
[설계 과정]
1. 문제의 목적?
2. 어떤 패턴?
3. 세부적인 해결 방법
아키텍쳐 설계 : 큰 레벨에서 분류 하는 것
ex) 클라이언트 서버가 어떻게 돌아가느냐, 디비가 어떻게 있느냐
문제를 나누는 것
전체 문제를 쪼개는것 => 목적을 쪼개 나가는 것
이를 전체적으로 쪼개면 프로세스정도로 구분이 되고 이 프로세스를 설계할때
클래스 설계에서부터 패턴으로 올라가면서 설계한다
ex)
웹브라우저 -----> 웹서버 --------> WAS(웹 어플리케이션) [ 디비핸드링, 비즈니스 로직 ]
웹브라우저 ,웹서버 , WAS 까지 나누는 레벨이 아키텍쳐설계
웹브라우저를 짜겠다, 웹서버를 짜겠다 WAS 를 짜겠다는 것은(디비핸들링, 디브니스 로직 으로 들어가면)
클래스 디자인으로 들어감
클래스 정의는? : 클래스 정의는 알아서 한다( 클래스는 알아서 끌어낸다) 분석단계 등에서..
분석단계에서 데이터 모델링한다
(데이터 모델링 : 현실세계에 있는 것을 개체로 이끌어 내면서 구체화해 가는 과정 )
클래스는 명사를 찾아라
이런걸 이용해서 클래스를 끌어내야 한다, 클래스를 정의 해야 한다
이제 여기에서 클래스들을 어떻게 최적화 시킬것인가에 대한 패턴을 대보는것 => 디자인 패턴
그래서 디자인패턴은 상세설계에서 사용하게 된다
* 패턴도 패턴안에서 섞일 수도 있다 즉 => 목적두개가 겹친다
디자인패턴은 클래스 구조( 화살표) 를 먼저 보는 것이 아닌 목적을 먼저본다음 클래스 구조를 봐야 한다
-product family 를 만들기 위한 패턴 = Abstract Factory
-부분 부분을 생성해서 전체를 생성하는것 = builder
-객체 생성을 대행해주는 함수 = Factory Method
-복제해서 객체를 생성하고 싶으면 = ProtoType
-Maximum N 개까지만 객체를 생성하고 싶으면 = SingleTon
-기존 객체를 사용하고 싶은데 인터페이스가 틀리다 = adapter
[구조] adapter 패턴 (잘 구현된 클래스에 구현할 기능이 있는 경우 클래스를 private 으로 상속 하는 패턴)
-처음 클래스를 설계하면서 interface 와 information 을 나누어서 설계하고 싶다 = bridge
[구조] bridge 패턴 (구현부와 인터페이스를 나누어버리는 패턴 ,여러 환경에서 조사된 가장 적합한 기능에 대해 연결해주는 패턴 대신 실행하는 패턴)
ex) 1.가장 적절한 클래스를 생성해 리턴(unix,window , etc... 등등...)
2.여러 클래스가 해당 플렛폼에 대해 동일한 클래스(정보) 를 자동으로 플렛폼에 맞게 얻고자 할때
-tree 형태로 객체부수를 관리하고 싶다 = composite
-동적으로 객체의 기능을 확장시켜 나가고 싶다 = decorator
[구조] decorator 패턴 ( on,off 없이 윈도우에 추가되는 스크롤 같은것 연달아 추가 )
(객체 추가되면서 추가된것 다 실행됨 : 객체가 다음실행할 객체를 (중간)Decorator 클래스 포인터로 가지고 있음)
-서브시스템을 대표하는 인터페이스를 갖고 싶다 = Facade
-객체를 공유하고 싶다 = Flyweight
-중간 매개 개체를 이용해 원객체에 대해 접근제어라든지 추가적인 작업을 하고 싶다 proxy
-동적으로 수행할 역할을 이행 시키기, 위임시키기 위해 연결해 놓은 것을 처리 하고 싶다 = chain of responsibility
[행동] chain of responsibility (동적으로 처리할 역할을 연결해 놓은 것, 책임(조건)에 따라 처리 사항을 다음으로 넘기는 것, 처리를 분담)
// 현재 클래스에서 처리하지 못하면 부모클래스에서는 다음 객체포인터를 가지고 있어서 그 객체 포인터로 책임전가
(객체 추가는 없고 고정된 상태)
-수행할 작업을 일반화 시켜서 핸들링 하고 싶을때 = command
(하나의 함수 명령으로 수행)
-어떤 문법에 따라서 파싱하고 원하는 작업까지 동시에 하고 싶다 = interpreter
-어그리게이트의 구성요소를 차례로 접근하고 싶다 = iterator
-M:N 관계를 1:N 관계로 바꾸고 싶다 = mediator
(중계자)
-객체의 상태정보를 별도의 객체에 저장하고 싶다 = memento
(저장만 하는 것만!!)
-객체 상태정보를 저장하기도 하고 상태에 따라서 행위까지 핸들링 하고 싶으면 = state
[행동] state 패턴 ( 각 상태에 대해 객체로 만들어 분리 처리하는 것 , 게임능력레벨에 해당하는 행동을 클래스로 분류해서 처리 )
ex) 각 레벨에 따른 행동 또는 상태 정보가 각 레벨 클래스마다 있고 이 클래스들은 공통적인 것이므로 singleton 처럼 객체가 공유된다
-1:N 의 관계를 유지하면서 객체간의 행위를 분산하고 싶을때 = observer
subject 에게 observer 가 변경상태를 통지하면 subject 가 나머지 observer 들에게 변경 내용을 알려주어 변경 내용(상태)에 따라
나머지 observer 들이 그 내용에 맞게 수행하는 패턴
-동일 목적의 여러 알고리즘 들을 동적으로 변경시키고 싶다 = strategy
[행동]Strategy 패턴 같은 목적을 수행하는 알고리즘을 동적으로 바꾸고 싶을때
-알고리즘의 기본 골격을 만들어 놓고 난다음 세부 알고리즘은 하위 클래스에서 알아서 바뀌도록 하고 싶다 = Template method
[행동] Template Method 패턴 (공통된 알고리즘 부분이 고정적일때 사용, 기본 알고리즘 골격을 상위 클래스에서 갖도록 한다 )
하위 클래스에서 구체적으로 처리하기
: instance 는 자식으로 생성해놓고 부모에만 정의된 함수를 호출하여 이 함수 안에 virtual 로 선언된 공통함수를 호출하여
instance 를 만든 자식의 virtual 함수가 불리도록 하는 흐름
-작업 대상과 작업 종류 작업 항목을 분류해서 작업종류를 임의로 추가하는 것을 유연하게 하고 싶다 = visitor
[행동] visitor 패턴 (고정부분과 동적인 부분을 클래스에서 분리)
: 데이터 구조와 처리를 분리 하는 패턴.
> 필요할 때 : 처리를 데이터 구조에서 분리해야 할 때. => 결합도를 낮춘다
'strategy 패턴과 응용해서 사용
디자인패턴을 실제 어떻게 적용할 것인가?
한번만에 최적이 나오긴 힘들다, 한번 이터레이션 해보고 Localizatio of change(변경을 국지화) 를 할 수 있는가?
를 따져보고 된다면 판단하고 적용
변경 안되는 부분, 변경되는 부분을 고려햐여 고려
일단 패턴을 알면 보통이상의 퀄리티를 보장해 줄 수 있다
중요한 점은 어떤 목적으로 접근할 것인가 하는 것이다
많은 고민에 의해서 적용해야지 대강 생각해서 적용해버리면 일정 수준이상에서 퀄리티가 올라가지 않을 수 있다
생각을 많이 해보자
무엇을 할것인가? => 뭘 할껀데? => 목적이 무엇인가
어떻게 할것인가 => 최적화적인것을 판단
이하 자료는 퍼온 자료들..
디자인패턴들의 상관관계

[관계도 설명]
-builder 패턴은 composite 객체를 생성하기 위해 사용 될 수 있다
-iterator 패턴은 Composite 객체를 구성하는 하위 객체들을 순회하기 위해 사용 될 수 있다
-Command 패턴은 MacroComand 클래스 등의 정의시 Composite 패턴을 활용 가능하다
-chain of responsibility 패턴은 객체들간의 연결 사슬을 composite 패턴을 이용하여 정의 할 수 있다
-composite 객체를 구성하는 각 하위 객체들에게 새로운 연산을 추가하 위해 visitor 패턴이 사용 될 수 있다
(트리 구조에서 각 노드마다 새로운 연산을 위해 함수들을 visitor 로 만들 수 있다)
-interpreter 패턴은 문법을 정의하는 과정에서 Abstract Syntax Tree 를 Composite 패턴으로 표현할 수 있다
(트리가 composite로 표현)
-Composite 객체를 구성하는 하위 객체들은 Decorator 패턴을 이용하여 추가적인 역할을 수행하도록 설계 될 수 있다
- Flyweight 패턴은 Strategy, State, interpreter 패턴에서 알고리즘이나 상태정보, Terminal Symbol 들을 각각 공유하기 우해 사용 될 수 있다
- Decorator 패턴은 이미 존재하는 객체에 새로운 기능을 덧입히는 역할을 하는데 반해
Strategy 패턴은 객체 내부의 구체적인 동작이나 알고리즘을 외부 객체에게 위임시키는 형태이다
그래서, Decorator 패턴은 객체의 겉을 변경시켜주는 역할이고, Strategy 패턴은 객체의 속을 변경시켜주는
역할을 한다고 할 수 있다
- Memento 패턴은 Iterator 패턴이 반복 상태를 저장하기 위해 이용 할 수 있으며
Command 패턴이 명령 수행 이전 상태로 되돌아가기 위해 사용 할 수 있다
- Observer 패턴은 객체들 간의 의존 관계를 분산 시켜 관리하는 데 반해 Mediator 패턴은
중앙 집중적으로 관리하기 때문에 복잡한 의존 관계를 한 곳에서 관리하고자 할 경우에는
Mediator 패턴이 효과적이다
- Template Method 패턴은 내부의 알고리즘 단계를 정의할 때(변하지 않는 부분) Strategy 패턴을 사용 할 수 있으며
, 대개 Factory Method 패턴을 사용하여 필요한 객체를 생성한다
- Abstract Factory 패턴은 종종 Factory Method 패턴이나 Prototype 패턴을 이용하여 구현되며,
Singleton 패턴을 이용하여 하나의 공유되는 객체를 관리할 수 있다
- Singleton 패턴은 Facade 패턴에서도 하나의 객체를 공유하기 위한 목적으로 사용 될 수 있다
아래 있는건 다른곳에서 퍼온 것
http://mrnoname.blog.me/130112026691
상반기 개인 학습 목표로 디자인 패턴을 선택한 관계로, 한 동안 'Java 언어로 배우는 디자인 패턴 입문' 이라는 책으로 디자인 패턴에 대해서 알아보았습니다.
이미 책을 보기 전부터, 코딩을 하며 Singleton이라던지 Factory Method 패턴들을 접해보았고, 직접 적용도 조금 해봤기 때문에, 대략적으로 디자인 패턴이 무엇인지는 어렴풋이 알고 있었습니다. 그래서 이번에 디자인 패턴 학습에서는 '어떤 디자인 패턴들이 있고, 어떨 때 사용해야 될 까?'에 대해서 알아보는 것에 중점을 두었습니다.
디자인 패턴 관련 서적 중에 가장 유명한 책은 'Head First 디자인 패턴'이었는데, 개인적으로 Head First 시리즈는 그냥 그냥 보기에는 좋지만, 나중에 머리에 남는 것이 별로 없는 것 같아서, 조금 딱딱해 보여도 실질적인 예제 코드들로 설명이 잘 되어있다는 'Java 언어로 배우는 디자인 패턴 입문'을 고르게 되었습니다.
처음에는 처음부터 순서대로 읽어가면서 정리를 해보자는 생각으로 책을 읽기 시작했는데, 점점 정리를 하다 보니 '아, 이러면 안되겠구나…'라는 생각이 들었습니다. 예전에 개발을 하고 싶지만 전혀 못하던 시절, C++ 책만 이 책, 저 책 사서 보기만 하고 어려워서 포기하고 쉽다는 다른 책 사보고 했던 게 생각이 났습니다. '百聞이 不如一打'라고 개발 공부에는 백 번 보는 것 보다, 한번 쳐보는 게 훨씬 빨리 이해할 수 있을 텐데, 이렇게 책만 붙잡고 있는다고 해서 디자인 패턴에 대해서 얼마나 알 수 있겠나 싶었습니다. 그리고 이 책에 나오는 디자인 패턴을 모조리 다 외운다고 해서 실제 개발에 얼마나 써먹을 수 있을지에 대해서도 의문이 들었습니다. 그래서 그 때 부터는, 디자인 패턴에 대해서 간략하게만 설명해두고, 어떨 때 사용할 수 있는지, 어떨 때 적용하면 좋은지에 대해서만 정리 했습니다. 그러면 나중에 특정 디자인 패턴이 필요한 상황에서 적절한 디자인 패턴을 찾아서 적용시키기 좋을 것이고, 한번씩 정리하면서 어떤 디자인 패턴들이 있는지에 대해서도 숙지할 수 있을 것 같았습니다.
그렇게 책을 한번 읽고, 정리하면서 어떤 디자인 패턴들이 있는지, 어떤 상황에서 사용해야 하는지, 어떤 방식으로 문제를 해결하는지에 대해서 알 수 있었습니다. 그리고 이번에 학습을 하면서 'Effective Java' 역시 함께 참고하였는데, 이 책에도 디자인 패턴에 관련된 내용들이 많이 나와서 좀 더 고급스러운 패턴 사용법들을 볼 수 있었습니다. 특히 실제로 자주 사용되는 디자인 패턴 중 하나인 Singleton 패턴을 구현 할 때, 자바 1.5 이상의 경우 Enum 타입으로 구현을 하면, 복잡한 직렬화나 리플렉션 상황에서도 직렬화가 자동으로 지원되며, 인스턴스가 여러 개 생기지 않도록 확실히 보장해 주기 때문에 가장 권장 하는 구현 방법이라는 것을 보고, 실제로 과제용 프로그램을 작성할 때 적용시켜 보기도 했습니다. (아래 정리에 예제 코드 포함)
이번 디자인 패턴을 학습하면서, 여태까지 무심코 사용하고 있었던 코딩 기법들이 알고 보니 디자인 패턴들이었던 것 도 알 수 있었고,(기존 코딩 기법에 패턴이란 이름을 붙인 걸 수도 있겠네요) 디자인 패턴이란 것이 그렇게 특별한 것이 아닌 것 같다는 생각을 했습니다.
디자인 패턴은 객체 지향 개념과 아주 밀접한 관계를 가지고 있는 것 같습니다. 저는 디자인 패턴이란 '객체 지향 개념(상속,재사용성,캡슐화,추상화 등등)을 어떻게 하면 더 깔끔하고 효율적으로 적용할 수 있을까? 에 중점을 두고 개발을 하기 위한 기법들을 정리한 것'이라고 생각합니다.
아직은 개발 경력이 얼마 되지 않아서, 이런 디자인 패턴들을 언제 어떻게 적용해야 하는지, 또 적용 할 수 있을 지는 잘 모르겠지만, 이번에 디자인 패턴에 대해 알아 보면서, 객체 지향 개념에 대해서 좀 더 자세히 알 수 있게 된 것 같습니다.
다음은 책 보면서 간단히 정리한 내용들인데, 각 패턴에 대해서 간략히 훑어보기에는 좋은 것 같습니다. 마지막에 디자인 패턴 Q&A 파트 중, 다음 내용을 처음부터 알았다면, 책을 처음부터 찬찬히 읽는 수고는 덜었을지도 모르겠네요…ㅠ
디자인 패턴은 모두 외울 필요가 없다
- 기계적으로 디자인 패턴을 외우는 것은 의미가 없다. 디자인 패턴이 문제를 어떻게 해결하고 있는지 이해하는 것이 중요하다.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
시작하기전에
- 디자인 패턴은 클래스 라이브러리가 아니다
○ 클래스 라이브러리 안에서 디자인 패턴이 사용되고 있다
- 프로그램을 완성품으로 보지 않는다
○ 디자인 패턴의 목표는 재사용성
○ 어떤 기능이 확장될 가능성이 있는가?
○ 확장기능을 수행할 때 수정이 필요한 클래스는 무엇인가?
○ 수정이 불필요한 클래스는 무엇인가?
- 다이어그램은 보는 것이 아니라 읽는 것이다
Iterator 패턴 - 순서대로 지정해서 처리하기
Iterator(반복자) 패턴 : 무엇인가 많이 모여있는 것들을 순서대로 지정하면서 전체를 검색하는 처리를 실행하기 위한 것.
hasNext와 next를 이용해서 요소들을 탐색한다.
Iterator를 사용하는 이유 : 구현과 분리해서 하나씩 셀 수 있다.
Next는 틀리기 쉽다 : next의 정확한 의미는 returnCurrentElementAndAdvanceToNextPosition
hasNext도 틀리기 쉽다 : 최후의 요소를 얻은 뒤에false를 반환한다. 즉 "다음next를 불러도 괜찮은지 조사하는" 메소드.
Adapter 패턴 - 바꿔서 재이용하기
Adapter 패턴 : 이미 제공되어 있는 것과 필요한 것의 차이를 없에주는 디자인 패턴. (Wrapper 패턴)
a. 상속을 사용한 Adapter 패턴 : 인터페이스 + 클래스의 다중 상속
b. 위임을 사용한 Adapter 패턴 : 클래스 + 클래스의 경우 ->위임(Composition을 사용)
Adapter를 사용하는 이유 : 항상 처음부터 프로그래밍을 하는 것이 아니기 때문에, 구현하려는 기능이 이미 존재하고 검증 받았다면, 그것을 이용하는 편이 좋고, 그러기 위해서 Adapter 패턴을 이용하는 것이다.
Template Method - 하위 클래스에서 구체적으로 처리하기
Template Method 패턴 : 상위 클래스에서 추상메소드를 통해 뼈대를 결정하고, 하위 클래스에서 그 구체적인 내용을 결정하는 패턴. Java에서 Interface를 상속받아 구현하는 것과 같다.
Factory Method 패턴 - 하위 클래스에서 인스턴스 작성하기
Factory Method 패턴 : 인스턴스를 만드는 방법을 상위 클래스에서 결정하지만, 구체적인 클래스 이름 까지는 결정하지 않는 것. 인스턴스의 골격과 생성을 분리할 수 있다. Template Method 의 전형적인 응용.
Static Factory Method 패턴 : 생성자 대신 고유의 이름을 가지는 static method를 이용해 인스턴스를 생성하면, 생성자를 사용 할 때보다 다양한 이득이 있다.
Singleton - 인스턴스를 한 개만 만들기
Singleton 패턴 : 클래스의 인스턴스가 단 하나만 필요할 때, 인스턴스가 한 개 밖에 존재하지 않는 것을 보증하는 패턴.
Singleton 패턴의 구현 방법
a. INSTANCE를 public final 필드로 선언한다.
b. static factory method를 이용해서 Instance를 참조하도록 한다.(전형적인 getInstance() 메소드를 이용한 구현)
c. Enum 싱글톤 : 하나의 요소만 가지는 열거형(Enum)으로 선언.
public enum Elvis {
INSTANCE;
public void leaveTheBuilding(){…}
}
Prototype - 복사해서 인스턴스 만들기
Prototype 패턴 : 인스턴스를 new로 생성하지 않고 복사해서 새로운 인스턴스를 만드는 패턴. clone 메소드를 이용하여 새로운 인스턴스들을 생성한다. Clonable이 구현 된 클래스에만 적용가능.
Prototype 패턴을 사용하는 경우
a. 종류가 너무 많아서 정리할 수 없는 경우
b. 클래스로부터 인스턴스 생성이 어려운 경우
c. framework와 생성하는 인스턴스를 분리하고 싶은 경우
Builder - 복잡한 인스턴스 조립하기
Builder 패턴 : 전체를 구성하고 있는 각 부분을 만들고 단계를 밟아 만들어 나가는 패턴. 메소드 하나 하나가 메소드 전체를 완성시킨다.
Abstract Factory - 관련 부품을 조합해서 제품 만들기
Abstract Factory 패턴 : Factory Method 패턴과 비슷하지만 Abstract Factory 패턴은 객체 생성과정을 Interface화 시키고, Factory Method 패턴은 객체 생성 자체를 다른 메소드에 넘긴다.
Bridge - 기능 계층과 구현 계층 분리하기
Bridge 패턴 : 기능의 클래스 계층과 구현의 클래스 계층 사이에 다리를 놓는 것.
기능의 클래스 계층 : 새로운 기능을 추가하고 싶을 경우, 클래스 계층 안에서 자신의 목적과 가까운 클래스를 찾아내 그 하위 클래스를 만들어, 목적한 기능을 추가한 새로운 클래스를 만든다는 것.
구현의 클래스 계층 : 새로운 구현을 위해 추상 클래스의 하위 클래스를 만들어 추상 메소드를 구현하는 것.
사용하는 이유 : 구현과 기능의 클래스 계층을 분리하여 각각 계층을 독립적으로 확장할 수 있고, 새로 기능을 추가하더라도 모든 구현에서 사용할 수 있게 된다.
Strategy - 알고리즘을 모두 바꾸기
Strategy 패턴 : 알고리즘을 독립적으로 구현시켜 필요한 알고리즘을 필요할 때 삽입하는 패턴. 위임이라는 느슨한 연결을 사용하여 알고리즘을 손쉽게 교체할 수 있다.
필요할 때 : 알고리즘 교체를 쉽게 하고 싶을 때. (특히 동적으로)
Composite - 그릇과 내용물을 동일시하기
Composite 패턴 : 그릇과 내용물을 동일시해서 재귀적인 구조를 만들기 위한 디자인 패턴.
필요할 때 : 재귀적인 구조가 필요할 때. 트리 구조로 된 데이터 구조는 Composite 패턴에 해당한다.
Decorator - 장식과 내용물을 동일시하기
Decorator 패턴 : 오브젝트에 기능을 추가해 나가는 디자인 패턴.
필요할 때
○ 내용물을 변경하지 않고 기능을 추가하고 싶을 때.
○ 동적인 기능을 추가하고 싶을 때.
Visitor - 데이터 구조를 돌아다니면서 처리하기
Visitor 패턴 : 데이터 구조와 처리를 분리 하는 패턴.
필요할 때 : 처리를 데이터 구조에서 분리해야 할 때.
Chain of Responsibility - 책임 떠넘기기
Chain of Responsibility 패턴 : 복수의 오브젝트를 사슬처럼 연결해 두면, 그 오브젝트의 사실을 차례로 돌아다니면서 목적한 오브젝트를 결정하는 패턴. 요구를
필요할 때 : Client와 ConcreteHandler 을 유연하게 연결하는 것.
Facade - 단순한 창구
Facade 패턴 : 단순한 창구 역할을 하는 패턴. 클래스를 개별적으로 제어하지 않아도, 창구에 요구만 하면 역할이 끝난다.
필요할 때 : 내부에서 실행되고 있는 많은 클래스의 관계나 사용법이 복잡한 것들을 단순하게 보여줘야 할 때. 인터페이스(API)를 적게 하는 것이 핵심이다. 클래스나 메소드가 많으면 무엇을 사용해야 할 지 고르기가 어렵고, 틀리기도 쉽다. 이런 인터페이스들을 적게 해 주는 것이 Facade패턴.
Mediator - 중개인을 통해서 처리하기
Mediator 패턴 : 조정자, 중개자라는 의미로, 다수의 오브젝트 사이를 조정해야 할 경우 사용한다. 각각의 오브젝트들이 상호간에 통신을 하는 것이 아니라, 중개인을 통해서만 통신을 하는 패턴.
필요할 때 : 각 클래스에서 분산 시킬 것은 부산 시키고, 집중시킬 것은 집중시켜야 할 때, 중개자 패턴을 통해서 집중시킨다.
Observer - 상태의 변화를 알려주기
Observer 패턴 : 오브젝트의 활동을 관찰자가 기록하는 패턴. Observer는 Subject를 관찰하게 된다. MVC Model-View 관계는 Subject-Observer 관계에 대응한다.
실제로는 Observer가 관찰 한다기 보다는, Subject가 상태를 전달하는 것을 기다리고 있는 구조.
필요할 때 : 상태 변화에 따른 처리를 기술 할 때.
Memento - 상태를 저장하기
Memento 패턴 : 어떤 시점의 인스턴스의 상태를 확실하게 기록해서 저장해 두고, 나중에 인스턴스를 그 시점의 상태로 되돌릴 수 있는 패턴. undo, redo, history, snapshot 등의 기능을 실행할 수 있다.
필요할 때 : 변해버린 인스턴스의 상태를 원래대로 돌려야 할 때, 캡슐화의 파괴에 빠지지 않고 저장과 복원을 실행해야 할 때.
State - 상태를 클래스로 표현하기
State 패턴 : 사물이나 모양이나 형편(상태)을 클래스로 표현하는 패턴.
필요할 때 : 사물의 상태의 변화를 표현하고 추가해야 될 때.
Flyweight - 동일한 것을 공유해서 낭비 없에기
Flyweight 패턴 : 인스턴스를 가능한 대로 공유시켜서, 쓸데없이 new 하지 않도록 하는 패턴. 인스턴스를 필요할 때마다 new 하는 것이 아니라, 이미 만들어져 있는 인스턴스를 사용할 수 있으면 그것을 공유해서 사용한다.
필요할 때 : 객체를 가볍게 해야 할 때. (메모리 사용량을 줄여야 할 때.)
Proxy - 필요해지면 만들기
Proxy 패턴 : 대리인이라는 의미로, 대리역할을 하는 클래스가 실제 클래스의 역할을 대신 하다가, 실제 클래스의 기능이 필요할 때가 되면 그때 실제 클래스의 인스턴스를 생성하는 패턴.
필요할 때 : 시간이 오래 걸리는 작업을 해야할 때. 초기화에 시간이 걸리는 기능이 많이 존재한 대규모 시스템의 경우, 기동 시점에 이용하지 않는 기능까지 모두 초기화 하면 느려지므로, Proxy 패턴을 이용하여 사용할 때 초기화 하도록 한다.
Command - 명령을 클래스로하기
Command 패턴 : 명령을 클래스로 표현하는 패턴. 명령을 나타내는 클래스의 인스턴스를 하나의 '물건'처럼 표현할 수 있다. 명령의 집합을 저장해 두면 같은 명령을 재실행 하거나, 복수의 명령을 모아서 새로운 명령으로 재이용할 수도 있다.
Interpreter - 문법규칙을 클래스로 표현하기
Interpreter 패턴 : 프로그램이 해결하려는 문제를 간단한 '미니 언어'로 표현하는 패턴. 구체적인 문제를 미니 언어로 기술된 '미니 프로그램'으로 표현한다. 그리고 그 미니 프로그램을 통역하는 프로그램을 만들고, 미니 프로그램을 실행할 수 있도록 한다.
디자인 패턴 Q&A
디자인 패턴이란?
○ 소프트웨어 설계시에 반복해서 발생하는 문제에 대한 해법.
적절한 디자인 패턴의 선택
○ 자신이 설계하고 있는 소프트웨어가 어떤 '문제'를 포함하고 있는지 알아야 한다.
디자인 패턴은 모두 외울 필요가 없다
○ 기계적으로 디자인 패턴을 외우는 것은 의미가 없다. 디자인 패턴이 문제를 어떻게 해결하고 있는지 이해하는 것이 중요하다.
디자인 패턴과 알고리즘
○ 디자인 패턴과 알고리즘은 다르지만 밀접한 관계가 있다. 알고리즘을 문제해결의 수법으로 기술해서 패턴으로 표현할 수 있지만, 알고리즘=디자인 패턴은 아니다. 디자인 패턴은 알고리즘 이외에도 이디엄(코딩 시 자주 사용되는 관용구)과도 관계가 있다. 디자인 패턴은 구체적인 구현이라기 보다는, 구체적인 구현을 실현하기 위한 사고방식, 해법이라고 할 수 있다.










































































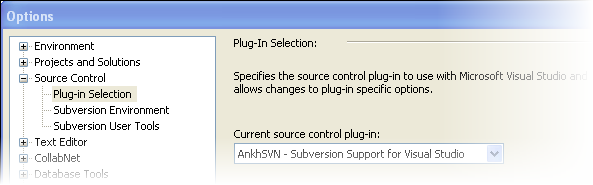
 ( 역자주 : 왼쪽글 - 디폿에 니가 접근할 수 있는 파일을 제한한다. 니가 원하는 것들만 보이는지 한번 확인해라.
( 역자주 : 왼쪽글 - 디폿에 니가 접근할 수 있는 파일을 제한한다. 니가 원하는 것들만 보이는지 한번 확인해라.







 .
.
 .
.

























 . The commands work the same as if you right clicked the folder containing the solution. Follow the steps below to get your own tortoise toolbar.
. The commands work the same as if you right clicked the folder containing the solution. Follow the steps below to get your own tortoise toolbar.





