시킨애를 막는 스레드가 참조권을 획득하게 되는것이다
//성공 할때까지 계속 루프를 돌게 => 다른 스레드가 push 를 이미 했다면 현재 스레드는 실패하게 되고
//실패하면 _tail 을 와 oldTail 에 넣게 됨으로 둘은 같은 상태가 우선 된다음 다음 루프에서 참조권 획득을 시도할것이다
if (counter.compare_exchange_strong(oldCounter, newCounter))
{
oldCounter.externalCount = newCounter.externalCount;
break;
}
}
}
//externalCount 를 줄여는 함수
static void FreeExternalCount(CountedNodePtr& oldNodePtr)
{
Node* ptr = oldNodePtr.ptr;
const int32 countIncrease = oldNodePtr.externalCount - 2; //참조권을 획득하면 externalCount 은 2 가 됨으로
NodeCounter oldCounter = ptr->count.load();
while (true)
{
NodeCounter newCounter = oldCounter;
//push 쪽에서 데이터 사용하고 지나간 노드임으로 -1 시켜줌, 그럼 나머지 1이 남는데 그건 pop 할때 -1 을 한번 더 해주고 그렇다면
//아래 if 문에서 삭제와 추가가 서로 겹쳐지는 문제를 externalCountRemaining 값이 0 이 아니라는 값을 판단 할수 있게 되고 externalCountRemaining ==0 이면 삭제 가능한 상태라는 걸 알 수 잇게 된다
newCounter.externalCountRemaining--;
newCounter.internalCount += countIncrease;
if (ptr->count.compare_exchange_strong(oldCounter, newCounter))
{
//newCounter.internalCount == 0 이 면 삭제가 되야 하는 상태 && externalCountRemaining == 0 추가 삭제 한번씩 거친 노드를 의미한다
//externalCountRemaining 은 dummy 노드를 push 해서 사용하고 있는데 pop 스레드에서 해당 노드를 바로 삭제 해버리는 것을 막기 위함
//즉 push 할때 push 작업이 완료 되기도 전에 pop이 실행 되어 _tail 을 삭제 하려고 하면 문제가 발생하기 때문
if (newCounter.internalCount == 0 && newCounter.externalCountRemaining == 0)
delete ptr;
break;
}
}
}
private:
// [data][data][]
// [head][tail]
atomic<CountedNodePtr> _head;
atomic<CountedNodePtr> _tail;
};
main 코드
LockFreeQueue<int32> q;
void Push()
{
while (true)
{
int32 value = rand() % 100;
q.Push(value);
this_thread::sleep_for(1ms);
}
}
void Pop()
{
while (true)
{
auto data = q.TryPop();
if (data != nullptr)
cout << (*data) << endl;
}
}
int main()
{
thread t1(Push);
thread t2(Pop);
thread t3(Pop);
t1.join();
t2.join();
t3.join();
}
결과 화면..
모든 경우의 수를 다 따져가져 이해하기 보다 전체적인 흐름을 이해해보도록 하고 구현대비 성능이 그리 뛰어나진 않다, 별 차이 없음 mutex 가 들어가는 것과
CAS 를 구현하려면 while 이 쓰여지게 되고 이러다보면 스래드들끼리 병합이 일어날때 대기를 계속 해야 하는건 마찬가지이기 때문..
'운영체제 & 병렬처리 > Multithread' 카테고리의 다른 글
| 제프리 리처의 유저모드 동기화들 (0) | 2022.09.28 |
|---|---|
| Threadmanager (0) | 2022.09.27 |
| atomic 가시성, 원자성 (0) | 2022.09.24 |
| lock-free stack (3) : reference count 로 구현 (0) | 2022.09.24 |
| compare_exchange_weak, compare_exchange_strong 차이, Spurious wakeup(가짜 기상) (0) | 2022.09.23 |