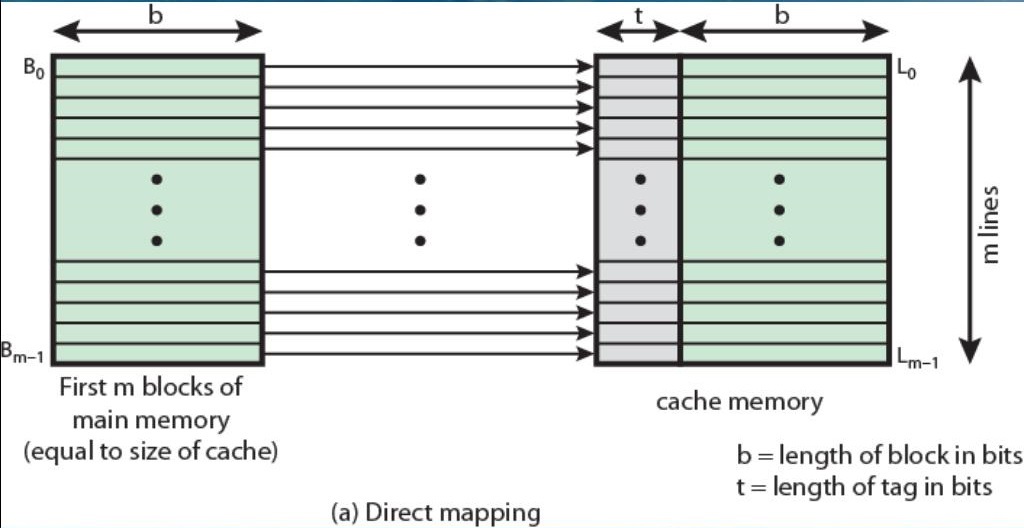
It was first defined as the property that requires that
"... the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program."[1]
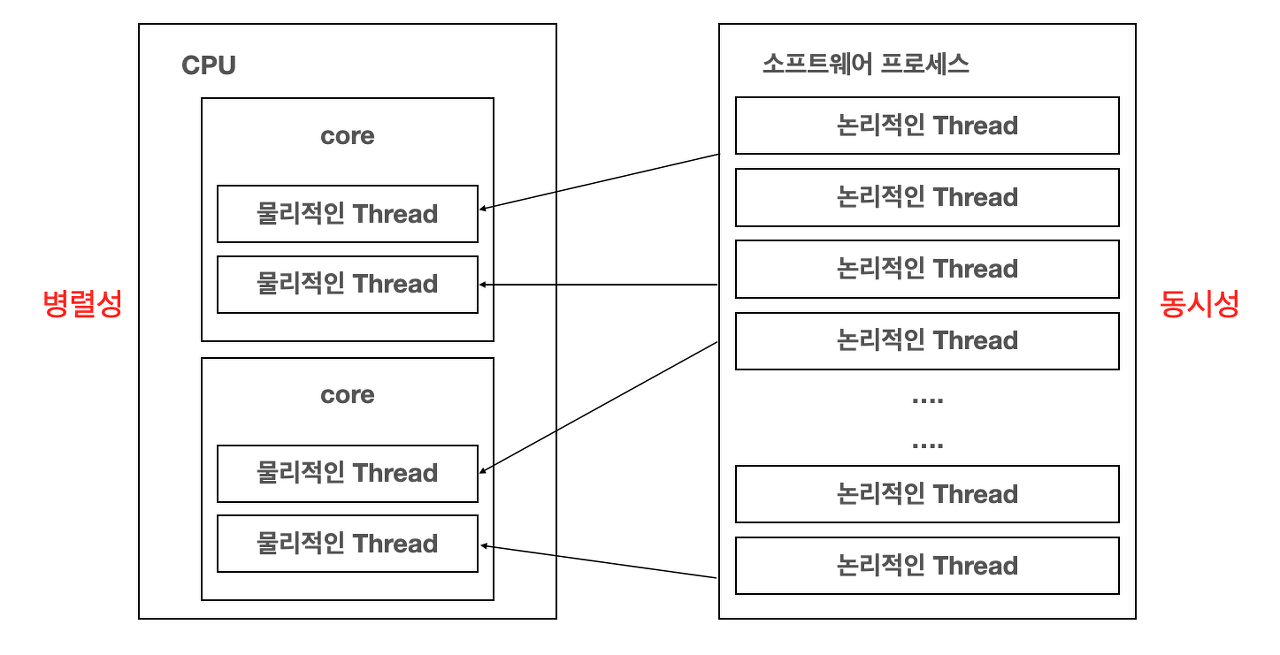
To understand this statement, it is essential to understand one key property of sequential consistency: execution order of program in the same processor (or thread) is the same as the program order, while execution order of program between processors (or threads) is undefined. In an example like this:
Execution order between A1, B1 and C1 is preserved, that is, A1 runs before B1, and B1 before C1. The same for A2 and B2. But, as execution order between processors is undefined, B2 might run before or after C1 (B2 might physically run before C1, but the effect of B2 might be seen after that of C1, which is the same as "B2 run after C1")
Conceptually, there is single global memory and a "switch" that connects an arbitrary processor to memory at any time step. Each processor issues memory operations inprogram orderand the switch provides the global serialization among all memory operations[2]
The sequential consistency is weaker thanstrict consistency, which requires a read from a location to return the value of the last write to that location; strict consistency demands that operations be seen in the order in which they were actually issued.
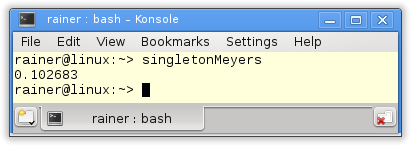
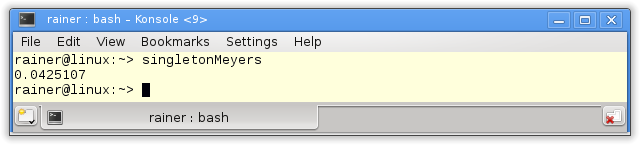
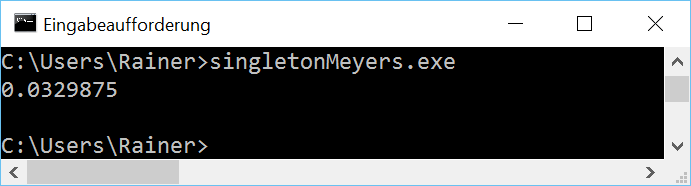
The beauty of the Meyers Singleton in C++11 is that it's automatically thread-safe. That is guaranteed by the standard:Static variables with block scope.The Meyers Singleton is a static variable with block scope, so we are done. It's still left to rewrite the program for four threads.
// singletonMeyers.cpp
#include <chrono>
#include <iostream>
#include <future>
constexpr auto tenMill= 10000000;
class MySingleton{
public:
static MySingleton& getInstance(){
static MySingleton instance;
// volatile int dummy{};
return instance;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
};
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
I use the singleton object in the functiongetTime(line 24 - 32). The function is executed by the fourpromisein line 36 - 39. The results of the associatefuturesare summed up in line 41. That's all. Only the execution time is missing.
Without optimization
Maximum optimization
빠르다 Thread safe
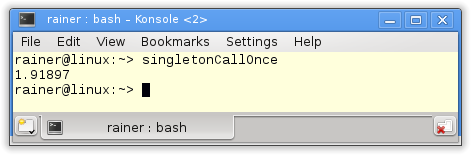
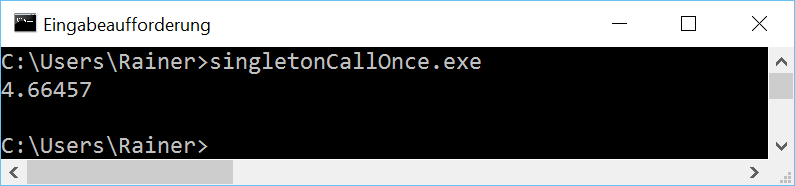
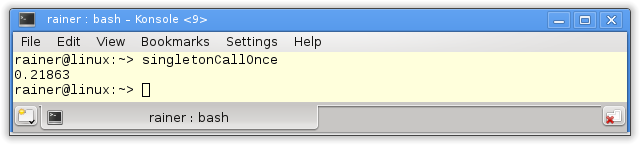
The next step is the functionstd::call_oncein combination with the flagstd::once_flag.
The function std::call_once and the flag std::once_flag
You can use the functionstd::call_onceto register a callable which will be executed exactly once. The flagstd::call_oncein the following implementation guarantees that the singleton will be thread-safe initialized.
// singletonCallOnce.cpp
#include <chrono>
#include <iostream>
#include <future>
#include <mutex>
#include <thread>
constexpr auto tenMill= 10000000;
class MySingleton{
public:
static MySingleton& getInstance(){
std::call_once(initInstanceFlag, &MySingleton::initSingleton);
// volatile int dummy{};
return *instance;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
static MySingleton* instance;
static std::once_flag initInstanceFlag;
static void initSingleton(){
instance= new MySingleton;
}
};
MySingleton* MySingleton::instance= nullptr;
std::once_flag MySingleton::initInstanceFlag;
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
Here are the numbers.
Without optimization
Maximum optimization
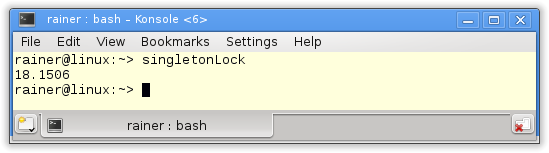
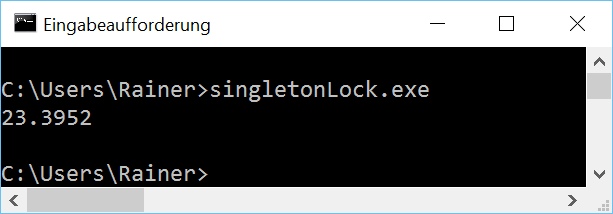
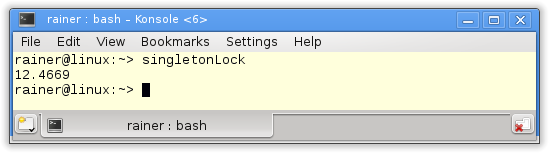
Of course, the most obvious way is it protects the singleton with a lock.
Lock
The mutex wrapped in alockguarantees that the singleton will be thread-safe initialized.
// singletonLock.cpp
#include <chrono>
#include <iostream>
#include <future>
#include <mutex>
constexpr auto tenMill= 10000000;
std::mutex myMutex;
class MySingleton{
public:
static MySingleton& getInstance(){
std::lock_guard<std::mutex> myLock(myMutex);
if ( !instance ){
instance= new MySingleton();
}
// volatile int dummy{};
return *instance;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
static MySingleton* instance;
};
MySingleton* MySingleton::instance= nullptr;
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
How fast is the classical thread-safe implementation of the singleton pattern?
Without optimization
Maximum optimization
뮤텍스만 적용하면 이때는 Meyers Singleton 에 비해 많이 느리 다는 것을 알 수 있다
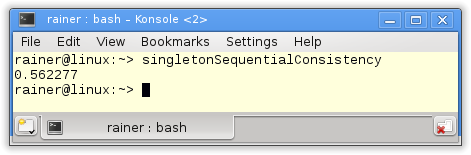
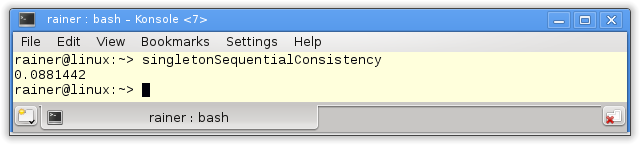
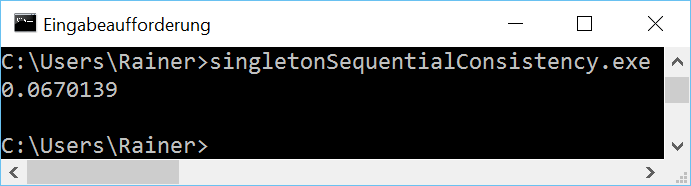
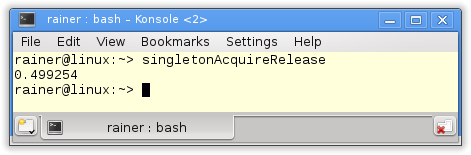
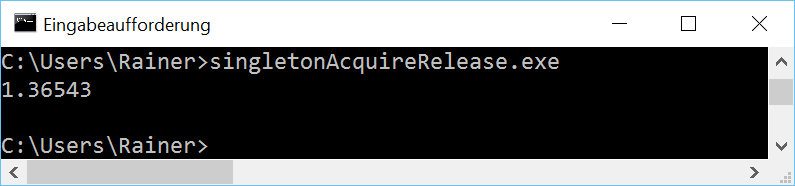
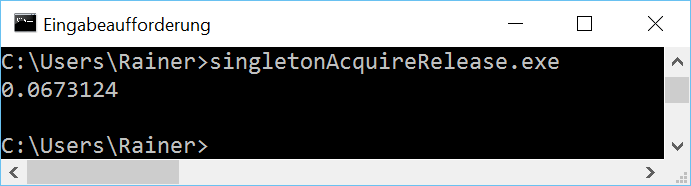
The handle to the singleton is atomic. Because I didn't specify the C++ memory model the default applies:Sequential consistency.
// singletonAcquireRelease.cpp
#include <atomic>
#include <iostream>
#include <future>
#include <mutex>
#include <thread>
constexpr auto tenMill= 10000000;
class MySingleton{
public:
static MySingleton* getInstance(){
MySingleton* sin= instance.load();
if ( !sin ){
std::lock_guard<std::mutex> myLock(myMutex);
sin= instance.load();
if( !sin ){
sin= new MySingleton();
instance.store(sin);
}
}
// volatile int dummy{};
return sin;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
static std::atomic<MySingleton*> instance;
static std::mutex myMutex;
};
std::atomic<MySingleton*> MySingleton::instance;
std::mutex MySingleton::myMutex;
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
Now I'm curious.
Without optimization
Maximum optimization
But we can do better. There is an additional optimization possibility.
atomic 만 추가 했는데Meyers Singleton 만큼 빨라진 것을 볼 수 있다
여기서 약간 더 최적화 할 수 있는데 Acquire-release 체계를 사용 하는것 Memory Model
Acquire-release Semantic
The reading of the singleton (line 14) is an acquire operation, the writing a release operation (line 20). Because both operations take place on the same atomic I don't need sequential consistency. The C++ standard guarantees that an acquire operation synchronizes with a release operation on the same atomic. These conditions hold in this case therefore I can weaken the C++ memory model in line 14 and 20.Acquire-release semanticis sufficient.
// singletonAcquireRelease.cpp
#include <atomic>
#include <iostream>
#include <future>
#include <mutex>
#include <thread>
constexpr auto tenMill= 10000000;
class MySingleton{
public:
static MySingleton* getInstance(){
MySingleton* sin= instance.load(std::memory_order_acquire);
if ( !sin ){
std::lock_guard<std::mutex> myLock(myMutex);
sin= instance.load(std::memory_order_relaxed);
if( !sin ){
sin= new MySingleton();
instance.store(sin,std::memory_order_release);
}
}
// volatile int dummy{};
return sin;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
static std::atomic<MySingleton*> instance;
static std::mutex myMutex;
};
std::atomic<MySingleton*> MySingleton::instance;
std::mutex MySingleton::myMutex;
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
The acquire-release semantic has a similar performance as the sequential consistency. That's not surprising, because on x86 both memory models are very similar. We would get totally different numbers on an ARMv7 or PowerPC architecture. You can read the details on Jeff Preshings blogPreshing on Programming.
Without optimization
Maximum optimization
.
If I forget an import variant of the thread-safe singleton pattern, please let me know and send me the code. I will measure it and add the numbers to the comparison.
Static variables with block scope will be created exactly once. This characteristic is the base of the so called Meyers Singleton, named afterScott Meyers. This is by far the most elegant implementation of the singleton pattern.
By using the keyworddefault,you can request special methods from the compiler. They are Special because only compiler can create them. Withdelete,the result is, that the automatically generated methods (constructor, for example) from the compiler will not be created and, therefore, can not be called. If you try to use them you'll get an compile time error. What's the point of the Meyers Singleton in multithreading programs? The Meyers Singleton is thread safe.
A side note: Double-checked locking pattern
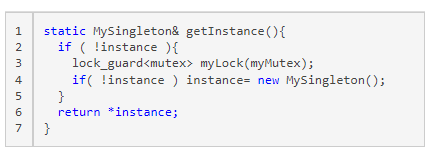
Wrong beliefe exists, that an additional way for the thread safe initialization of a singleton in a multithreading environment is the double-checked locking pattern. The double-checked locking pattern is - in general - an unsafe way to initialize a singleton. It assumes guarantees in the classical implementation, which aren't given by the Java, C# or C++ memory model. The assumption is, that the access of the singleton is atomic.
But, what is the double-checked locking pattern? The first idea to implement the singleton pattern in a thread safe way, is to protected the initialization of the singleton by a lock.
Any issues? Yes and no. The implementation is thread safe. But there is a great performance penalty. Each access of the singleton in line 6 is protected by an expansive lock. That applies also for the reading access. Most time it's not necessary. Here comes the double-checked locking pattern to our rescue.
static MySingleton& getInstance(){
if ( !instance ){
lock_guard<mutex> myLock(myMutex);
if( !instance ) instance= new MySingleton();
}
return *instance;
}
I use inexpensive pointer comparison in the line 2 instead of an expensive lock a. Only if I get a null pointer, I apply the expensive lock on the singleton (line 3). Because there is the possibility that another thread will initialize the singleton between the pointer comparison (line 2) and the lock (line3), I have to perform an additional pointer comparison the on line 4. So the name is clear. Two times a check and one time a lock.
Smart? Yes. Thread safe? No.
What is the problem? The call instance= new MySingleton() in line 4 consists of at least three steps.
Allocate memory forMySingleton
Create theMySingletonobject in the memory
Letinstancerefer to theMySingletonobject
The problem: there is no guarantee about the sequence of these steps. For example, out of optimization reasons, the processor can reorder the steps to the sequence 1,3 and 2. So, in the first step the memory will be allocated and in the second step, instance refers to an incomplete singleton. If at that time another thread tries to access the singleton, it compares the pointer and gets the answer true. So, the other thread has the illusion that it's dealing with a complete singleton.
The consequence is simple: program behaviour is undefined.
최적화에 의해서 명령어 순서가 1,3 ,2 순서로 뒤 바뀔 수 있기 때문에 다른 스레드에서 잘못된 instance 포인터를 얻어가게 되어 문제가 발생 할 수 있게 된다
핵심은 Mutex 가 reorder 를 막아주진 못한다는 것!!!
What's next?
At first, I thought, I should continue in thenext postwith the singleton pattern. But to write about the singleton pattern, you should have a basic knowledge of the memory model. So I continue in the sequence of my German blog. The next post will be about-thread local storage. In case we are done with the high end API of multithreading in C++, I'll go further with the low end API.(Proofreader Alexey Elymanov)
atomic<bool> flag = false;
//true 가 나오면 원래 원자적으로 처리 되는거라 lock 할 필요 없음
bool isAtomic = flag.is_lock_free();
//flag.store(true);
flag.store(true, memory_order::memory_order_seq_cst); //위의 한줄과 동일한 연산이다
bool val = flag.load(memory_order::memory_order_seq_cst);
기본 적인 store 와 load 이전에 사용했던 것에서 뒤에 인자를 넣어 줄수 있다는 것
#include "pch.h"
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
#include <future>
#include "windows.h"
using namespace std;
atomic<bool> flag = false;
int main()
{
flag = false;
flag.store(true, memory_order::memory_order_seq_cst); //memory_order_seq_cst 가 위에선 기본으로 들어간다
bool val = flag.load(memory_order::memory_order_seq_cst);
{
bool prev = flag; //이렇게 하면 만약 다른 쓰레드에서 flag 값을 중간에 바꾸면 prev 는 falg 과 동일한 값이 아닐 수도 있게된다
flag = true;
}
//위의 것을 원자적으로 한번에 변경 하려면 다음 처럼 하면 된다
{
//이렇게 한번에 처리하는 atomic 의 함수를 사용 하면 된다
bool prev = flag.exchange(true);
}
//cas (compare-and-swap) 조건부 수정
{
bool expected = false;
bool desired = true;
flag.compare_exchange_strong(expected, desired); //현재 값이 기대한 값과 같다면 희망하는 값으로 바꿔주는 함수
}
{
bool expected = false;
bool desired = true;
flag.compare_exchange_weak(expected, desired); //동작은 compare_exchange_strong 과 같은데 spruious failure 가 발생 할 수 있다
//즉 이 함수 내에서 다른 스레드의 Interruption 을 받아서 값 변경이 중간에 실패 할 수 있음
//lock 해야 하는데 다른곳에서 먼저 lock 해서 가짜 wakup 이 일어나 제대로 처리 되지 않는 묘한 상황이 발생 할 수 있다는 것
//compare_exchange_weak 이게 기본적인 형태인데 만약에 이렇게 실패가 일어나면 다시 한번 시도해서 성공할대까지 시도하는게 compare_exchange_strong 이 된다
//compare_exchange_strong 그래서 이게 좀 더 부하가 있을 수 있다
//그래서 compare_exchange_weak 이걸 사용할대는 while 루프를 사용해서 처리 한다, 하지만 성능 차이가 엄청 크게 차이 나진 않는다
}
return 0;
}
compare_exchange_weak 같은 경우
compare_exchange_weak 함수 내에서 if(flag==expected){ 여기 안에서 실패 발생 가능성 } 이런 내부적 유사구문에서 실패를 할수 있기 때문에 가짜기상이 일어날 수 있다 compare_exchange_strong 같은경우는 이 실패가 일어날 경우 성공 할떄까지 반복해서 실행하게 된다
그래서 compare_exchange_weak 은 while 루프와 함께 사용 되어서 성공할때까지 시도 하는 형태로 코드를 작성하게 된다
여기서 중요한것은 seq_cst, acquire, release, acq_rel 이렇게 4개 이다
이 중 acq_rel 이것은 acquire, release 을 합처 놓은 것이다
정리하면..
Sequentianlly Consistent (memory_order_seq_cst) : 가장 엄격 [컴파일러에서 최적화 여지 적음=>코드 직관적] =>코드 재배치 잘 안됨 : 가시성 문제와 코드 재배치 문제가 해결 된다
Acquire-Release (memory_order_acquire, memory_order_release) : 중간 엄격 ex) ready.store(true, memory_order_release); release 명령 이전의 메모리 명령들이, 해당 명령 이후로 재배치 되는 것을 막는다 => 즉 재배치 억제 ready.store(true,memory_order_acquire); // acquire 로 같은 변수를 읽는 쓰레드가 있다면 release 이전의 명령들이 ->acqurie 하는 순간에 관찰 가능하다(가시성 보장) 즉 memory_order_release와 memory_order_relase 이전의 내용들이 memory_order_acquire 한 이후의 가시성이 보장이 된다는 얘기, 다시 말해 memory_order_release이전에 오는 모든 메모리 명령들이 memory_order_acquire 한 이후의 해당 쓰레드에 의해서관찰될 수 있어야 합니다.
Relaxed (memory_order_relaxed) : 사용할 일이 거의 없다 자유로워짐 [컴파일러 최적화 여지가 많다 => 코드가 복잡] => 코드 재배치 잘 될 수 있음, 가시성도 해결 되지 못한다 단 동일 객체에 대한 동일 수정 순서만 보장한다 참고 (https://3dmpengines.tistory.com/2198?category=511463)
atomic 은 아무것도 입력하지 않으면 seq_cst 이 기본 버전으로 처리 된다 => 가장 많이 사용 됨
[1]atomic 중에서 memory_order::memory_order_seq_cst
#include "pch.h"
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
#include <future>
#include "windows.h"
using namespace std;
atomic<bool> ready = false;
int32 value;
void producer()
{
value = 10;
//seq_cst를 하게 되면 ready 이 값이 consumer 에서의 ready 에서도 그대로 보이고 재배치문제도 해결됨
// cst 를 하게 되면 value 값이 cst 이후에 정확하게 갱신되어 값이 이후에 보여지게 된다
//releaxed 같은 경우는 재배치로 인해 0이 나올 수도 있다, 대부분 테스트하면 10이 나오긴 하지만..
ready.store(true, memory_order::memory_order_seq_cst);
}
void consumer()
{
while (ready.load(memory_order::memory_order_seq_cst) == false)
;
cout << value << endl;
}
int main()
{
ready = false;
value = 0;
thread t1(producer);
thread t2(consumer);
t1.join();
t2.join();
/*
memory_order_seq_cst 이걸 쓰면 가시성 문제와 코드 재배치 문제가 해결 된다!!!
모든게 정상적으로 작동
*/
return 0;
}
ready.store(true, memory_order::memory_order_seq_cst); 이 한줄에 대해서만
memory_order_seq_cst
memory_order_seq_cst는 메모리 명령의순차적 일관성(sequential consistency)을 보장해줍니다.
순차적 일관성이란, 메모리 명령 재배치도 없고, 모든 쓰레드에서 모든 시점에 동일한 값을 관찰할 수 있는, 여러분이 생각하는 그대로 CPU 가 작동하는 방식이라 생각하면 됩니다.
memory_order_seq_cst를 사용하는 메모리 명령들 사이에선 이러한 순차적 일관성을 보장해줍니다.
memory_order_relaxed : 가장 루즈한 규칙으로 가시성과 코드 재배치가 해결되지 않는다 사실상 거의 쓰이지 않는다
즉 value = 10; ready.store(true, memory_order::memory_order_relaxed);
이 코드가
ready.store(true, memory_order::memory_order_relaxed); value = 10;
이렇게 컴파일 될 수도 있단 얘기임
또 다른 얘시
#include <atomic>
#include <cstdio>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
void t1(std::atomic<int>* a, std::atomic<int>* b) {
b->store(1, memory_order_relaxed); // b = 1 (쓰기)
int x = a->load(memory_order_relaxed); // x = a (읽기)
printf("x : %d \n", x);
}
void t2(std::atomic<int>* a, std::atomic<int>* b) {
a->store(1, memory_order_relaxed); // a = 1 (쓰기)
int y = b->load(memory_order_relaxed); // y = b (읽기)
printf("y : %d \n", y);
}
int main() {
std::vector<std::thread> threads;
std::atomic<int> a(0);
std::atomic<int> b(0);
threads.push_back(std::thread(t1, &a, &b));
threads.push_back(std::thread(t2, &a, &b));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}
성공적으로 컴파일 하였다면 아래와 같은 결과들을 확인할 수 있습니다.
실행 결과
x : 1
y : 0
혹은
실행 결과
x : 0
y : 1
혹은
실행 결과
y : 1
x : 1
을 말이지요.
b->store(1, memory_order_relaxed); // b = 1 (쓰기)
int x = a->load(memory_order_relaxed); // x = a (읽기)
store과load는atomic객체들에 대해서 원자적으로 쓰기와 읽기를 지원해주는 함수 입니다. 이 때, 추가적인 인자로, 어떠한 형태로memory_order을 지정할 것인지 전달할 수 있는데, 우리의 경우 가장 느슨한 방식인memory_order_relaxed를 전달하였습니다.
여기서 잠깐 궁금한게 있습니다. 과연 아래와 같은 결과를 볼 수 있을까요?
실행 결과
x : 0
y : 0
상식적으로는 불가능 합니다. 왜냐하면x, y둘다 0 이 나오기 위해서는x = a와y = b시점에서a와b모두 0 이어야만 합니다. 하지만 위 명령어들이 순서대로 실행된다면 이는 불가능 하다는 사실을 알 수 있습니다.
예를 들어서x에 0 이 들어가려면a가 0 이어야 합니다. 이 말은 즉슨,x = a가 실행된 시점에서a = 1이 실행되지 않았어야만 합니다. 따라서t2에서y = b를 할 때 이미b는 1 인 상태이므로,y는 반드시 1 이 출력되어야 하지요.
하지만, 실제로는 그렇지 않습니다.memory_order_relaxed는 앞서 말했듯이, 메모리 연산들 사이에서 어떠한 제약조건도 없다고 하였습니다. 다시 말해 서로 다른 변수의relaxed메모리 연산은 CPU 마음대로 재배치 할 수 있습니다 (단일 쓰레드 관점에서 결과가 동일하다면).
예를 들어서
int x = a->load(memory_order_relaxed); // x = a (읽기)
b->store(1, memory_order_relaxed); // b = 1 (쓰기)
순으로 CPU 가 순서를 재배치 하여 실행해도 무방하다는 뜻입니다.
그렇다면 이 경우x와y에 모두 0 이 들어가겠네요.memory_order_relaxed는 CPU 에서 메모리 연산 순서에 관련해서 무한한 자유를 주는 것과 같습니다. 덕분에 CPU 에서 매우 빠른 속도로 실행할 수 있게됩니다.
이렇게relaxed메모리 연산을 사용하면 예상치 못한 결과를 나을 수 있지만, 종종 사용할 수 있는 경우가 있습니다.
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
void worker(std::atomic<int>* counter) {
for (int i = 0; i < 10000; i++) {
// 다른 연산들 수행
counter->fetch_add(1, memory_order_relaxed);
}
}
int main() {
std::vector<std::thread> threads;
std::atomic<int> counter(0);
for (int i = 0; i < 4; i++) {
threads.push_back(std::thread(worker, &counter));
}
for (int i = 0; i < 4; i++) {
threads[i].join();
}
std::cout << "Counter : " << counter << std::endl;
}
성공적으로 컴파일 하였다면
실행 결과
Counter : 40000
와 같이 나옵니다. 여기서 중요한 부분은
counter->fetch_add(1, memory_order_relaxed);
로 이는counter ++와 정확히 하는 일이 동일하지만,counter++와는 다르게 메모리 접근 방식을 설정할 수 있습니다. 위 문장 역시 원자적으로counter의 값을 읽고 1 을 더하고 다시 그 결과를 씁니다.
다만memory_order_relaxed를 사용할 수 있었던 이유는, 다른 메모리 연산들 사이에서 굳이counter를 증가시키는 작업을 재배치 못하게 막을 필요가 없기 때문입니다. 비록 다른 메모리 연산들 보다counter ++이 늦게 된다고 하더라도 결과적으로증가 되기만 하면 문제 될게 없기 때문입니다, 그렇다고 이것을 권하는 것은 아님
[2] memory_order_acquire 과 memory_order_release
memory_order_relaxed가 사용되는 경우가 있다고 하더라도 너무나 CPU 에 많은 자유를 부여하기에 그 사용 용도는 꽤나 제한적입니다. 이번에 살펴볼 것들은memory_order_relaxed보다 살짝 더 엄격한 친구들 입니다.
relaxed 로 된ㄷ 아래와 같은producer - consumer관계를 생각해봅시다.
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
void producer(std::atomic<bool>* is_ready, int* data) {
*data = 10;
is_ready->store(true, memory_order_relaxed);
}
void consumer(std::atomic<bool>* is_ready, int* data) {
// data 가 준비될 때 까지 기다린다.
while (!is_ready->load(memory_order_relaxed)) {
}
std::cout << "Data : " << *data << std::endl;
}
int main() {
std::vector<std::thread> threads;
std::atomic<bool> is_ready(false);
int data = 0;
threads.push_back(std::thread(producer, &is_ready, &data));
threads.push_back(std::thread(consumer, &is_ready, &data));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}
아래에data를 읽는 부분과 위is_ready에서 읽는 부분이 순서가 바뀌어 버린다면,is_ready가true가 되기 이전의data값을 읽어버릴 수 있다는 문제가 생깁니다. 따라서 위와 같은 생산자 - 소비자 관계에서는memory_order_relaxed를 사용할 수 없습니다.
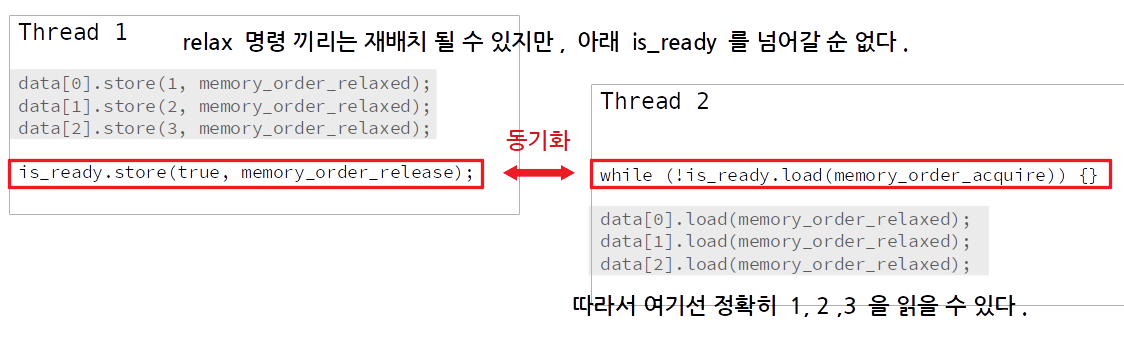
본론으로 돌아와서.. memory_order_release, memory_order_acquire 된 코드
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
void producer(std::atomic<bool>* is_ready, int* data) {
*data = 10;
is_ready->store(true, std::memory_order_release);
//----------------------여기부터 ---------------------------------
//is_ready->store(true, std::memory_order_release); 이코드 위에 있는 것들이
//--------줄 아래로 내려갈 수 없다는 것을 말한다
}
void consumer(std::atomic<bool>* is_ready, int* data) {
// data 가 준비될 때 까지 기다린다.
//memory_order_acquire 는 같은 변수로 읽는 스레드가 있다면 release 이전의 명령들이
//acquire 하는 순간에 관찰 가능하다
//----------------------여기까지 ---------------------------------
//!is_ready->load(std::memory_order_acquire) 아래 있는 명령들이 이 위로 못올라오게 막고
//is_ready->store(true, std::memory_order_release); 이전의 내용들이
//memory_order_acquire 이후에 모두다 값들이 갱신되어 정확히 보여지게 된다
while (!is_ready->load(std::memory_order_acquire))
{
}
std::cout << "Data : " << *data << std::endl;
}
int main() {
std::vector<std::thread> threads;
std::atomic<bool> is_ready(false);
int data = 0;
threads.push_back(std::thread(producer, &is_ready, &data));
threads.push_back(std::thread(consumer, &is_ready, &data));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}
성공적으로 컴파일 하였다면
실행 결과
Data : 10
와 같이 나옵니다. 이 경우data에 0 이 들어가는 일은 불가능 합니다. 이유는 아래와 같습니다.
memory_order_release는해당 명령 이전의 모든 메모리 명령들이 해당 명령 이후로 재배치 되는 것을 금지합니다. 또한, 만약에 같은 변수를memory_order_acquire으로 읽는 쓰레드가 있다면,memory_order_release이전에 오는 모든 메모리 명령들이 해당 쓰레드에 의해서관찰될 수 있어야 합니다.
쉽게 말해is_ready->store(true, std::memory_order_release);밑으로*data = 10이 올 수 없게 됩니다.
또한is_ready가true가 된다면,memory_order_acquire로is_ready를 읽는 쓰레드에서data의 값을 확인했을 때10임을 관찰할 수 있어야하죠.
while (!is_ready->load(std::memory_order_acquire)) {
}
여기서data의 원소들을store하는 명령들은 모두relaxed때문에 자기들 끼리는 CPU 에서 마음대로 재배치될 수 있겠지만, 아래 release 명령을 넘어가서 재배치될 수 는 없습니다.
release - acquire 동기화
따라서consumer에서data들의 값을 확인했을 때 언제나 정확히 1, 2, 3 이 들어있게 됩니다.
[4] memory_order_acq_rel
memory_order_acq_rel은 이름에서도 알 수 있듯이,acquire와release를 모두 수행하는 것입니다. 이는, 읽기와 쓰기를 모두 수행하는 명령들, 예를 들어서fetch_add와 같은 함수에서 사용될 수 있습니다.
Sequentially-consistent Ordering
memory_order_seq_cst 플래그로 설정된 아토믹 객체는memory_order_seq_cst와 마찬가지로 store 이전의 상황이 다른 스레드의 load시 동기화가 되는 기능을 제공한다. 또한 memory_order_seq_cst는 "single total modification order"단일 수정 순서 = 전지적 시점에서 실행된 순서가 모든 아토믹 객체를 사용하는 쓰레드 사이에 동기화된다.
기존 release-acquire 관계를 이용하는 a, b, c, d의 스레드를 실행했을 때 보장하는 것은 다음과 같다.
write_x()에서 x(store) 이전의 문맥= read_x_then_y()의 x(load) 시점의 문맥
write_y()에서 y(store) 이전의 문맥 = read_y_then_x()의 y(load) 시점의 문맥
따라서 실행 결과 값은 다음과 같이 나올 수 있다.
Z 값
전지적 실행 순서
z = 2
a -> b -> c(d) -> d(c)
x,y 결과가 정해진 이후 이기 때문에 c, d의 결과는 순서에 상관없이 같다.
z = 1
a -> c -> b -> d b -> d -> a -> c
쓰레드 c는 y가 0으로 관측되기 때문에 z를 증가시키지 않는다. 혹은 그 반대.
z = 0
CPU 1: a -> c CPU 2: b -> d
이러한 상황은 두 흐름이 다른 CPU에서 일어날 때 발생한다.
z = 0인 상황이 발생하는 이유
CPU의 계산 결과가 항상 메모리에 써지는 것은 아니다. 실제 CPU 명령어들을 빨리 처리하기 위해 메모리에 접근하는 것을 피하기 때문에 캐시에 두었다가 캐시에서 내보내질 때 메모리에 쓰는 방식 write-back을 많이 사용한다. 이런 경우 각 CPU마다 고유한 캐시를 사용할 경우 메모리에 직접 쓰기 전까지는 동기화가 안 되어 있을 수 있다.
기존 release-acquire는 store 이전의 상황이 load 시점에서 보이는 것을 보장하나 그러한 release-acquire 발생 사건이 모든 쓰레드에 보여지는 것은 아니다.
예를 들어서
write_x 와 read_x_and_y 쓰레드가 코어 1 에,
write_y 와 read_y_and_x 쓰레드가 코어 2 에
배치되어 있다고 해봅시다.
코어 1 에서 write x 가 끝나고 load x 를 한 시점에서 x 의 값은 true 겠지요?
근데 acquire-release sync 는 해당 사실이 (x 가 true 라는게) 코어 2 에서도 visible 하다는 것은 보장되지 않습니다.
그쪽 세상에서는 x 가 아직 false 여도 괜찮습니다. 물론 여기서 acquire-release sync 에 위배되는 것은 전혀 없습니다. acquire-release 가 보장하는 것은 store x 전에 무언가 작업을 했다면 load x 할 때 해당 작업이 그 쓰레드에서 보여진다 라는 약속밖에 없죠.
반면 memory_order_seq_cst 는 어떤 아토믹 객체에 대한 실제 수정 순서가 모든 스레드에게 동일하게 보임을 보장한다.
atomoic 객체의 기본 memory_order 플래그의 기본 값은 memory_order_seq_cst이다.
하지만 memory_order_seq_cst 를 사용하게 된다면 해당 명령을 사용하는 메모리 연산들 끼리는 모든 쓰레드에서 동일한 연산 순서를 관찰할 수 있도록 보장해줍니다. 참고로 우리가atomic객체를 사용할 때,memory_order를 지정해주지 않는다면 디폴트로memory_order_seq_cst가 지정이 됩니다. 예컨대 이전에counter ++은 사실counter.fetch_add(1, memory_order_seq_cst)와 동일한 연산입니다.
문제는 멀티 코어 시스템에서memory_order_seq_cst가 꽤나 비싼 연산이라는 것입니다.
인텔 혹은 AMD 의 x86(-64) CPU 의 경우에는 사실 거의 순차적 일관성이 보장되서memory_order_seq_cst를 강제하더라도 그 차이가 그렇게 크지 않습니다. 하지만 ARM 계열의 CPU 와 같은 경우 순차적 일관성을 보장하기 위해서는 CPU 의 동기화 비용이 매우 큽니다. 따라서 해당 명령은 정말 꼭 필요 할 때만 사용해야 합니다.
#include <atomic>
#include <iostream>
#include <thread>
using std::memory_order_seq_cst;
using std::thread;
std::atomic<bool> x(false);
std::atomic<bool> y(false);
std::atomic<int> z(0);
void write_x() { x.store(true, memory_order_seq_cst); }
void write_y() { y.store(true, memory_order_seq_cst); }
void read_x_then_y() {
while (!x.load(memory_order_seq_cst)) {
}
if (y.load(memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x() {
while (!y.load(memory_order_seq_cst)) {
}
if (x.load(memory_order_seq_cst)) {
++z;
}
}
int main() {
thread a(write_x);
thread b(write_y);
thread c(read_x_then_y);
thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
std::cout << "z : " << z << std::endl;
}
위 코드는 memory_order_seq_cst 로 바꾼 코드이다
성공적으로 컴파일 하였다면
실행 결과
z : 2
혹은
실행 결과
z : 1
과 같이 나옵니다.x.store와y.store가 모두memory_order_seq_cst이므로,read_x_then_y와read_y_then_x에서 관찰했을 때x.store와y.store가 같은 순서로 발생해야 합니다. 따라서z의 값이 0 이 되는 경우는 발생하지 않습니다.
즉 다른 CPU 에서
CPU 1: a -> c CPU 2: b -> d
이렇게 돌아도 다른 cpu 에서 상대의 공유 값을 가시적으로 볼 수 있다는것(정확히 볼 수 있다는 것)
thread_1 , thread_2 에서 값을 num 에 쓸때는 한번에 하나 밖에 쓰지 못한다
그런데 다른 스레드에서 값을 계속 관찰 한다고 했을때 value = num.load()
thread_1, thread_2 의 스레드에서 연산이 이뤄지고 있어서 서로 다른 스레드에서 다른 값이 어떻게 수정되고 있는지에 대해서는 threadObserver 에서 그 값을 꺼내와서 관찰 할 수가 없다!
하지만 이때 동일한 객체에 대해서 동일한 수정 순서를 관찰 하는 것은 가능하다
A:
B:
변수에 대한 수정 순서가 0 , 2, 1, 5 의 순으로 수정되는 순서를 갖는다고 할때
A 에서 변수 값을 그 당시 현재 관찰할때 0을 관찰한 상황이라 가정한다
시간이 좀 지나서
B: 상태가 되고 화상표 있는 곳 까지 진행 되는 도중에 값을 관찰 할때는 다른 스레드에서는 값이 2로 관찰 될 수도 있고 또는 0으로 관찰 될 수가 있다는 것 (다른 코어 캐시에 의해) 이때 중요한것은 A 에서 이미 값은 0 이였음으로 0 이전에 어떤 값이 있었다면 그 이전으론 당연히 가지 않는다는 것이다, 0 을 포함 미래에 대한 것만 관찰이 가능하다는 것이다
그리고 관찰 되는 값은 B: 시점 기준에서
0 2,1,5
0,2 5
0, 1,5
이렇게 미래에 대한것들로 관찰 될 수가 있다
C++ 의 모든 객체들은수정 순서(modification order)라는 것을 정의할 수 있습니다. 수정 순서라 하는 것은, 만약에 어떤 객체의 값을 실시간으로 확인할 수 있는 전지전능한 무언가가 있다고 하였을 때, 해당 객체의 값의 변화를 기록한 것이라 보면 됩니다. (물론 실제로 존재하지 않고, 가상의 수정 순서가 있다고 생각해봅시다.)
a 의 수정 순서
만약에 위 처럼, 어떤 변수a의 값이 위와 같은 형태로 변화해왔다고 해봅시다.
C++ 에서 보장하는 사실은, 원자적 연산을 할 경우에 모든 쓰레드에서 같은 객체에 대해서 동일한 수정순서를 관찰할 수 있다는 사실입니다.
여기서 강조할 점은순서가 동일하다는 것이라는 점입니다.
쉽게 말해 어떤 쓰레드가a의 값을 읽었을 때, 8 로 읽었다면, 그 다음에 읽어지는a의 값은 반드시 8, 6, 3 중에 하나여야 할 것입니다. 수정 순서를 거꾸로 거슬러 올라가서 5 를 읽는 일은 없습니다.
모든 쓰레드에서 변수의 수정 순서에 동의만 한다면 문제될 것이 없습니다.
이 말이 무슨 말이냐면, 같은 시간에 변수a의 값을 관찰했다고 해서
굳이모든 쓰레드들이 동일한 값을 관찰할 필요는 없다 라는 점입니다.
예를 들어서 정확히 같은 시간에 쓰레드 1 과 2 에서a의 값을 관찰하였을 때
쓰레드 1 에서는 5 를 관찰하고,
쓰레드 2 에서는 8 을 관찰해도 문제될 것이 없습니다.
심지어, 동일한 코드를 각기 다른 쓰레드에서 실행하였을 때, 실행하는 순서가 달라도 (결과만 같다면) 문제가 안됩니다.
쓰레드 간에서 같은 시간에 변수의 값을 읽었을 때 다른 값을 리턴해도 된다는 점은 조금 충격적입니다.
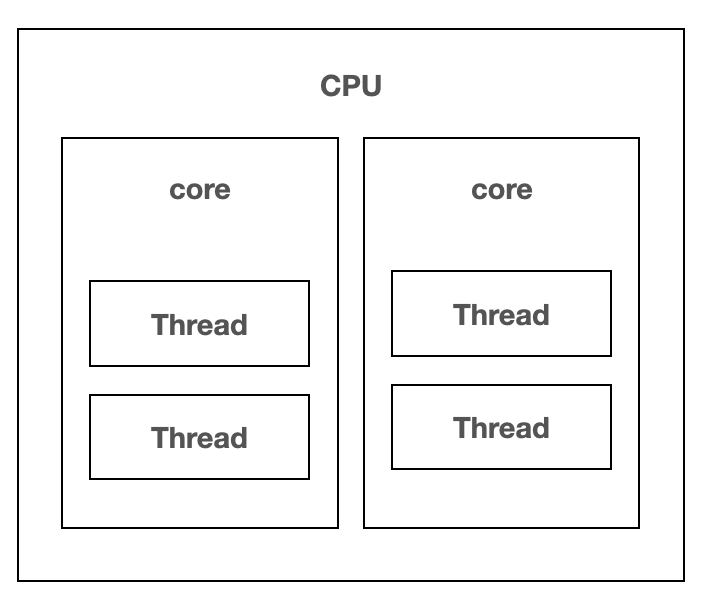
하지만, 이 조건을 강제할 수 없는 이유는 그 이유는 아래 그림 처럼 CPU 캐시가 각 코어별로 존재하기 때문입니다.
보시다시피, 각 코어가 각각 자신들의 L1, L2 캐시들을 갖고 있는 것을 알 수 있습니다.
따라서, 만약에 쓰레드 1 에서 a = 5 을 한 후에 자신들의 캐시에만 기록해 놓고 다른 코어들에게 알리지 않는다면,
쓰레드 3 에서 a 의 값을 확인할 때, 5 를 얻는다는 보장이 없다는 이야기 입니다.
물론, 매번 값을 기록할 때 마다, 모든 캐시에 동기화를 시킬 수 있겠지만동기화작업은 시간을 꽤나 잡아먹는 일입니다. 다행이도, C++ 에서는 로우 레벨 언어 답게, 여러분들이 이를 세밀하게 조정할 수 있는 여러가지 도구들을 제공하고 있습니다.
앞서 이야기 했듯이, C++ 에서 모든 쓰레드들이 수정 순서에 동의해야만 하는 경우는
바로 모든 연산들이 원자적 일 때 라고 하였습니다.
원자적인 연산이 아닌 경우에는 모든 쓰레드에서 같은 수정 순서를 관찰할 수 있음이 보장되지 않기에 여러분이 직접 적절한 동기화 방법을 통해서 처리해야 합니다. 만일 이를 지키지 않는다면, 프로그램이 정의되지 않은 행동(undefined behavior)을 할 수 있습니다. ( 즉 한번에 연산 되어야 하는 것에만 해당 된다는 얘기 )
그렇다면 원자적 이라는 것이 무엇일까요?
이미 이름에서 짐작하셨겠지만, 원자적 연산이란, CPU 가 명령어 1 개로 처리하는 명령으로, 중간에 다른 쓰레드가 끼어들 여지가 전혀 없는 연산을 말합니다. 즉,이 연산을 반 정도 했다는 있을 수 없고 이 연산을했다혹은안 했다만 존재할 수 있습니다. 마치 원자처럼 쪼갤 수 없다 해서원자적(atomic)이라고 합니다.
하지만 원자적 연산 자체가 바로 문제를 해결해 주진 않는다
Atomic 연산은모든 쓰레드가동일 객체에 대해서동일한 수정순서를 관찰 할수 있게 한다는것이 기본 법칙
원자적 Atomic 에 대한 예시를 한번 살펴보자
원자 연산의 특성 1
동일한 수정순서란 무엇인가?
atomic<__int64> num;
void thread_1()
{
num.store(1);
}
void thread_2()
{
num.store(2);
}
//관찰자 스레드로 실시간으로 num 값을 관찰하고 있다고 가정한다
void threadObserver()
{
while (true)
{
//이때 읽어오는 값은 어떻게 되는가?
//atomic 또한 다른 쓰레드에서 값을 스고 있지만 코어당 캐쉬가 별도 있고 cpu 와 캐쉬 간의 연산할때의 값과 램에있는
//값을 threadObserver 에서 관찰할떄의 가시성 때문에
//이 쓰래드에선 순간적으로 num 값이 cpu와 캐쉬에서 현재 연산하고 있는 값과 다를 수 있다
//
//하지만 동일한 수정 순서를 관찰 할수 있는데 이것은 값이 변경 될때 현재와 앞으로의 값중에
//어떤 값이 될지모르지만 그중에 하나를 얻을수 있다는 것인데 과거 것은 안된다는 것
//수정순서는 이런 얘기
__int64 value = num.load();
}
}
while(true)
{
value이때 읽어오는 값은 어떻게 되는가? atomic 또한 다른 쓰레드에서 값을 쓰고 있지만 코어당 캐쉬가 별도 있고 cpu 와 캐쉬 간의 연산할때의 값과 램에있는 값을 threadObserver 에서 관찰할떄의 가시성 때문에 이 쓰래드에선 순간적으로 num 값이 cpu와 캐쉬에서 현재 연산하고 있는 값과 다를 수 있다
하지만 동일한 수정 순서를 관찰 할수 있는데 이것은 값이 변경 될때 현재와 앞으로의 값중에 어떤 값이 될지모르지만 그중에 하나를 얻을수 있다는 것인데 과거 것은 안된다는 것 동일한 수정순서는 이런 얘기
__int64 value = num.load();
원자 연산의 특성 2
C++ 에서는 몇몇 타입들에 원자적인 연산을 쉽게 할 수 있도록 여러가지 도구들을 지원하고 있습니다.
또한 이러한 원자적 연산들은 올바른 연산을 위해 굳이 뮤텍스가 필요하지 않습니다! 즉 속도가 더 빠릅니다.
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
void worker(std::atomic<int>& counter) {
for (int i = 0; i < 10000; i++) {
counter++;
}
}
int main() {
std::atomic<int> counter(0);
std::vector<std::thread> workers;
for (int i = 0; i < 4; i++) {
workers.push_back(std::thread(worker, ref(counter)));
}
for (int i = 0; i < 4; i++) {
workers[i].join();
}
std::cout << "Counter 최종 값 : " << counter << std::endl;
}
void worker(std::atomic<int>& counter) {
가 지역변수인
std::atomic<int> counter(0);
를 받고 공용으로 수정하려고 함으로 atomic 을 사용 한것 (전역 변수로 사용한것과 엇 비슷한 효과)
출력 결과는
Counter 최종 값 : 40000
놀랍게도counter ++;을 아무런 뮤텍스로 보호하지 않았음에도 불구하고, 정확히Counter가40000으로 출력 되었습니다. 원래counter ++을 하기 위해서는 CPU 가 메모리에서counter의 값을 읽고 - 1 더하고 - 쓰는 총 3 개의 단계를 거쳐야만 했습니다. 그런데, 여기서는lock없이도, 제대로 계산하였지요.
그렇다면 컴파일러는 이를 어떻게 원자적 연산으로 만들었을까요? 이를 알기 위해서는 다시 컴파일러가 어떤 어셈블리 코드를 생성했는지 살펴봐야 합니다.
붉은색 테두리가 counter ++ 부분이다.
놀랍게도counter ++부분이 실제로 어셈블리 명령 한 줄인
lock add DWORD PTR [rdi], 1
로 나타남을 알 수 있습니다. 원래 CPU 는 한 명령어에서 메모리에 읽기 혹은 쓰기 둘 중 하나 밖에 하지 못합니다. 메모리에 읽기 쓰기를 동시에 하는 명령은 없습니다. 하지만, 이lock add의 경우rdi에 위치한 메모리를 읽고 - 1 더하고 - 다시rdi에 위치한 메모리에 쓰기를 모두 해버립니다.
참고로 이러한 명령어를 컴파일러가 사용할 수 있었던 이유는 우리가 어느 CPU 에서 실행할 지 (x86) 컴파일러가 알고 있기 때문에 이런 CPU 특이적인 명령어를 제공할 수 있던 것입니다. 물론, CPU 에 따라 위와 같은 명령이 없는 경우도 있습니다.
이 경우 CPU 는 위와 같은 원자적인 코드를 생성할 수 없습니다. 이는 해당atomic객체의 연산들이 과연 정말로 원자적으로 구현될 수 있는지 확인하는is_lock_free()함수를 호출해보면 됩니다. 예를 들어서
cpu 가 어떤 값을 쓰거나 읽을때 램까지 가서 읽어올수도 있는데 이것은 캐쉬에 없을때 얘기다 , 이때 CPU 는 각 코어마다 별도의 캐쉬를 갖고 있는데 실제 램까시 가서 데이터를 불러와서 변수에 쓴건지에 대한 보장이 없을 수 있다 코어와 스레드는(t1) 하나로 묶여서 연산 되고 cpu 에서 캐쉬의 데이터를 연산을 하면서 아직 Ram 에 데이터를 쓰지 않았을 수 있는데 이때 다른 쓰레드(t2)에서 현재 t1 에서 아직 공유변수의 연산중인 값의 최종을 모르고 이전 램에 있는 값만 알기 때문에 값이 정확하게 일치하지 않는다는 문제가 비가시성을 말함
코드 재배치 (https://3dmpengines.tistory.com/2196) = 결과가 동일하다면, 컴파일러가 코들르 보고 더 빠를 것 같으면 코드 순서를 바꿀 수도 있다 이것 때문에 값이 제대로 원하는 값이 아닐 수도 있다, 코드로 보는것과 달리 그런데 이 코드 재배치는 컴파일러 뿐만 아니라 CPU 에서 멋대로 제배치 할 수도 있다
과연 컴파일러만 재배치를 할까?
한 가지 더 재미있는 점은, 꼭 컴파일러만이 명령어를 재배치하는게 아니라는 점입니다. 예를 들어서 다음과 같은 두 명령을 생각해봅시다.
C/C++ 확대 축소
// 현재 a = 0, b = 0;
a = 1; // 캐시에 없음
b = 1; // 캐시에 있음
a = 1의 경우 현재a가 캐시에 없으므로, 매우 오래 걸립니다. 반면에b = 1;의 경우 현재b가 캐시에 있기 때문에 빠르게 처리할 수 있겠지요. 따라서 CPU 에서 위 코드가 실행될 때,b = 1;가a = 1;보다먼저실행될 수 있습니다.
따라서, 다른 쓰레드에서a는 0 인데,b가 1 인 순간을 관찰할 수 있다는 것입니다.
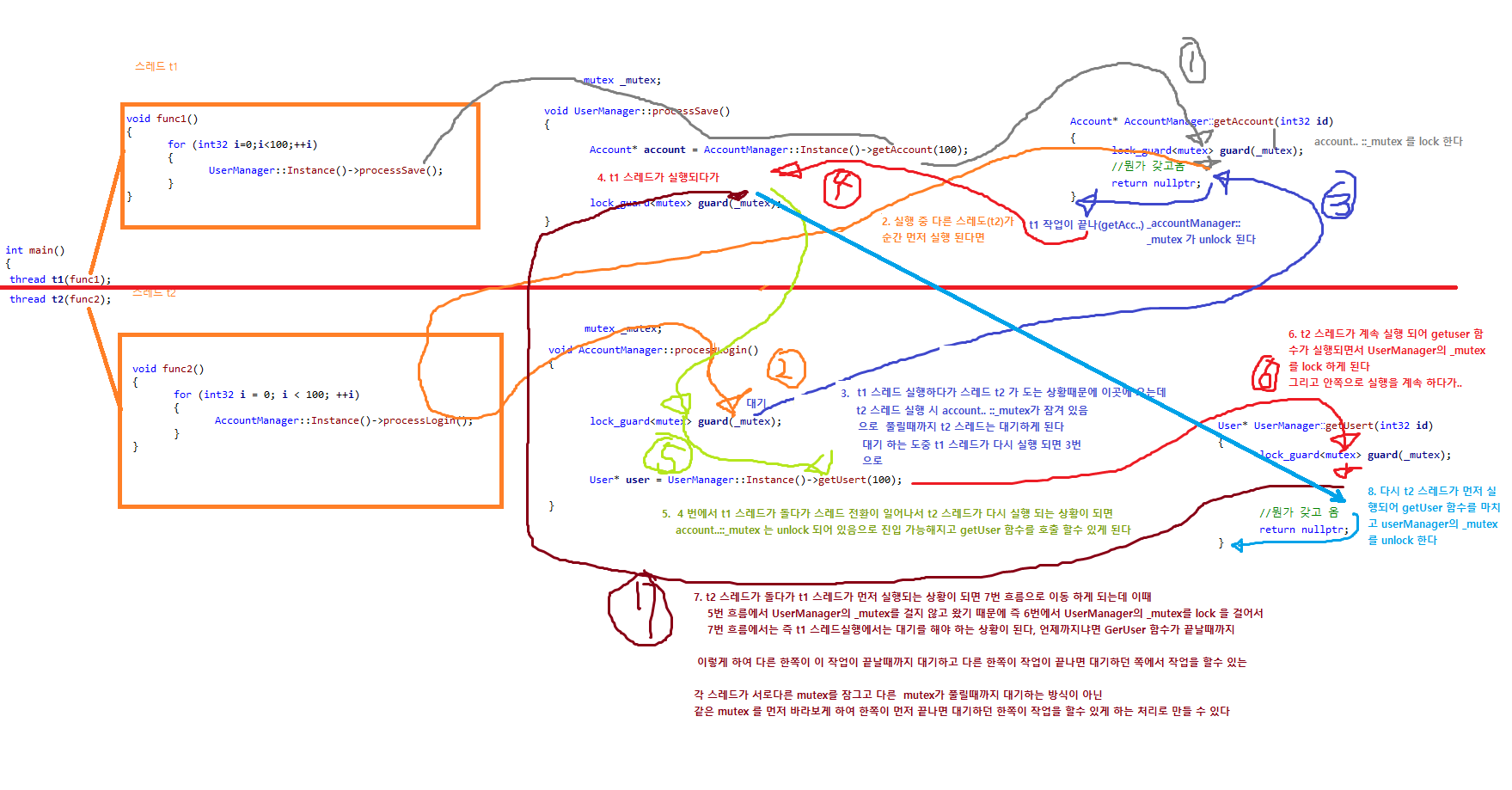
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
#include <chrono>
#include <future>
#include "windows.h"
using namespace std;
int32 x = 0;
int32 y = 0;
int32 r1 = 0;
int32 r2 = 0;
volatile bool ready;
void Thread_1()
{
while (!ready)
{
volatile int i = 39;
i += 10;
}
//가시성 관점으로 봤을때 특정 시점에서 이것 또한 램까지 가서
//y 에 데이터를 썼다는 보장이 없을 수 있다
y = 1; //store y
r1 = x; //load x
}
void Thread_2()
{
while (!ready)
{
volatile int i = 39;
i += 10;
}
x = 1;
//가시성 문제로 봤을때 특정 시점에서 y 는 1이 아닐 수도 있다
r2 = y;
}
int main()
{
int32 count = 0;
while (true)
{
ready = false;
count++;
x = y = r1 = r2 = 0;
thread t1(Thread_1);
thread t2(Thread_2);
ready = true;
t1.join();
t2.join();
if (r1 == 0 && r2 == 0)
{
break;
}
}
std::cout << count << std::endl;
return 0;
}
아래 4개의 빨래 일감이 있는데 빨래 하나만 들고 빨래가 다 끝나면 다리미 하고 건조 하고 여기 까지 완료 된다음 다음빨래를 들고가면 비효율적이니 빨래 하나를 세틱기 하나에 넣고 그다음 빨래도 세틱기에 넣고
앞의 빨래가 끝나면 건조기에 넣고 바로 그다음 빨래를 세틱기에 넣고 하는 식으로 낭비 없이 명령어를 처리 하는것이 CPU 파이프라인이다
그래서 생각해본 방법 중 하나가 한가지 작업을 수행한 후에는 다른 Instruction을 동시에 수행할 수 있게 하자는 아이디어다. 그림으로 표현하면 다음과 같다.
어차피 동시에 같은 작업을 수행하는 게 아니라면 순차적으로 다음 instruction이 수행할 수 있도록 배려하자는 것이다. 이러면 D가 끝나기 까지 걸리는 시간이 앞의 Sequential Execution 방식에 비해 약 절반으로 줄어들게 된다. 마치 이런 방식이 pipeline에 Instruction을 꾸역꾸역 집어넣는 방식같다고 해서 Pipelined Execution 이라고 한다. 꾸역꾸역 집어넣으니 먼저 집어넣은 Instruction은 먼저수행되고 빈틈없이 다음 Instruction이 수행될 것이다. 그러면 맨 앞에서 언급했던 것처럼 세탁기와 건조기가 Time을 Waste하는 일은 없을 것이다. 이걸 Computer에서는 다음과 같이 구현된다.
결론적으로 pipeline을 통해서 추구하고자 했던 바는 한번에 처리할 수 있는 instruction의 수(stage)를 늘림으로써 instruction에 대한 throughput, 즉 정해진 시간동안 instruction을 얼마나 처리할 수 있는지를 높이기 위해서 였다고 할 수 있다. 유의할 것은 한개의 instruction이 처리되는 속도가 증가하는 것이 아니라 동시에 처리할 수 있는 instruction 수를 늘려서 전체 instruction이 처리되는 속도를 증가시키는 효과를 얻는 것이다. 참고로 위의 예시는 MIPS의 5-stage pipelined 구조이고, Pentium 4의 pipeline은 31 stage였다. 그런데 연구결과 무조건 stage만을 늘려서 효율성을 얻기에는 한계가 있어서 다른 부분을 발전시키는 방향으로 발전해가고 있으며, 현재 출시된 core i7의 stage는 16이다.
그런데 각각 빨라마다 걸리는 시간이 다를 수 있어서 어떤걸 먼저 넣고 어떤걸 나중에 넣어야 더빠른 상황이 될 수 있는데 이와 같은 상황이 코드 재배치에 해당한다 (컴파일러와 CPU 에서 명령어를 바꾸는 상황)
CPU 파이프라인은 위 처럼 생겼는데
명령 처리가 명령을 읽어오는 Fetch , 명령을 해석하는 Decode, 명령을 실행하는 Execute, Register Write Back (WB)
이때 명령어를 바꿔서 더 빠르게 동작하게 할수 있다면 바꿔주는 것이 코드 재배치
즉 결과가 동일하다면, 컴파일러가 코들르 보고 더 빠를 것 같으면 코드 순서를 바꿀 수도 있다 이것 때문에 값이 제대로 원하는 값이 아닐 수도 있다, 코드로 보는것과 달리 그런데 이 코드 재배치는 컴파일러 뿐만 아니라 CPU 에서 멋대로 제배치 할 수도 있다
가시성과 원자성 이 두가지를 이해 하면 Multi-thread프로로그램을 작성할 때 무엇을 주의해하는지 명확해진다. 또 다른 표현으로 설명 하자면 단일 Thread 프로그램에서는 가시성과 원자성을 괘념치 않아도 프로그램 작성하는데 문제가 없다. 그렇다고 해서 가시성과 원자성이 Multi-thread를 할 때만 뚜둥 나타나는 개념은 아니라는점 명확히 밝혀둔다. 하드웨어를 설계한 사람들에 의해 만들어진 원래 컴퓨터 내의 구조에 관한 이야기다. 이번 편에서는 지난편에서 설명한 이 두 가지 개념중에 가시성을 좀더 깊게 파고들어보려 한다.
비 가시성(가시성 이슈)
다른 자료나 책을 통해 가시성에 대한 개념을 이해하고 있는 독자라면 필자가 외 비 가시성이라는 반대가 되는 단어를 만들어 썼는지 감이 왔을것이다. 지난 편에도 아래 그림이 등장했는데 다시한번 고찰 해보자.
비 가시성 이슈
각기 다른 Thread 2개는 CPU 1과 CPU2를 할당 받아 공유자원에 해당하는 변수를 연산한다.
이 때 메인 메모리에서 값을 읽어 연산에 사용하는 것이 아니라 가 CPU에 존재하는 Cache에 옮겨놓고 연산을 한다.
그 사이에 다른 쓰레드에서 같은 변수를 대상으로 연산을 한다. 이 때 Thread는 타 Thread가 사용하고 있는 CPU의 Cache상의 값을 알지 못한다. 언제 Cache의 값이 메인 메모리로 쓰여질지도 모른다.
그래서 아래코드를 돌려보면 각각의 Thread가 100회씩 변수를 증가연산을 실시 했는데 200에 휠씬 못 미치는 103 ~ 105쯤이 나타난다. (이 실험 결과는 하드웨어의 성능에 따라 상이 할 수 있으니 참고 바란다.) 만약 동시에 시작하는 Thread가 아닌 순차 처리라면 200이 나와야 하는 현상이다. Cache에 담아서 연산을 하더라도 바로 바로 메모리에 적용을 했으면 200은 아니더라도 180~190정도는 날올것 같은데 너무나도 100가까운 결과에 놀라는 독자도 있을 것이다. 다음 단계에서 이 문제를 조금(?) 해결 해보자.
가시성이란 멀티 코어의캐시(Cache) 간 불일치의 문제를 말하는데, 하나의 스레드에서 특정한 변수의 값을 수정하였는데, 다른 스레드에서 그 수정된 값을 제대로 읽어 들인다는 보장이 없다.
(참고로 C++의 volatile은 JAVA와는 달리 가시성 문제를 해결해주지 않는다. 단순히 컴파일러 최적화를 막기만 함)
* Java 에서 가시성 관련된 이야기 시작 암튼 JAVA에선 위에서 설명한 비 가시성 이슈를 해결하기 위해 JAVA 1.4 부터 volatile을 지원하기 시작 했다. 변수를 선언 할 때 해당 단어를 앞에 써주기만 하면 되는데 이렇게만 해도 위 테스트 코드가 거의 200을 반환한다. (사실 이 결과는 미신같은 이야기다. 정확히 이야기 하면 200이거나 200보다 작은 값을 반환한다.) 원리는 이렇다. Java 에선 volatile로 선언된 변수를 CPU에서 연산을 하면 바로 메모리에 쓴다. (Cache에서 메모리로 값이 이동하는 것을 다른 책이나 문서에서는 flush라고 표현한다.) 그러니 운이 좋게 Thread 두 개가 주거니 받거니 하면서 증가를 시키면 200에 가까운 결과를 얻어내는 것이다. 하지만 개발자라면 이 미신같은 결과에 흡족해 하면 안된다. 필자의 PC를 기준으로 각 Thread당 100회가 아닌 1000회정도 연산을 시키면 2000이 아닌 1998같은 결과를 얻어낸다. 이 이야기인 즉 가시성이 확보된다 하더라도 원자성 문제(동시에 같은 값을 읽어다 증가시키고 flush하는...)로 인해 이와 같은 문제가 생기는 것이다. 이 문제는 원자성 다루면서 해결 해보자. * Java 에서 가시성 관련된 이야기 끝
아래 코드는 자바이지만 제대로 되지 않는 다는 정도만 보면 된다
private int count = 0;
@Test
public void Test_AtomicIssue() {
ExecutorService es = Executors.newFixedThreadPool(2);
es.execute(new ForThreadTest());
es.execute(new ForThreadTest());
es.shutdown();
try {
es.awaitTermination(10, TimeUnit.MINUTES);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("TEST result >>> " + count);
}
class ForThreadTest implements Runnable {
@Override
public void run() {
for(int i = 0 ; i < 100; i++) {
AtomicStampedRefTest.this.count++;
}
}
}
모든 최신 프로세서는 소량의 캐시 메모리를 특징으로 한다. 지난 수십 년 동안 캐시 아키텍처는 점점 더 복잡해졌다. CPU 캐시의 레벨이 증가했고, 각 블록의 크기가 커졌으며, 캐시 연관성도 몇 가지 변화를 겪었다. 자세한 내용을 살펴보기 전에, 메인 메모리와 캐시 메모리의 차이점은 무엇인가? 이미 RAM을 가지고 있는데 왜 소량의 캐시 메모리가 필요하십니까? 한 마디: 속도!
캐시 메모리 대 시스템 메모리: SRAM VS DRAM
캐시 메모리는 훨씬 더 빠르고 비싼 정적 RAM을 기반으로 하며 시스템 메모리는 더 느린 D램(Dynamic RAM)을 활용한다. 두 가지 주요 차이점은 전자가 CMOS 기술과 트랜지스터(블록당 6개)로 만들어진 반면 후자는 콘덴서와 트랜지스터를 사용한다는 점이다.
데이터를 장기간 보존하려면 D램을 지속적으로 새로 고쳐야 한다. 이 때문에 훨씬 더 많은 전력을 소비하고 또한 더 느리게 된다. SRAM은 새로 고칠 필요가 없고 훨씬 더 효율적이다. 그러나 가격이 높아져 주류 채택이 금지되어 프로세서 캐시로 사용이 제한되고 있다.
프로세서에서 캐시 메모리의 중요성?
현대의 프로세서는 80년대와 90년대 초반의 원시 조상들보다 몇 년 앞선다. 오늘날 대부분의 DDR4 메모리 모듈은 1800MHz 미만으로 정격인 반면, 최고급 소비자 칩은 4GHz 이상에서 작동한다. 그 결과 시스템 메모리가 너무 느려서 CPU를 심하게 늦추지 않고 직접 작업할 수 없다. 캐쉬 메모리가 들어오는 곳이 바로 여기에 있다. 그것은 반복적으로 사용된 데이터의 작은 덩어리를 저장하거나 경우에 따라 그 파일의 메모리 주소를 저장하면서 둘 사이의 중간 역할을 한다.
L1, L2 및 L3 캐시: 차이점은?
현대 프로세서에서 캐시 메모리는 크기를 증가시키고 속도를 감소시키기 위해 L1, L2, L3 캐시의 세 부분으로 나뉜다. L3 캐시는 가장 크고 가장 느리다(3세대 Ryzen CPU는 최대 64MB의 L3 캐시를 특징으로 한다). L2와 L1은 L3보다 훨씬 작고 빠르며 각 코어에 대해 분리되어 있다. 구형 프로세서에는 3단계 L3 캐시가 포함되지 않았으며 L2 캐시와 직접 상호 작용하는 시스템 메모리:
L1 캐시는 L1 데이터 캐시와 L1 명령 캐시의 두 가지 섹션으로 더 세분된다. 후자는 CPU에 의해 실행되어야 하는 지시사항을 포함하고 전자는 메인 메모리에 다시 기록될 데이터를 보유하는 데 사용된다.
L1 캐시는 명령 캐시 역할을 할 뿐만 아니라 사전 디코드 데이터와 분기 정보도 가지고 있다. 또한 L1 데이터 캐시가 출력 캐쉬 역할을 하는 경우가 많지만 명령 캐시는 입력 캐쉬처럼 동작한다. 이는 필요한 지침이 가져오기 장치 바로 옆에 있으므로 루프가 체결될 때 유용하다.
최신 CPU는 플래그십 프로세서의 경우 최대 512KB의 L1 캐시(코어당 64KB)를 포함하며 서버 부품은 거의 두 배나 많은 기능을 한다.
L2 캐시는 L1보다 훨씬 크지만 동시에 느리다. 플래그십 CPU에서 4~8MB(코어당 512KB)로 다양하다.
각 코어는 자체 L1 및 L2 캐시를 가지고 있으며, 마지막 레벨인 L3 캐시는 모든 코어에 걸쳐 공유된다.
L3 캐시는 가장 낮은 수준의 캐시다. 10MB에서 64MB까지 다양하며, 서버 칩은 256MB의 L3 캐시를 특징으로 한다. 더욱이 AMD의 라이젠 CPU는 경쟁사인 인텔 칩에 비해 캐시 크기가 훨씬 크다. 인텔 측의 MCM 디자인 대 모놀리성 때문이다. 자세한 내용은 여기를 참조하십시오.(https://www.flayus.com/55228516
)
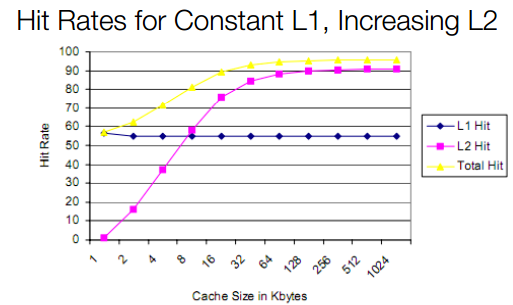
CPU가 데이터를 필요로 할 때, 먼저 관련 코어의 L1 캐시를 검색한다. 발견되지 않으면 다음에 L2와 L3 캐시가 검색된다. 필요한 자료가 발견되면 캐시히트라고 한다. 한편, 캐시에 데이터가 없을 경우 CPU는 메인 메모리나 스토리지에서 캐시에 로딩되도록 요청해야 한다. 이것은 시간이 걸리고 성능에 악영향을 미친다. 이것을 캐시 미스라고 한다.
일반적으로 캐시 크기가 증가하면 캐시 적중률이 향상된다. 특히 게임 및 기타 지연 시간에 민감한 워크로드의 경우 더욱 그러하다.
메모리 매핑
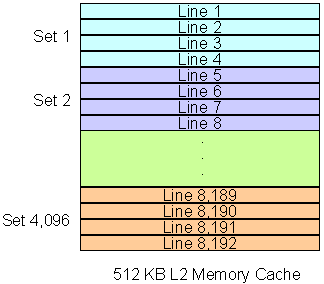
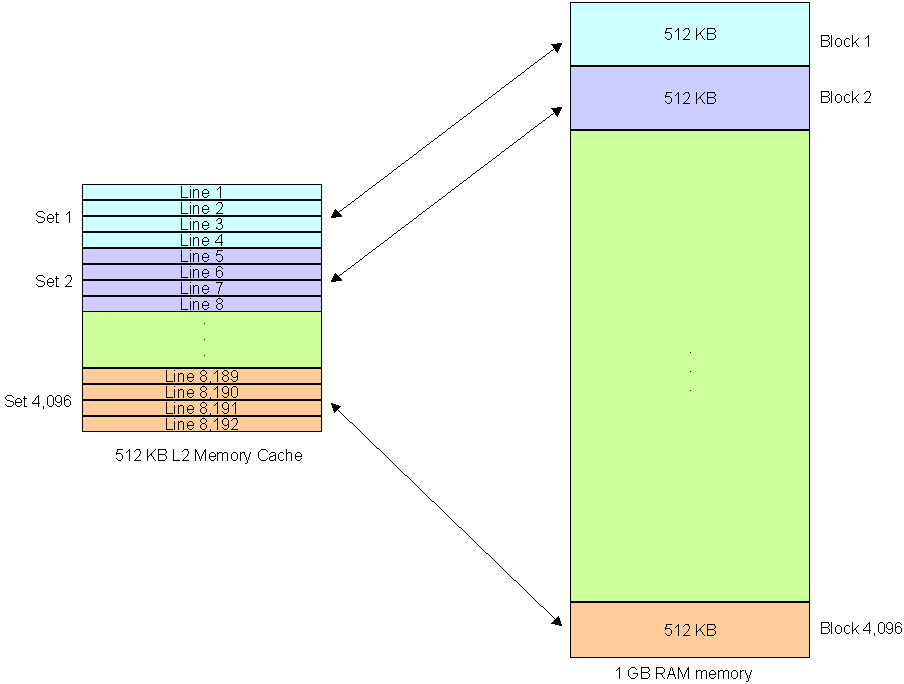
기본적인 설명은 생략하고, 시스템 메모리가 캐시 메모리와 어떻게 대화하는지에 대해 이야기해 보자. 캐시 메모리는 블록으로 나뉜다. 이 블록들은 n개의 64바이트 선으로 나누어 회전하고 있다.
시스템 메모리는 캐시와 동일한 수의 블록으로 나뉘고 그 다음 두 개가 연결된다.
1GB의 시스템 RAM이 있으면 캐시는 8192줄로 나뉘고 블록으로 분리된다. 이것을 n-way 연관 캐시라고 한다. 2방향 연관 캐시의 경우, 각 블록에는 각각 2개의 선이 있으며, 4방향에는 각각 4개, 8방향에는 8개, 16개 라인이 포함되어 있다. 총 RAM 크기가 1GB인 경우 메모리의 각 블록 크기는 512KB가 된다.
512KB의 4방향 관련 캐시가 있는 경우, RAM은 2,048개의 블록(1GB의 경우 8192/4)으로 나뉘며 동일한 수의 4라인 캐시 블록에 연결된다.
16방향 연관 캐시와 동일한 방식으로, 캐시는 메모리의 512(2048KB) 블록에 연결된 512개의 블록으로 나뉘며, 각 캐시 블록은 16개의 선을 포함한다. 캐시에 데이터 블록이 부족하면 캐시 컨트롤러는 프로세서 실행을 계속하는 데 필요한 데이터가 포함된 새로운 블록 집합을 다시 로드한다.
N-way 연관 캐시는 가장 일반적으로 사용되는 매핑 방법이다. 직접 매핑과 완전히 연관된 매핑으로 알려진 두 가지 방법이 더 있다. 전자에서는 캐시 라인과 메모리 사이에 하드 링크가 있는 반면 후자의 경우 캐시는 어떤 메모리 주소도 포함할 수 있다. 기본적으로 각 라인은 어떤 메인 메모리 블록에도 접근할 수 있다. 이 방법은 적중률이 가장 높다. 하지만, 구현하는 것은 비용이 많이 들고 대부분 반도체 제조업체들이 피한다.
기본적으로 CPU 와 컴퓨터 메모리인 RAM 은 물리적으로 떨어져 있습니다. 따라서 CPU 가 메모리에서 데이터를 읽어 오기 위해서는 꽤 많은 시간이 걸립니다. 실제로, 인텔의 i7-6700 CPU 의 경우 최소 42 사이클 정도 걸린다고 보시면 됩니다. CPU 에서 덧셈 한 번을 1 사이클에 끝낼 수 있는데, 메모리에서 데이터 오는 것을 기다리느라, 42 번 덧셈을 연산할 시간을 놓치게 되는 것입니다.
이는 CPU 입장에 굉장한 손해가 아닐 수 없습니다. 메모리에서 데이터 한 번 읽을 때 마다 42 사이클 동안 아무것도 못한다니 말입니다.
이래서 캐시가 존재하는 것
cache
1) Temporal Locality : 방금 사용한것을 또 사용할 확률이 높다는 것
2) Spatial Locality : 한번 사용한 메모리 근방에의 것들 다시 사용할 확률이 높다는 것
future, async 는 mutex, condition variable 까지 쓰지 않고 단순한 쓰레드 처리시 유용하다
1회성 사용시에 유용
ex)파일로딩
1) async : 원하는 함수를 비동기적으로 실행
2) promise : 결과물을 promise를 통해 future 를 통해 받아줌
3) packged_task : 원하는 함수의 실행 결과를 packged_task를 통해 future 로 받아 줌
2,3은 비슷하다
비동기 != 멀티쓰레드
단지 용어 상의 차이인데 비동기는 나중에 함수를 호출하는 개념
즉 지연 호출의 개념이 있어서 완전 멀티 스레드라고 할 수는 없다
wait_for
연결된 비동기 작업이 완료되거나 지정된_Rel_time시간이 경과할 때까지 차단합니다.
구문
C++복사
template <
class _Rep,
class _Period
>
std::future_status::future_status wait_for(
const std::chrono::duration< _Rep, _Period>& _Rel_time ) const;
매개 변수
_Rep 틱 수를 나타내는 산술 형식입니다.
_Period 틱당 경과된 시간(초)을 나타내는 std::ratio입니다.
_Rel_time 작업이 완료될 때까지 대기하는 최대 시간입니다.
반환 값
HRESULT = NO_ERROR를
std::future_status::deferred연결된 비동기 작업이 실행되고 있지 않으면
std::future_status::ready연결된 비동기 작업이 완료된 경우
std::future_status::timeout지정된 기간이 경과된 경우
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
#include <chrono>
#include <future>
#include "windows.h"
using namespace std;
int64 calculate()
{
int64 sum = 0;
for (int32 i = 0; i < 100'000; ++i)
{
sum += 1;
}
return sum;
}
int main()
{
{
//비 동기 호출, calculate 가 호출
std::future<int64> future = std::async(std::launch::async, calculate);
std::future_status status = future.wait_for(1ms); //1밀리 세컨동안 대기했다가 상태를 얻어와서
//지금 스레드의 상태가 어떤 상태인지 알 수 있다
//std::future_status::ready, std::future_status::deferred, std::future_status::timeout
/*
* std::future_status::deferred 연결된 비동기 작업이 실행되고 있지 않으면
std::future_status::ready 연결된 비동기 작업이 완료된 경우
std::future_status::timeout 지정된 기간이 경과된 경우
*/
if(status == std::future_status::ready) //ready 면 일감이 완료 된상태
{
}
int64 sum = future.get(); //get 을 만나면 이때까지 스레드가 실행 안됐다면 대기했다가 결과 반환
}
return 0;
}
ready 면 일감이 완료된 상태
future.wait() == wiat_for 를 무한정 기다리는 상태
//비 동기 호출, calculate 가 호출
std::future<int64> future = std::async(std::launch::async, calculate);
//std::future_status status = future.wait_for(1ms); //1밀리 세컨동안 대기했다가 상태를 얻어와서
future.wait(); //wiat_for 를 무한정 기다리는 상태
//그래서 wait 을 했다가 결과를 호출하나 아래에서 get 을 호출하나 결과는 같다
int64 sum = future.get(); //get 을 만나면 이때까지 스레드가 실행 안됐다면 대기했다가 결과 반환
wiat_for 추가 설명
future 는 thread에서 연산된 결과 값을 전달 받기 위해 사용된다.
wait() / get()은 thread에서 return 또한 set_value() 함수가 호출될 때까지 무한정 대기한다.
wait_for()를 사용하면 일정 시간만큼 thread에서 값이 전달되기 기다리다, timout이 되면 block 상태가 해제된다.
#include <iostream>
#include <future>
#include <thread>
#include <chrono>
int main()
{
std::future<int> future = std::async(std::launch::async, [](){
std::this_thread::sleep_for(std::chrono::seconds(3));
return 8;
});
std::cout << "waiting...\n";
std::future_status status;
do {
status = future.wait_for(std::chrono::seconds(1));
if (status == std::future_status::deferred) {
std::cout << "deferred\n";
} else if (status == std::future_status::timeout) {
std::cout << "timeout\n";
} else if (status == std::future_status::ready) {
std::cout << "ready!\n";
}
} while (status != std::future_status::ready);
std::cout << "result is " << future.get() << '\n';
}
std::launch::async 정책으로 async()를 수행하는데, lamda 표현식을 사용하여 thread를 생성하였다. ( 3초를 sleep하고 8을 return )
std::future_status status;
do {
status = future.wait_for(std::chrono::seconds(1));
if (status == std::future_status::deferred) {
std::cout << "deferred\n";
} else if (status == std::future_status::timeout) {
std::cout << "timeout\n";
} else if (status == std::future_status::ready) {
std::cout << "ready!\n";
}
} while (status != std::future_status::ready);
이 섹션에서 핵심 코드라고 할 수 있다.
wait_for() 함수는 아래와 같은 return 값을 가진다.
wait_for()에서 second(1)을 전달하여 1초 대기하도록 선언하였다. 앞서 본 thread에서 3초 sleep 후 8을 return 하기에
do - while 1번째에는 timeout이 발생하게된다.(timeout 로그 출력)
이후 do - while 조건문에서 status가 ready가 아니므로, 다시 wait_for() 함수가 호출된다. thread는 아직 3초가 지나지 않았기에 다시 한번 timeout이 발생한다.(timeout 로그 출력)
다시 do - while 3번째에서 wait_for() 함수가 호출되어 1초를 wait하게 되는데, 이제는 thread가 3초 sleep에서 깨어나 8을 return 하게 된다.
그래서 wait_for() 함수는 ready를 리턴하게 된다.
do - while 문에서 status가 ready가 되어 do - while문을 빠져 나와 get() 함수를 통해 8을 출력하게 된다.
클래스 인스턴스와 멤버 함수 호출 시
class ABC
{
public :
int64 getalph() {
return 10;
}
};
ABC abc;
std::future<int64> future2 = std::async(std::launch::async, &ABC::getalph, abc);
auto result = future2.get();
결과는 10
std::promise 와 std::future 조합
스레드 만들고 전역변수 만들어 데이터 전달하기 보단 스레드 함수에서 데이터를
assign 하여 스래드 대기하는 쪽에서 데이터를 받아 볼 수 있는 기법
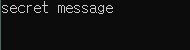
void promiseWorker(std::promise<string>&& promise)
{
promise.set_value("secret message");
}
main 함수 중....
{
//아래 코드처럼 작성하면
//promise 에서 future 를 얻어올 수 있음
//만약 promise 에 어떤 데이트를 세팅하면
//future 에서 데이터를 얻어올 수 있음
//미래에 결과물을 반환해달라는 일종의 약속(promise) 하는 것
std::promise<string> promise;
std::future<string> future = promise.get_future();
//여기 까지 설정한다음
//스레드를 만들어 소유권을 넘겨주면
//즉 std::move(promise) 를 promiseWorker 스레드에 인자로 넘겨 준다
thread t(promiseWorker, std::move(promise));
//그리고 위 코드에서
//promise.set_value("secret message");
//를 했음으로 promise 에서 이 데이터를 다음 처럼 받아 올 수 있다
string data = future.get();
std::cout << data;
t.join();
}
promise 에서 future 를 얻어올 수 있음 만약 promise 에 어떤 데이트를 세팅하면 future 에서 데이터를 얻어올 수 있음 미래에 결과물을 반환해달라는 일종의 약속(promise) 하는 것
The following constants denoting individual bits are defined by the standard library:
Constant
Explanation
std::launch::async
the task is executed on a different thread, potentially by creating and launching it first
std::launch::deferred
the task is executed on the calling thread the first time its result is requested (lazy evaluation)
thread 를 굳이 만들지 않고 lock_guard 나 간편하게 비동기로 처리 하고 싶을 때 사용 할 수 있다
ex) 파일 로딩..
std::future 쓰레드 만들때 좀 더 간단한 방식으로 만드는 형태, 간단하게 쓰일 때 유용
calculate 를 async 방식으로 호출 하는 것
대표적으론 두가지 혼합해서 한가지 총 3가지 방식이 있다
std::launch::deffered : 지연된 연산(lazy evaluation)인데 지연해서 실행해라 라는 얘기 get() 를 만날때 실행된다
std::launch::async : 별도의 스레드를 만들어서 실행하라는 것 실제 스레드 개수가 늘어나는것을 Thread 창에서 확인 할수 있다 스레드를 별도로 만들지 않아도 내부적으로 알아서 만들어서 비동기로 실행함 ex) 데이터 파일 로딩시.. get() 함수를 통해 join 같은효과를 낼 수 있으며 결과 값을 반환 받을 수 있다
std::launch::deffered | std::launch::async : 둘 중에 아무거나 골라서 실행 하라는 것
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
#include <chrono>
#include <future>
#include "windows.h"
using namespace std;
int64 calculate()
{
int64 sum = 0;
for (int32 i = 0; i < 100'000; ++i)
{
sum += 1;
}
return sum;
}
int main()
{
{
//std::future 쓰레드 만들때 좀 더 간단한 방식으로 만드는 형태, 간단하게 쓰일 때 유용
//calculate 를 async 방식으로 호출 하는 것
/*
* std::launch::deffered : 지연된 연산(lazy evaluation)인데 지연해서 실행해라 라는 얘기
std::launch::async : 별도의 스레드를 만들어서 실행하라는 것
std::launch::deffered | std::launch::async : 둘 중에 아무거나 골라서 실행 하라는 것
*/
//실제 스레드 개수가 늘어나는것을 Thread 창에서 확인 할수 있다
//스레드를 별도로 만들지 않아도 내부적으로 알아서 만들어서 비동기로 실행함 ex) 데이터 파일 로딩시..
std::future<int64> future = std::async(std::launch::async, calculate); //비 동기 호출, calculate 가 호출 됨
//이후에 다른 코드를 작성하다가
//시간이 지나서 해당 결과를 필요할대 꺼내 올 수 있다
int64 sum = future.get(); //get 을 만나면 이때까지 스레드가 실행 안됐다면 대기했다가 결과 반환
std::future<int64> futureDef = std::async(std::launch::deferred, calculate); //이건 스레드가 아니고 나중에 호출 하겠다는 얘기임
//실제 스레드 개수가 늘어나지 않는 다는 것을 Thread 창에서 확인 할 수 있다
int64 sum2 = futureDef.get(); //이때 실행 됨
}
return 0;
}
condition_variable 은 전통적인 CreateEvent, SetEvet 를 대체하는 방식으로 볼 수 있다
condition_variable 은 멀티 플랫폼에서도 작동하는 표준으로 들어가 있다
condition_variable 은 커널오브젝트인 event 와 유사한것 같지만 유저모드 레벨 오브젝라는 점이 다르다
즉, 동일한 프로그램 내에서만 사용 가능하다
표준 mutex 와 짝지어 사용 가능하다 condition_variable cv;
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic> //멀티 플랫폼에서 작동 가능
#include <vector>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
#include <chrono>
#include <queue>
#include "windows.h"
using namespace std;
mutex m;
queue<int32> q;
//HANDLE handle;
//condition_variable 은 커널오브젝트인 event 와 유사한것 같지만
//유저모드 레벨 오브젝라는 점이 다르다 즉, 동일한 프로그램 내에서만 사용 가능하다
//표준 mutex 와 짝지어 사용 가능하다
condition_variable cv;
void producer()
{
while (true)
{
// 1) lock 을 잡고
//2 공유변수 값 수정 q
//3 lock 을 풀고
//4 조건 변수 통해 다른 스레드에게 통지 (condition variable 로 통지
{
unique_lock<mutex> lock(m); //1. lock 을 잡는다
q.push(100); //2. 공유 값 수정
} //3. lock 을 풀어줌
//::SetEvent(handle); //event 를 signal 상태로 만든다
cv.notify_one(); //SetEvent 대신 notify 를 해줘서 wait 중인 스레드들 중 딱 1개를 깨운다
//this_thread::sleep_for(100ms);
}
}
//q 에 데이터가 있을 때에만 pop 하여 꺼내서 출력하고 q 에 데이터가 없다면 대기하게 된다
void consumer()
{
while (true)
{
//::WaitForSingleObject(handle, INFINITE); //SetEvent 사용시 wait for 이함수로 대기했지만...
//std::cout << "ConSumer 함수" << std::endl;
{
unique_lock<mutex> lock(m); //우선 lock 을 해서 스레드를 한번 block 해줌 (push 나 pop 중 하나만 일어나도록 하기 위함)
cv.wait(lock, []() { return q.empty() == false; }); //조건을 넣어주는데, 조건이 참일 때까지 기다리게 한다
//q가 비어 있으면 결과는 (true == false) => false 인데 wait(false) 로 들어오면 lock 풀고 대기 한다, 즉 스레드가 중지된다
//이렇게 lock 을 풀어줘야 하는 상황이 발생 할 수 있기 때문에 unique_lock 을 써야만 한다, conditional_variable 을 사용할때는
//q가 비어 있지 않으면 결과는 (false == false) => true wait(true) 로 들어오면 빠져나와서 다음 코드를 진행한다
//wait 에 false 가 들어가면 lock풀고 대기
//wait 에 true 가 들어가면 다음 코드 진행
//q가 비어 있다면 => (true==false) => false , wait(false) =>결과적으로 lock 풀고 대기 한다
//q가 차 있다면 => (false==false) => true , wait(true) => 결과적으로 다음 실행해서 데이터 꺼내서 출력
//조건이 맞으면 다음으로 넘어가고 그렇지 않으면 lock을 풀어주고 대기 상태로 전환된다
//lock 을 또 다시 wait 하는 이유는 Spurious wakeup(가짜 기상) 때문인데
//unique_lock<mutex> lock(m); 해서 대기하고 있는 상황에서 다른 스레드에서 notify_one를해서 쓰레드를 깨웠는데
//unique_lock<mutex> lock(m); 과 cv.wait(lock, []() { return q.empty() == false; }); 사이에서 다른곳에서 lock 을 할 수도 있기 때문에
//wait 에서 lock 을 한번더 확인해 주는것인데 그 사이에 다른 스레드가 lock 해버리는 상황을 Spurious wakeup 이라 한다
//condition variable 에서 wait 하는 순간 발생 하는 것들
//1 : lock 을 잡고 ( 만약 wait 위에서 lock 을 잡았다면 wait 에서 다시 lock 을 잡진 않는다
//2 : 조건 확인
//3-1 : 조건 만족 하면 빠젼 나와서 이어서 코드를 진행한다
//3-2 : 조건 만족하지 않으면 lock 을 풀어주고 대기 상태로 전환한다 (=> 경우에 따라서 constant variable 이 unlock 을 해야 하기 대문에 unique_lock 을 사용해야만 함)
//3-2-sub : 3-2 에서 대기 하고 있다가 다른곳에서 notify 를 호출해주면 그때 다시 1번 부터 확인하여 실행 여부가 결정된다
if (q.empty() == false)
{
int32 data = q.front();
q.pop();
cout << data <<"\t"<< q.size() << std::endl;
}
}
this_thread::sleep_for(100ms);
}
}
int main()
{
//커널오브젝트
//Usage Count
//이벤트 속성 : NULL
//auto rest 방식 으로 지정
//초기 값
//이름은 null
//Event 는 유저모드가 아닌 커널모드에서 관리 되는것이기 떄문에 커널단에서 처리된다
//handle = ::CreateEvent(nullptr, true, false, nullptr);
thread t1(producer);
thread t2(consumer);
t1.join();
t2.join();
//::CloseHandle(handle);
return 0;
}
produce 에선 (데이터를 추가해주는 쪽)에선 비교적 간단하게 다음 처럼 처리해 준다
Conditional_variable 의 처리 순서
1) lock 을 잡고 2 공유변수 값 수정 q 3 lock 을 풀고 4 조건 변수 통해 다른 스레드에게 통지 (condition variable 로 통지
이런 프로세스로 추가해주고
Produce 예시를 적용해보자면 이렇게 된다
{ unique_lock<mutex> lock(m); //1. lock 을 잡는다 q.push(100); //2. 공유 값 수정 } //3. lock 을 풀어줌
4. 대기하고 있는 스레드 중에서 스레드들 중 딱 1개만 깨운다 cv.notify_one();
데이터 추가할때 다른 곳에서 쓰는것과 충돌나는 일을 막기 위해 mutex 로 묶어준다
이후 처리가 끝나면 그냥단순 통지만 하고 끝
consumer 에선 다음 처리 처리한다
unique_lock<mutex> lock(m); //우선 lock 을 해서 스레드를 한번 block 해줌 (push 나 pop 중 하나만 일어나도록 하기 위함) cv.wait(lock, []() { return q.empty() == false; }); //조건을 넣어주는데, 조건이 참일 때까지 기다리게 한다
Condition variable 은 다음 특징이 있다
wait(false) 에 false 가 들어가면 lock풀고 대기 wait(true) 에 true 가 들어가면 다음 코드 진행
q가 비어 있다면 => (true==false) => false , wait(false) =>결과적으로 lock 풀고 대기 한다 q가 차 있다면 => (false==false) => true , wait(true) => 결과적으로 다음 실행해서 데이터 꺼내서 출력
Spurious wakeup
lock 을 또 다시 wait 하는 이유는 Spurious wakeup(가짜 기상) 때문인데 unique_lock<mutex> lock(m); 해서 대기하고 있는 상황에서 다른 스레드에서 notify_one를해서 쓰레드를 깨웠는데 unique_lock<mutex> lock(m); 과 cv.wait(lock, []() { return q.empty() == false; }); 사이에서 다른곳에서 lock 을 할 수도 있기 때문에 wait 에서 lock 을 한번더 확인해 주는것(즉 lock 을 한번 더 건다)인데 하지만 그 사이에 다른 스레드가 lock 해버리는 상황이 발생 되면 wait 은 다른곳이 lock 을 했기 때문에 대기 해야 하고 이 것을 Spurious wakeup 즉 가짜 wakeup 이라 한다
다시 정리 하자면 이중으로 unique_lock 에 이어 한번더 wait 에서 lock 을 체크 하는데
unique_lock 과 wait 사이에서 다른 스레드가 lock 을 가져 갈수 있기 때문에 방지 차원에서 wati 에서 lock 을
체크하는 로직이 들어가게 된것이다
Spurious wakeup
Aspurious wakeuphappens when a thread wakes up from waiting on acondition variablethat's been signaled, only to discover that the condition it was waiting for isn't satisfied. It's called spurious because the thread has seemingly been awakened for no reason. But spurious wakeups don't happen for no reason: they usually happen because, in between the time when the condition variable was signaled and when the waiting thread finally ran, another thread ran and changed the condition. There was arace conditionbetween the threads, with the typical result that sometimes, the thread waking up on the condition variable runs first, winning the race, and sometimes it runs second, losing the race.
On many systems, especially multiprocessor systems, the problem of spurious wakeups is exacerbated because if there are several threads waiting on the condition variable when it's signaled, the system may decide to wake them all up, treating everysignal( )to wake one thread as abroadcast( )to wake all of them, thus breaking any possibly expected 1:1 relationship between signals and wakeups.[1]If there are ten threads waiting, only one will win and the other nine will experience spurious wakeups.
To allow for implementation flexibility in dealing with error conditions and races inside the operating system, condition variables may also be allowed to return from a wait even if not signaled, though it is not clear how many implementations actually do that. In the Solaris implementation of condition variables, a spurious wakeup may occur without the condition being signaled if the process is signaled; the wait system call aborts and returnsEINTR.[2]The Linux p-thread implementation of condition variables guarantees it will not do that.[3][4]
Because spurious wakeups can happen whenever there's a race and possibly even in the absence of a race or a signal, when a thread wakes on a condition variable, it should always check that the condition it sought is satisfied. If it is not, it should go back to sleeping on the condition variable, waiting for another opportunity.
가짜 wakeup 로 인해 성능이 악화 되는 상황
가짜 wakeup 의 상황이 되면 현재 돌아가려고 하는 스레드가 우선권을 race 에서 뺐기고 다른 스레드가 계속 가져가게 되서 느려지는데 만약 실행되야 하는 스레드가 있고 다른 스레드 10개가 돌아가고 있다면 이때 레이스를 하면서 실행되야 하는 스레드는 더욱더 지연 될 수 있게 되어 성능이 악화 될 수 있다
waitcauses the current thread to block until the condition variable is notified or a spurious wakeup occurs, optionally looping until some predicate is satisfied (bool(stop_waiting())==true).
예제
#include <iostream>
#include <condition_variable>
#include <thread>
#include <chrono>
std::condition_variable cv;
std::mutex cv_m; // This mutex is used for three purposes:
// 1) to synchronize accesses to i
// 2) to synchronize accesses to std::cerr
// 3) for the condition variable cv
int i = 0;
void waits()
{
std::unique_lock<std::mutex> lk(cv_m);
std::cerr << "Waiting... \n";
cv.wait(lk, []{return i == 1;});
std::cerr << "...finished waiting. i == 1\n";
}
void signals()
{
std::this_thread::sleep_for(std::chrono::seconds(1));
{
std::lock_guard<std::mutex> lk(cv_m);
std::cerr << "Notifying...\n";
}
cv.notify_all();
std::this_thread::sleep_for(std::chrono::seconds(1));
{
std::lock_guard<std::mutex> lk(cv_m);
i = 1;
std::cerr << "Notifying again...\n";
}
cv.notify_all();
}
int main()
{
std::thread t1(waits), t2(waits), t3(waits), t4(signals);
t1.join();
t2.join();
t3.join();
t4.join();
}
Possible output:
Waiting...
Waiting...
Waiting...
Notifying...
Notifying again...
...finished waiting. i == 1
...finished waiting. i == 1
...finished waiting. i == 1
한쪽에선 클라이언트 데이터를 수신 받아와서 q에 밀어넣고 게임 패킷과 관련된 스레드에서 q에서 데이터를 추출해오는 상황이라 가정하여 이를 작성하면 다음 코드 처럼 되고
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic> //멀티 플랫폼에서 작동 가능
#include <vector>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
#include <chrono>
#include <queue>
#include "windows.h"
using namespace std;
mutex m;
queue<int32> q;
//한쪽에선 클라이언트 데이터를 수신 받아와서 q에 밀어넣고
//게임 패킷과 관련된 스레드에서 q에서 데이터를 추출해오는 상황이라 가정
void producer()
{
while (true)
{
{
unique_lock<mutex> lock(m);
q.push(100);
}
this_thread::sleep_for(100ms);
}
}
void consumer()
{
while (true)
{
{
unique_lock<mutex> lock(m);
if (q.empty() == false)
{
int32 data = q.front();
q.pop();
cout << data << std::endl;
}
}
this_thread::sleep_for(100ms);
}
}
int main()
{
thread t1(producer);
thread t2(consumer);
t1.join();
t2.join();
return 0;
}
결과는 100ms 마다 q 에 데이터를 push 하고 consumer 함수에 데이터를 꺼내다 쓰는 상황이 된다
하지만 만야겡 입력이 엄청 긴시간 동일 일어나지 않고 어쩌다 한번씩 입력이 일어난다고 하면
consumer 스레드는 계속 lock 과 unlock 을 반복하고 있긴 하기 때문에 이 부분에 스레드가 차이하는 비용이 그냥 이 코드만 보면 높진 않지만 이런게 많이 쌓이면 성능에 좋지 않음으로 이 부분을 event 를 고려하여 처리 하면
더 효율적으로 작업 할 수 있다
현재는 테스트 pc 가 좋아서 이후 테스트 결과와 크게 차이가 없는 cpu 점유율 0 % 인데
성능이 낮은 PC 일 수록 이것이 8~10% 까지도 올라 갈 순 있다
처리 방식 : 데이터가 q 에 있는 상황 즉 consume 해도 되는 상황에서 consumer 스레드가 돌도록 한다
Event 는 유저모드가 아닌 커널모드에서 관리 되는것이기 떄문에 커널단에서 처리된다
//이벤트 속성 : NULL //auto rest 방식 으로 지정 //초기 값 //이름은 null //Event 는 유저모드가 아닌 커널모드에서 관리 되는것이기 떄문에 커널단에서 처리된다
handle = ::CreateEvent(nullptr, false, false, nullptr); //non-signal 상태
handle 이 물고 있는건 커널오브젝트인데 커널에서 관리하는 이벤트 오브젝트라 보면 된다
커널오브젝트에는 Usage Count = 이 오브젝트를 몇명이 사용하고 있는지
그리고 Signal / Non-Signal 두가지 중 하나의 상태를 갖고 있다 (bool)
true 명 Signal 상태
자동모드/수동모드 에 대한 정보(이벤트는 자동모드 수동모드가 있다)
(자동모드 : 이벤트를 바로 리셋 해주는 모드)
SetEvent(handle) 하면 Signla 상태가 된다
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic> //멀티 플랫폼에서 작동 가능
#include <vector>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
#include <chrono>
#include <queue>
#include "windows.h"
using namespace std;
mutex m;
queue<int32> q;
HANDLE handle;
//한쪽에선 클라이언트 데이터를 수신 받아와서 q에 밀어넣고
//게임 패킷과 관련된 스레드에서 q에서 데이터를 추출해오는 상황이라 가정
void producer()
{
while (true)
{
{
unique_lock<mutex> lock(m);
q.push(100);
}
::SetEvent(handle); //event 를 signal 상태로 만든다
this_thread::sleep_for(100ms);
}
}
void consumer()
{
while (true)
{
//무한 대기, handle 가 Signal 상태가 될때까지
::WaitForSingleObject(handle, INFINITE); //evet 가 signal 상태가 되면 빠져나옴 이 함수를
//즉 WaitForSingleObject 를 만나면 이 쓰레드는 wake up 되지 않고 즉 실행 되지 않고 수면 상태(sleep)로 빠져서 잠들게 된다
//WaitForSingleObject 에 걸린 이벤트는 handle 자동모드라 WaitForSingleObject 이 함수가 실행된고 빠져나오는 즉시 event 가 non-signal 이 된다
std::cout << "ConSumer 함수" << std::endl;
{
unique_lock<mutex> lock(m);
if (q.empty() == false)
{
int32 data = q.front();
q.pop();
cout << data << std::endl;
}
}
this_thread::sleep_for(100ms);
}
}
int main()
{
//커널오브젝트
//Usage Count
//이벤트 속성 : NULL
//auto rest 방식 으로 지정
//초기 값
//이름은 null
//Event 는 유저모드가 아닌 커널모드에서 관리 되는것이기 떄문에 커널단에서 처리된다
handle = ::CreateEvent(nullptr, false, false, nullptr);
thread t1(producer);
thread t2(consumer);
t1.join();
t2.join();
::CloseHandle(handle);
return 0;
}
무한 대기, handle 가 Signal 상태가 될때까지 ::WaitForSingleObject(handle, INFINITE); //evet 가 signal 상태가 되면 빠져나옴 이 함수를 즉 WaitForSingleObject 를 만나면 이 쓰레드는 wake up 되지 않고 즉 실행 되지 않고 수면 상태(sleep)로 빠져서 잠들게 된다, 즉 필요 없는 스레드가 돌아가지 않게 효율을 올릴 수 있다
WaitForSingleObject 에 걸린 이벤트는 handle 자동모드라 WaitForSingleObject 이 함수가 실행된고 빠져나오는 즉시 event 가 non-signal 이 된다
결과 또한 데이터가 있을때 Consumer 를 통해 소진 되는 것을 얼추 알 수 있다
즉 데이터가 있을때 Comsumer 함수가 실행 되도록 evet 로 실행 순서를 제어한 것
이렇게 처리 하면 CPU 점유율이 0 % 대로 떨어지는 것을 알 수 있다
결과는 같고 아래는 Event 가 수동모드이다
wait.. 을 빠져나온 다음 바로 ResetEvent(handle); 을 처리 해주면 자동모드와 동일하다
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic> //멀티 플랫폼에서 작동 가능
#include <vector>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
#include <chrono>
#include <queue>
#include "windows.h"
using namespace std;
mutex m;
queue<int32> q;
HANDLE handle;
//한쪽에선 클라이언트 데이터를 수신 받아와서 q에 밀어넣고
//게임 패킷과 관련된 스레드에서 q에서 데이터를 추출해오는 상황이라 가정
void producer()
{
while (true)
{
{
unique_lock<mutex> lock(m);
q.push(100);
}
::SetEvent(handle); //event 를 signal 상태로 만든다
this_thread::sleep_for(100ms);
}
}
void consumer()
{
while (true)
{
//무한 대기, handle 가 Signal 상태가 될때까지
::WaitForSingleObject(handle, INFINITE);
::ResetEvent(handle);
std::cout << "ConSumer 함수" << std::endl;
{
unique_lock<mutex> lock(m);
if (q.empty() == false)
{
int32 data = q.front();
q.pop();
cout << data << std::endl;
}
}
this_thread::sleep_for(100ms);
}
}
int main()
{
//커널오브젝트
//Usage Count
//이벤트 속성 : NULL
//auto rest 방식 으로 지정
//초기 값
//이름은 null
//Event 는 유저모드가 아닌 커널모드에서 관리 되는것이기 떄문에 커널단에서 처리된다
handle = ::CreateEvent(nullptr, true, false, nullptr);
thread t1(producer);
thread t2(consumer);
t1.join();
t2.join();
::CloseHandle(handle);
return 0;
}
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic> //멀티 플랫폼에서 작동 가능
#include <vector>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
#include <chrono>
using namespace std;
mutex m1;
int32 sum = 0;
class SpinLock
{
public:
void lock()
{
bool expected = false;
bool desired = true;
//_locked 값이 기대 하는 값과 같으면 계속 무한 루프를 돌면서 spinlock 으로 계속 대기 하고, 그렇지 않고 expected 값이 locked 다르면
//내부적으로 _locked 값을 desired 값으로 바꾼다음 while 을 탈출해 spinlock 에서 빠져나오게 한다
while (_locked.compare_exchange_strong(expected, desired) == false)
{
//expected = false; 이렇게 설정해주면 locked 를 얻을 때까지 무한 대기 하게 되는데 cpu 를 사용하면서,
expected = false; //compare_exchange_strong 내부에서 expected 값을 & 로 바꾸기 때문에 원래 초기 상태로 바꾼다
this_thread::sleep_for(100ms); //100 ms 동안 sleep 하도록 함 => 이렇게 하면 cpu 파워를 낭비 하지 않고 context switch 된 이후에 일정 시간이후에 다시 와서 locked 를 획을 할 수 있을지 확인하게 되어
//무한 cpu 자원을 사용하는건 막을 수 있지만 , 다시 돌아왔을때 이미 다른 스레드에서 lock 을 얻어 갔다면 일정 시간이후에 다시 돌아온 스레드는 또다시 wait 해야 하는상황이 발생되게 되는 악순환이 될 수도 있다
//this_thread::yield(); // ==this_thread::sleep_for(0ms); 이것과 동일하다
//이렇게 되면 엄밀히 말하면 spinlock 이 되는것은 아니다
}
}
void unlock()
{
_locked.store(false); //bool 을 바꾸는 것도 또한 원자적으로 일어나야함
}
volatile atomic<bool> _locked = false; //bool 값도 그냥 바꾸면 명령어가 두개로 처리됨
};
SpinLock spinLock;
void func1()
{
for (int32 i=0;i<10000;++i)
{
lock_guard<SpinLock> guard(spinLock);
sum++;
}
}
void func2()
{
for (int32 i = 0; i < 10000; ++i)
{
lock_guard<SpinLock> guard(spinLock);
sum--;
}
}
int main()
{
thread t1(func1);
thread t2(func2);
t1.join();
t2.join();
std::cout << sum << std::endl;
return 0;
}
while (_locked.compare_exchange_strong(expected, desired) == false) {
//expected = false; 이렇게 설정해주면 locked 를 얻을 때까지 무한 대기 하게 되는데 cpu 를 사용하면서, expected = false; //compare_exchange_strong 내부에서 expected 값을 & 로 바꾸기 때문에 원래 초기 상태로 바꾼다
this_thread::sleep_for(100ms); 100 ms 동안 sleep 하도록 함
이렇게 하면 cpu 파워를 낭비 하지 않고 context switch 된 이후에 일정 시간이후에 다시 와서
locked 를 획을 할 수 있을지 확인하게 되어 무한 cpu 자원을 사용하는건 막을 수 있지만 , 다시 돌아왔을때 이미 다른 스레드에서 lock 을 얻어 갔다면 일정 시간이후에 다시 돌아온 스레드는 또다시 wait 해야 하는상황이 발생되게 되는 악순환이 될 수도 있다
this_thread::yield();
위으 것과 this_thread::sleep_for(0ms); 이것과 동일하다
이렇게 되면 엄밀히 말하면 spinlock 이 되는것은 아니다
여기에서 포인트는 커널모드로 들어가서 Context Switch 를 유발하고 유저모드에서 커널모드로 들어가게 할수 있다는 것임
Lock을얻을수없다면, 계속해서 Lock을확인하며얻을때까지기다린다. 이른바바쁘게기다리는 busy wating이다.
바쁘게기다린다는것은무한루프를돌면서최대한다른스레드에게 CPU를양보하지않는것이다.
Lock이곧사용가능해질경우컨택스트스위치를줄여 CPU의부담을덜어준다. 하지만, 만약어떤스레드가 Lock을오랫동안유지한다면오히려 CPU 시간을많이소모할가능성이있다.
하나의 CPU나하나의코어만있는경우에는유용하지않다. 그이유는만약다른스레드가 Lock을가지고있고그스레드가 Lock을풀어주려면싱글 CPU 시스템에서는어차피컨택스트스위치가일어나야 하기때문이다.주의할점스핀락을잘못사용하면 CPU 사용률 100%를만드는상황이발생하므로주의 해야 한다. 스핀락은기본적으로무한 for 루프를돌면서 lock을기다리므로하나의쓰레드가 lock을오랫동안가지고있다면, 다른 blocking된쓰레드는 busy waiting을하므로 CPU를쓸데없이낭비하게 된다.
장점은스핀락을잘사용하면 context switch를줄여효율을높일수있습니다.무한루프를돌기보다는일정시간 lock을얻을수없다면잠시 sleep하는 back off 알고리즘을사용하는것이훨씬좋습니다.
스핀 락(Spin lock)과 뮤텍스(Mutex)의 차이
둘 모두 자원에 대해 락을 걸고 사용하려고 할 시에 락이 풀릴 때까지 기다려야 한다는 점은 같지만, 둘은 내부적으로 로우레벨에서 차이점이 있다.
우선 뮤텍스의 경우, 자원에 이미 락이 걸려 있을 경우 락이 풀릴 때까지 기다리며 컨텍스트 스위칭을 실행한다.
즉, 다른 병렬적인 태스크를 처리하기 위해 CPU를 양보할 수 있다는 것이며 이는 자원을 얻기 위해 오랜 시간을 기다려야 할 것이 예상될 때 다른 작업을 동시에 진행할 수 있다는 것이다. 하지만 이는 자원이 단시간 내로 얻을 수 있게 될 경우 컨텍스트 스위칭에 더 큰 자원을 낭비하게 될 수 있다는 문제가 있다.
스핀 락의 경우에는 이름에서부터 알 수 있듯이, 자원에 락이 걸려 있을 경우 이를 얻을 때까지 무한 루프를 돌면서 다른 태스크에 CPU를 양보하지 않는 것이다. 자원이 단시간 내로 얻을 수 있게 된다면 컨텍스트 스위칭 비용이 들지 않으므로 효율을 높일 수 있지만, 그 반대의 경우 다른 태스크에 CPU를 양보하지 않으므로 오히려 CPU 효율을 떨어뜨릴 수 있는 문제가 있다.
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic>
#include <vector>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
using namespace std;
mutex m1;
int32 sum = 0;
void func1()
{
for (int32 i=0;i<10000;++i)
{
lock_guard<mutex> guard(m1);
sum++;
}
}
void func2()
{
for (int32 i = 0; i < 10000; ++i)
{
lock_guard<mutex> guard(m1);
sum--;
}
}
int main()
{
thread t1(func1);
thread t2(func2);
t1.join();
t2.join();
std::cout << sum << std::endl;
return 0;
}
위 코드 결과는 0 이며 mutex 를 활용한 것이다 정상적으로처리 된다
하지만 아래처럼 custom 한 lock 클래스를 구현하여 처리 할려고 보면 아래와 같이 정사적인 연산이 되지 않는다는 것을 알 수 있다
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic> //멀티 플랫폼에서 작동 가능
#include <vector>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
using namespace std;
mutex m1;
int32 sum = 0;
class SpinLock
{
public:
void lock()
{
while (_locked)
{
}
_locked = true;
}
void unlock()
{
_locked = false;
}
bool _locked = false;
};
SpinLock spinLock;
void func1()
{
for (int32 i=0;i<10000;++i)
{
lock_guard<SpinLock> guard(spinLock);
sum++;
}
}
void func2()
{
for (int32 i = 0; i < 10000; ++i)
{
lock_guard<SpinLock> guard(spinLock);
sum--;
}
}
int main()
{
thread t1(func1);
thread t2(func2);
t1.join();
t2.join();
std::cout << sum << std::endl;
return 0;
}
결과 -5512 등등 이상한 값이 나옴..
volatile 는 해당 코드를 최적화 하지 말라고 하는것 반복문 등에서.. 하지만 이게 지금의문제는 아니지만 참고사항으로
_locked = true; 이 코드는 한줄이 아님
_locked = true;
00007FF60EC7405F mov rax,qword ptr [this]
00007FF60EC74066 mov byte ptr [rax],1
bool 값도 원자적으로 일어나야지 문제가 발생하지 않음으로 atomic 으로 처리해야한다
또한 lock_guard 에서 lock 함수와 unlock 함수를 사용하는 이유에서라도 atomic 을 사용해야한다
문제는 아래 명령이 하나로 처리 되야 하는데 로직이 두개가 보니 즉 wait 하다가 값이 바뀌면 바로 빠져나가야 하는데 스레드가 전환 되면서 값이 제대로 바뀌지 않을 수 있기 때문에 문제가 발생하기 때문에
while (_locked) { } _locked = true;
이게 한번의 명령으로 처리 되지 않아 context switch 가 되면서 상태가 망가지는 것
while 쪽의 조건과 _locked 값을 한번에 처리 하는 방식으로 대기하도록 바꿔줘야 할 필요가 있다
즉 한방에 처리해야 한다는 것
이것을 한방에 수행하도록 묶어주는 방법이 있음
CAS (Compare-And-Swap) : OS 에 따라서 InterlockedExchagned(..) 같은 함수인데
atomic 을 사용하면 여기에 이것이 포함되어 있음
atomic.compare_exchange_strong함수임
compare_exchange_strong : 이 함수는 atomic 하게 일어나며 (원자적으로 한방에처리 all or nothing) 다음과 유사하다
요약 하자면 expected 와 _locked 값이 같으면 desired 으로 _locked 값을 바꾸고, 그렇지 않다면 _locked 값은 그대로 유지된다
compare_exchange_strong : 함수에 대한 설명 결국 값을 바꾸는 것이긴 한데 원하는 값으로 바꾸느냐임
if(_locked == expected ) //만약 _locked 가 기대되는 값이 false 와 같다면 { expected = _locked; //_lock 값을 기대되는 값에 넣어준다 _locked = desired; //그 다음 _lock 값을 원하는 값으로 넣어준다 return true; //즉 locked 가 기대하는 값과 같다면 _locked 를 원하는 값으로 변경한다 } else // _locked 가 기대하는 값과 다르다면 { expected = _locked; //기대 값을 _locked값으로 바꾼다 return false; }
void lock()
{
bool expected = false;
bool desired = true;
/*
* compare_exchange_strong : 이 함수는 atomic 하게 일어나며
(원자적으로 한방에처리 all or nothing) 다음과 유사하다
* 요약 하자면 expected 와 _locked 값이 같으면 desired 으로 _locked 값을 바꾸고,
그렇지 않다면 _locked 값은 그대로 유지된다
*
if(_locked == expected ) //만약 _locked 가 기대되는 값이 false 와 같다면
{
expected = _locked; //_lock 값을 기대되는 값에 넣어준다
_locked = desired; //그 다음 _lock 값을 원하는 값으로 넣어준다
return true; //즉 locked 가 기대하는 값과 같다면
//_locked 를 원하는 값으로 변경한다
}
else // _locked 가 기대하는 값과 다르다면
{
expected = _locked; //기대 값을 _locked값으로 바꾼다
return false;
}
*/
//_locked 값이 기대 하는 값과 같으면 계속 무한 루프를 돌면서 spinlock 으로 계속 대기
//하고, 그렇지 않고 expected 값이 locked 다르면 내부적으로 _locked 값을 desired 값으로
//바꾼다음 while 을 탈출해 spinlock 에서
//빠져나오게 한다
while (_locked.compare_exchange_strong(expected, desired) == false)
{
//compare_exchange_strong 내부에서 expected 값을 & 로 바꾸기 때문에
//원래 초기 상태로 바꾼다
expected = false;
}
}
void unlock()
{
_locked.store(false); //bool 을 바꾸는 것도 또한 원자적으로 일어나야함
}
Custom class 로 구혆나 Spinlock 클래스
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic> //멀티 플랫폼에서 작동 가능
#include <vector>
#include <mutex>
#include "AccountManager.h"
#include "UserManager.h"
using namespace std;
mutex m1;
int32 sum = 0;
class SpinLock
{
public:
void lock()
{
bool expected = false;
bool desired = true;
/*
* compare_exchange_strong : 이 함수는 atomic 하게 일어나며(원자적으로 한방에처리 all or nothing) 다음과 유사하다
* 요약 하자면 expected 와 _locked 값이 같으면 desired 으로 _locked 값을 바꾸고 , 그렇지 않다면 _locked 값은 그대로 유지된다
*
if(_locked == expected ) //만약 _locked 가 기대되는 값이 false 와 같다면
{
expected = _locked; //_lock 값을 기대되는 값에 넣어준다
_locked = desired; //그 다음 _lock 값을 원하는 값으로 넣어준다
return true; //즉 locked 가 기대하는 값과 같다면 _locked 를 원하는 값으로 변경한다
}
else // _locked 가 기대하는 값과 다르다면
{
expected = _locked; //기대 값을 _locked값으로 바꾼다
return false;
}
*/
//_locked 값이 기대 하는 값과 같으면 계속 무한 루프를 돌면서 spinlock 으로 계속 대기 하고, 그렇지 않고 expected 값이 locked 다르면
//내부적으로 _locked 값을 desired 값으로 바꾼다음 while 을 탈출해 spinlock 에서 빠져나오게 한다
while (_locked.compare_exchange_strong(expected, desired) == false)
{
expected = false; //compare_exchange_strong 내부에서 expected 값을 & 로 바꾸기 때문에 원래 초기 상태로 바꾼다
}
}
void unlock()
{
_locked.store(false); //bool 을 바꾸는 것도 또한 원자적으로 일어나야함
}
volatile atomic<bool> _locked = false; //bool 값도 그냥 바꾸면 명령어가 두개로 처리됨
};
SpinLock spinLock;
void func1()
{
for (int32 i=0;i<10000;++i)
{
lock_guard<SpinLock> guard(spinLock);
sum++;
}
}
void func2()
{
for (int32 i = 0; i < 10000; ++i)
{
lock_guard<SpinLock> guard(spinLock);
sum--;
}
}
int main()
{
thread t1(func1);
thread t2(func2);
t1.join();
t2.join();
std::cout << sum << std::endl;
return 0;
}
spinlock 을 cpu 를 계속 먹는 상태가 된다 context switch 가 되지 않음으로
ProcessSave 에서 lock_guard 를 getAccount 함수와 실행 순서를 바꿔주어 DeadLock 현상을 피하게 한다
요약 :
t1 스레드가 getaccount 작업을 마칠때까지 t2 스레드는 아무것도 하지 않고 대기만 하다가 t1 작업이 끝나면 t2 가 작업 되게 한다
t2 스레드가 getUser 함수 작업이 완료 될되고 processLogin 함수가 완료 될떄까지 t1 을대기시키고 완료 되면 t1 이 실행되게 허용한다
t2 스레드가 실행되고 processLogin 에서 AccountManager::_mutex 를 lock 하고 getuser 작업을 하려는 직전에 ( UserManager::_mutex lock 못함) t1 스레드가 먼저 실행되어 getAccount가 실행 되는 경우 AccountManager 의 _Mutex 는 이미 lock 되어 있어서 t1 은대기 하게 되고 다시 t2가 실행 되어 UserManager::_mutex 를 lock 한다음 getUser 처리하고 processLogin 함수가 완료가 된 이후에야 AccountManager::_mutex가 unlock 이 되기 때문에 이때서야 t1 스레드의 getAccount 가 호출이 되고 processSave 함수또한 마무리 된다
ProcessSave 함수에서 UserManager::_mutex 를 lock_guard 한것은 Dead lock 을 피하기 위해 순서를 바꾸다 보니 이처럼 된것, 즉 AccountManager::_mutex 를 t1, t2 스레드에서 먼저 바라보게 처리해야지 Dead lock 을 피할 수 있으니 로직이 이처럼 순서가 바뀐것일 뿐
하지만 이렇게 순서를 바꾸는것은 보통 로직상 이런 경우가 잘 나오진 않는다
방법 2.
Dead lock 이 발생했을 경우 mutex 를 감싸는 warp 클래스를 만들어서 현재 mutex lock 되는 count 가 같은지 다른지를 판별해서 언제 문제가 발생하는지 파악할 수도 있다
방법.3
lock 을 거는 것을 각 상태별 graph state를 만들어 순환 구조가 나오면 Dead lock임으로 이걸 구조화하여 코드로 만들어서 순환이 일어나면 Dead lock 이 일어난다는 것을 디버깅을 통해 알 수 있게 할 수도 있다
push_back 하면서 capacity가 증가함 하지만 vector 자체는 멀티스레드호환 가능으로 만들어지지 않았음
용량이더 큰 것이 추가 되면서 재할당이 될 수 있는데 다른 두개 중 추가하는 스레드 외에 스레드에서 이미 벡터의 메모리를 제거했을 수 있음 재할당으로 => crash
reserve 20000 을 해 줘도 size 변수를 갱신 할때 문제가 발생 할 수 있음 => 제대로 추가가 되지 않음
atomic<vector<int32>> 이것도 불가 atomic.load 등의 atomic 자체의 기능을 사용 하는것이기 vector 와 연결(연동)되지 않음
어쨌든 문제가 발생 할 수 있음
그럼 추가 할때 한번에 한 스레드만 허용가능하도록 lock 처리를 해줘야 함 lock 으로 잠그면 다른 스레드가 접근 불가 unlock 하기 전까지
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread>
#include <atomic> //멀티 플랫폼에서 작동 가능
#include <vector>
#include <mutex>
using namespace std;
vector<int32> v;
mutex m; //화장실의 자물쇠 같은것
void push()
{
for (int32 i = 0; i < 10000; ++i)
{
m.lock(); //자물쇠로 잠그고 하나의 스레드만 진입 가능
v.push_back(i);
m.unlock(); //자물쇠 품
}
}
int main()
{
thread t1(push);
thread t2(push);
t1.join();
t2.join();
cout << v.size() << endl;
return 0;
}
하지만 lock 을 쓸때 병합이 너무 심해지면 일반 적인 상황보다는 느려지게 된다
재귀적으로 lock 을 걸면?
불가능 함, 하지만 recursive mutex 로 가능해짐
=> 코드가 복잡해지면 이함수 안에서 다른 함수를 호출 할때 재귀적으로 락을 걸고 싶을 때가 있을 수 있음
문제가 발생 할수 있는 또 다 른 상황
for 문에서
if(i==10)
{
break;
}
로 빠져나올때 unlock() 을 안하면 무한대기 상태가 됨 (Dead lock) 상황이 됨
수동으로 lock, unlock 하는건 실수가 발생 할수 이씩 때문에
RAII (Resource Acqusition Is Initialization)
warp 클래스를 만들어 생성자에서 mutex를 받아 잠그고 소멸자에서 풀어주는 방식으로 사용함
표준적으로 std::lock_guard<> 가 제공 됨
unique_lock 이 존재하는데 lock 하는 시점이 lock_guard 처럼 생성함고 동시에 lock 이 아닌
지연 시켜 lock 을 할 수 있다
The classunique_lockis a general-purpose mutex ownership wrapper allowing deferred locking, time-constrained attempts at locking, recursive locking, transfer of lock ownership, and use with condition variables. The classunique_lockis movable, but not copyable -- it meets the requirements ofMoveConstructibleandMoveAssignablebut not ofCopyConstructibleorCopyAssignable.
The classunique_lockmeets theBasicLockablerequirements. IfMutexmeets theLockablerequirements,unique_lockalso meets theLockablerequirements (ex.: can be used instd::lock); ifMutexmeets theTimedLockablerequirements,unique_lockalso meets theTimedLockablerequirements.
"unique_lock과 lock_guard의 차이점은 lock을 걸 수 있는 시점이다. 둘 다 소멸 시점에 lock이 걸려 있다면 unlock을 수행한다. lock_guarud는 lock과 unlock 사이에서 lock과 unlock을 할 수 없지만 unique_lock은 소멸하기 전에 unlock과 lock을 걸 수 있다.
unique_lock은 lock_guard에 기능이 추가된 버전이라고 생각하면 된다."
void push()
{
for (int32 i = 0; i < 10000; ++i)
{
unique_lock<mutex> uniquLock(m, defer_lock); //이때 잠기지 않고
uniquLock.lock(); //이때 mutex 를 잠군다
v.push_back(i);
}
}
#include "pch.h"
#include <iostream>
#include "CorePch.h"
#include <thread> //11부터 thread 가 다른 플랫폼에서도 구현 가능되도롯 멀티플랫폼으로 지원 됨 => linux 에서도 실행 가능
#include <vector>
using namespace std;
void HelloThread(int a)
{
std::cout << "Hello Thread " << a << std::endl;
}
int main()
{
vector<std::thread> t;
t.resize(1);
auto idtest = t[0].get_id(); //관리하고 있는 스레드가 없다면 id 는 0
t[0] = std::thread(HelloThread, 10);
if (t[0].joinable())
{
t[0].join();
}
std::cout <<" main " << std::endl;
return 0;
}
int main() { //cout 은 os 커널에 요청하여 요청된 처리가 다시 콘솔화면으로 오는 느린 실행이다 //HelloWorld();
//std::thread t(HelloThread); std::thread t;
auto idtest = t.get_id(); //관리하고 있는 스레드가 없다면 id 는 0
t = std::thread(HelloThread);
int32 count = t.hardware_concurrency(); //CPU 코어 개수는 몇개인지 힌트를 줌 => 논리적으로 실행할 수 있는 프로세스 개수 , 100% 확실한 동작이 되진 않을 수있어서 경우에따라 0 을리턴하면 제대로 조사가 안된 것
auto id = t.get_id(); // 각 쓰레드마다 부여되는 id , 쓰ㅜ레드 사이에서는 id 가 겹치지 않는다 t.detach(); //join 반대로 std::thread 객체에서 실제 스레드를 분리 => 스레드 객체 t 와 연결을 끊어줌 => 만들어진 스레듸이 정보를 더이상 사용 할수 없음
//쓰레드를 떼어내면, 쓰레드가 독립적으로 실행됩니다. 프로그램이 종료되면 떼어진 쓰레드는 동작이 멈추게 됩니다.
bool states = t.joinable(); //detach 되거나 연동된 슬레드가 없는 상태를 판별하기 위한 함수
//t.join(); //스레드가 끝날때까지 대기
if (t.joinable()) { t.join(); }
std::cout << "Hello Main" << std::endl;
return 0; }
위 코드에선 detach 하여 Join 을 하지 못하기 때문에 Hello Main 이 높은 확률로 나오는 것을 알 수 있다
하나의 프로세서(실행 중인 프로그램)에서 각 독립적인 일의 단위인 스레드(Thread)로 여러 작업을 처리할 수 있다. 즉 하나의 프로세서에서 병렬적으로 여러 개 작업을 처리하기 위해서는 각 작업을 스레드화하여 멀티스레딩이 가능하게 해야 한다.
Process란
간단하게 말하면 실행중인 프로그램.
프로세스는 사용 중인 파일, 데이터, 프로세서의 상태, 메모리 영역 주소 공간, 스레드 정보, 전역 데이터가 저장된 메모리 부분 등 수 많은 자원을 포함하는 개념. 종종 스케쥴링의 대상이 되는 작업이라고 불리기도 함
쓰레드와 프로세스의 차이점
프로세스는 완벽히 독립적이기 때문에 메모리 영역(Code, Data, Heap, Stack)을 다른 프로세스와 공유를 하지 않지만, 쓰레드는 해당 쓰레드를 위한 스택을 생성할 뿐 그 이외의 Code, Data, Heap영역을 공유한다.
텍스트 : PC(피시 카운터 - 다음번에 실행 될 명령어의 주소를 가지고 있는 레지스터), 프로그램 코드 저장
데이터: 글로벌 변수, 스태틱 변수 저장
힙 :메모리관리, 동적 메모리 할당(시스템 콜로 관리)
스택: 임시 데이터 저장- 로컬 변수, 리턴 어드레스
스택을 독립적으로 할당하는 이유
스택은 함수 호출 시 전달되는 인자, 되돌아갈 주소값 및 함수 내에서 선언하는 변수 등을 저장하기 위해 사용되는 메모리 공간이다. 따라서 스택 메모리 공간이 독립적이라는 것은 독립적인 함수 호출이 가능하다는 것이고, 이는 독립적인 실행 흐름이 추가되는 것이다. 결과적으로 실행 흐름의 추가를 위한 최소 조건이 독립된 스택을 제공하는 것이다.
코드 영역을 공유
프로세스는 독립적인 구조이기 때문에 다른 프로세스의 Code영역에 있는 함수를 호출할 수 없다.
쓰레드는 Code영역을 공유하기 때문에 두 개 이상의 쓰레드가 자신이 포함된 프로세스의 Code영역에 있는 함수를 호출할 수 있다.
데이터 영역과 힙 영역을 공유
전역 변수와 동적 할당된 메모리 공간을 공유할 수 있고, 이를 통해 쓰레드 간 통신을 할 수 있지만 동시에 메모리에 접근하기 때문에 주의해야 한다.
멀티 프로세스의 문제점
두 개의 프로세스는 완전히 독립된 두 개의 프로그램 실행을 위해서 사용되기 때문에 컨텍스트 스위칭(프로세스의 상태 정보를 저장하고 복원하는 일련의 과정)으로 인한 성능 저하가 발생
쓰레드는 하나의 프로그램 내에서 여러 개의 실행 흐름을 두기 위한 모델이다.
쓰레드는 프로세스처럼 완벽히 독립적인 구조가 아니다. 쓰레드들 사이에는 공유하는 요소가 있다.
쓰레드는 이 공유하는 요소로 인해 컨텍스트 스위칭에 걸리는 시간이 프로세스보다 짧다.
쓰레드가 프로세스보다 컨텍스트 스위칭이 빠른 이유
쓰레드가 프로세스보다 컨텍스트 스위칭이 빠른 이유는 메모리 영역을 공유하기 때문이다. 실제로 공유되는 데이터가 있고 아닌 데이터가 있다.
쓰레드별로 main함수를 독립적으로 가지고 있고, 함수 호출도 독립적으로 진행되기 때문에 쓰레드별로 현재 pc값은 달라야 한다. 따라서 pc는 공유되지 않는다.
쓰레드는 독립적인 스택을 가지기 때문에 스택의 정보를 담고 있는 sp와 fp는 공유되지 않는다.
범용적으로 사용가능한 레지스터
시스템을 어떻게 디자인 하느냐에 따라 달라지는 것이기 때문에 일반적으로 공유된다고 할 수 없다.
캐시메모리
캐시 메모리는 CPU에서 한번 이상 읽어 들인 메인 메모리의 데이터를 저장하고 있다가 CPU가 다시 그 메모리에 저장된 데이터를 요구할 때 메인 메모리를 통하지 않고 바로 값을 전달하는 용도로 사용된다.
프로세스 사이에서 공유하는 메모리가 하나도 없기 때문에 컨텍스트 스위칭이 발생하면 캐쉬에 있는 모든 데이터를 모두 리셋하고 다시 캐쉬 정보를 불러와야 한다.
쓰레드는 캐쉬 정보를 비울 필요가 없기 때문에 프로세스와 쓰레드의 컨텍스트 스위칭 속도의 차이는 이때 발생한다.
Windows에서의 프로세스와 쓰레드
Windows 입장에서 프로세스는 쓰레드를 담는 상자에 지나지 않는다.
또한 Windows에서 프로세스는 상태(Running, Ready, Blocked)을 지니지 않는다. 상태를 지니는 것은 스레드이다.
스케줄러가 실행의 단위로 선택하는 것도 프로세스가 아닌 스레드이다.
프로세스 컨텍스트 스위칭 역시 실제로 오버헤드가 발생하는 부분은 서로 다른 프로세스에 포함된 스레드 간의 컨텍스트 스위칭시 발생한다.
[OS]메모리 관점에서 본 쓰레드(thread)
메모리 관점에서 본 process의 특징 각각의 프로세스는 메모리 공간에서 독립적으로 존재한다.
<출처:https://elgaabeb.wordpress.com/>
전에 본 적이 있는 그림이다. 이 그림은 프로세스를 구성하는 메모리 공간의 모습이다. 각각의 프로세스는 자신만의 이런 메모리 구조를 가진다. 프로세스A, B, C가 존재한다면 각각 프로세스는 모두 위와 같은 구조의 메모리 공간을 가진다.
독립적인만큼 다른 프로세스의 메모리 공간에 접근할 수도 없다. A가 B의 메모리 공간에 접근하면 재앙이 발생할 수도 있다. 만약 A가 뜬끔없이 Chrome의 메모리 공간에 접근한다고 생각해보라. Chrome의 안정성이 보장될 수 있겠는가? 더 뜬금없이 A가 windows의 메모리 공간에 접근한다고 생각해보라. 운영체제의 메모리 공간에 접근하여 뭔가를 변경한다면 심각한 문제가 발생할 수 있다.(물론 운영체제의 메모리 공간에 접근하는 것은 원천적으로 불가능하다) 그러므로 프로세스의 안정성을 보장하기 위해서는 프로세스는 각각 독립된 메모리 공간을 가져야 한다.
wikipedia를 보면 쓰레드를 설명하기 위해 위와 같은 그림들을 보여준다. 아래 그림을 보면 프로세스 내부에 2개의 쓰레드가 존재한다. 그리고 시간의 방향을 따라 쓰레드가 실행되고 있다. 그림에서 볼 수 있듯이 쓰레드는 프로세스와 별개가 아닌 프로세스를 구성하고 실행하는 흐름이다.
프로세스에서도 그러했듯이 이번에도 메모리 관점에서 쓰레드를 보자. 프로세스와 어떤 차이가 있는지 뚜렷하게 알 수 있을 것이다.
위 그림은 프로세스와 쓰레드의 메모리 구조의 차이점을 보여준다. 왼쪽의 프로세스는 이미 봤기 때문에 설명하지 않고, 오른쪽의 thread에 주목하자. 앞서 말한 것처럼 쓰레드는 프로세스 안에 존재하는 실행흐름이다. 메모리 구조 역시 그러하다. 하지만 특이한 점은 쓰레드는 프로세스의 heap, static, code 영역 등을 공유한다는 사실이다. 각각의 프로세스가 독립적인 stack, heap, code, data 영역을 가진 반면에, 한 프로세스에 속한 쓰레드는 stack 영역을 제외한 메모리 영역은 공유한다.
//첨언 : 쓰레드는 stack 뿐만 아니라 레지스터또한 독립적인 공간이다
//굳이 중요도를 따지자면 레지스터의 독립적인 공간에 좀 더 관심을 둘 필요가 있다
쓰레드가 code 영역을 하기 때문에 한 프로세스 내부의 쓰레드들은 프로세스 가 가지고 있는 함수를 자연스럽게 모두 호출할 수 있다.
뿐만 아니라 쓰레드는 data, heap 영역을 공유하기 때문에 IPC 없이도 쓰레드 간의 통신이 가능하다. 동일한 프로세스 내부에 존재하는 쓰레드 A, B가 통신하기 위해 heap 영역에 메모리 공간을 할당하고, 두 쓰레드가 자유롭게 접근한다고 생각하면 된다.
쓰레드는 프로세스처럼 스케줄링의 대상이다. 이 과정에서 컨텍스트 스위칭이 발생한다. 하지만 쓰레드는 공유하고 있는 메모리 영역 덕분에 컨텍스트 스위칭 때문에 발생하는 오버헤드(overhead)가 프로세스에 비해 작다.
오랜만에 S/W개발 관련된 글을 올립니다. 요즘 블로그에 제대로 글을 쓰지도 못하는데 계속해서 RSS 구독자 카운트는 늘어만가니 어찌된 조화인지 모르겠습니다. 늘어나는 구독자수의 압박을 견디다 못해 오래전에 약속드렸던 reentrant와 thread-safe의 차이점에 대해 말씀드릴까 합니다.
우선 reentrance 를 우리말로 옮기자면 재진입성쯤 되고, thread-safety는 multithread-safety라고도 하니 다중쓰레드안전성쯤 되겠습니다. 요즘 워낙 multi-threaded programming은 일반화된 것이라 thread-safety에 대해서는 어느 정도 개념들을 챙기고 계시리라 생각하고, reentrance가 thread-safety와 어떻게 다른가를 설명하면서 그 둘간의 차이점을 설명해 보도록 하겠습니다.
어떤 루틴 또는 프로그램이 Thread-safe하다라고 하면 여러 쓰레드에 의해 코드가 실행되더라도 실행 결과의 correctness가 보장되는 것을 뜻합니다. 이 정의에서 중요한 점은 실행 결과의 correctness가 보장되어야 한다는 것입니다. 즉, 여러 쓰레드에 의해 코드가 진짜로 동시에 수행되던 보이기에 동시에 수행되던 간에 실행 결과의 correctness가 보장되면 Thread-safe하다라고 말하는 거죠.
이에 비해 어떤 루틴 또는 프로그램이 Reentrant하다라고 하면 여러 쓰레드에 의해 코드가 동시에 수행될 수 있고, 그런 경우에도 실행 결과의 correctness가 보장되는 것을 뜻합니다.
이해가 되시나요 ? 차이점이 안 보이신다구요 ? 그럼 다시 한 번 말씀드리죠.
어떤 루틴 또는 프로그램이 Thread-safe하다라고 하면 여러 쓰레드에 의해 코드가 실행되더라도 실행 결과의 correctness가 보장되는 것을 뜻합니다.
이에 비해 어떤 루틴 또는 프로그램이 Reentrant하다라고 하면 여러 쓰레드가 코드를 동시에 수행할 수 있고, 그런 경우에도 실행 결과의 correctness가 보장되는 것을 뜻합니다.
이제 보이시죠 ? Reentrant 특성이 훨씬 강력한 제약조건이라는 것이 느껴지시나요 ? 구체적으로 코드에서는 어떻게 달라지나 예제를 통해서 알아보겠습니다.
C 언어 표준라이브러리에 strtok()이라는 문자열 함수가 있는 건 다 알고 계시겠죠(모르시는 분은 가서 엄마 젖 좀 더 먹고 오세요~ ㅋㅋㅋ 농담입니다). strtok() 의 매뉴얼에 다음과 같이 설명되어 있습니다.
The strtok() function can be used to break the string pointed to by s1 into a sequence of tokens, each of which is delimited by one or more characters from the string pointed to by s2. The strtok() function considers the string s1 to consist of a sequence of zero or more text tokens separated by spans of one or more characters from the separator string s2. The first call (with pointer s1 specified) returns a pointer to the first character of the first token, and will have written a null character into s1 immediately following the returned token. The function keeps track of its position in the string between separate calls, so that subsequent calls (which must be made with the first argument being a null pointer) will work through the string s1 immediately following that token. In this way subsequent calls will work through the string s1 until no tokens remain. The separator string s2 may be different from call to call. When no token remains in s1, a null pointer is returned.
strtok()을 사용하는 예제를 보면 그 의미가 더 명확해집니다.
#include <cstring>
using namespace std;
int main() { // strtok() 의 첫번째 argument 는 const char * 가 아닌 char * 이므로 // 새로 할당된 메모리로 넣음 char* str = (char*)malloc(strlen("A;B;C;D;E;F;G")+1); strcpy(str, "A;B;C;D;E;F;G"); cout << str << " ==> ";
char* tok = strtok(str, ";"); while (tok != 0) { cout << tok << " "; tok = strtok(0, ";"); } cout << endl;
return 0; }
위와 같이 작동한다는 것은 strtok() 내부적으로 다음과 같이 다음번 호출 때 문자열 분석을 시작할 위치를 기억하고 있다는 걸 뜻합니다. 그리고 여러번의 호출에 걸쳐 이 함수가 제대로 작동하기 위해서는 그 위치는 당연히 static 으로 선언되어 있겠지요.
char* strtok(char* src, const char* delim) { // src, delim 이 NULL 인지, delim 이 "" 인지 체크하는 코드는 생략 char* tok; static char* next; // 분석을 시작할 위치 if (src != NULL) next = src; tok = next;
// boundary condition check if (*next == '\0') return NULL;
// 분석 시작 for (; *next != '\0'; ++next) { if (*next in delim) // pseudo code { *next = '\0'; ++next; break; } }
return tok; }
위와 같은 코드는 Reentrant 하지도 않고 Thread-Safe 하지도 않을 것입니다. 위 코드가 여러 쓰레드에 의해 수행될 경우, next 라는 변수가 서로 다른 쓰레드에 위해 공유가 되므로(함수 내에서 static으로 선언된 변수는 stack에 할당되는 것이 아니라 전역 메모리 영역에 할당됩니다) next 변수가 깨질 가능성이 생기기 때문입니다. 이런 상황에 대한 구체적인 예를 다음과 같이 들 수 있을 것 같습니다.
Multi-thread 상의 strtok() 호출
위 그림에서 Call strtok() 앞의 숫자는 호출 순서를 뜻하는 것이고 next가 가리키는 화살표의 선은 Call strtok()을 호출한 후 next 변수의 상태값이라고 생각하시면 됩니다. 그림의 예에서는 3, 4 번까지는 원래 예상하는 결과 대로 리턴이 되겠지만 5번 호출에서는 "F"가 리턴될 것이고, 6번 호출에서는 NULL이 리턴될 것입니다(왜 그런지는 제가 작성한 strtok()을 따라가면서 알아보세요. ^^). 이런 결과가 나오는 것은 모두 next 라는 변수가 양쪽 Thread에 의해서 값이 갱신되기 때문입니다.
그렇다면 strtok()을 thread-safe 하게 만들기 위해서는 어떻게 해야할까요 ? 다음 처럼 strtok() 내부 구현을 바꿔서 내부적으로 next 변수에 대해 lock을 걸도록 만들면 될까요 ?
os_specific_lock lck;
char* strtok(char* src, const char* delim) { // src, delim 이 NULL 인지, delim 이 "" 인지 체크하는 코드는 생략 char* tok; lock(&lck); static char* next; // 분석을 시작할 위치 if (src != NULL) next = src; tok = next;
언뜻 생각하면 위와 같이 구현된 strtok()이 thread-safe하다고 생각할 수도 있겠지만 실상은 전혀 그렇지 않습니다. 위와 같이 구현된 strtok()은 thread 가 동시에 next 변수를 수정하는 것을 막아주기 하지만 그림에서 나타낸 예를 제대로 처리해주지 못합니다. strtok()이 thread-safe 하기 위해서는 strtok() 호출 한번에 대해 thread-safe하면 되는 것이 아니라 전체 tokenizing 과정이 모두 thread-safe 해야 하기 때문입니다. 아~ 그렇군요. 그렇다면 tokenizing 과정 전체에 대해 lock을 걸면 되겠네요.
어때요? 맘에 드시나요 ? tokenizing 과정 전체에 대해 lock을 걸어 버렸으니 제가 그림에서 제시한 상황이 발생하지 않겠네요. 그래도 어쩐지 꺼림직하지 않으세요 ? 마치 구더기 한 마리 잡으려고 불도저 쓰는 격이라고나 할까요. 위에 있는 tokenizer는 아주 간단해서 그렇지 만약에 token 하나 하나에 대해서 복잡한 처리를 한다면 어떻게 될까요 ? 그리고 복잡한 처리 과정 중에 그 쓰레드가 I/O 이벤트를 기다린다면 어떻게 될까요 ? 갈수록 태산이네요. 그죠 ? CPU가 아무리 빨라도 아무리 많은 Multi Core 들을 가지고 있어도 전혀 그런 성능을 활용하지 못하는 코드가 되어 버립니다. 이 사태를 어떻게 해결해야 하나요. 여러분이 진정한 엔지니어라면 여기서 멈춰서는 안돼죠. 해결책을 생각할 시간을 드리겠습니다. 1초. 2초. 3초. 4초. 5초. 6초. 7초. 8초. 9초. 10초 삐~~~~~!!!.
생각나셨나요 ? 멋진 해결책을 가지고 계신 분들이 있으리라 생각합니다. 자~ 그럼 다음과 같이 strtok() 인터페이스 및 구현을 바꾸면 어떨까요 ?
char* strtok(char* src, const char* delim, char** start) { // src, delim 이 NULL 인지, delim 이 "" 인지 체크하는 코드는 생략 char* tok; char* next; // 분석을 시작할 위치. static 을 없애고 start 라는 입력 // 으로 초기화함 if (src != NULL) next = src; else next = *start;
// boundary condition check if (*next == '\0') return NULL;
// 분석 시작 tok = next; for (; *next != '\0'; ++next) { if (*next in delim) // pseudo code { *next = '\0'; ++next; break; } }
*start = next; return tok; }
이렇게 구현할 경우 thread-safe 하기도 하지만 reentrant하기도 합니다. 위와 같은 strtok() 내에서 사용되는 모든 변수는 stack에 할당되는 자동변수이므로 각각 독립적인 stack을 갖는 thread가 동시에 위와 같은 strtok()을 수행한다해도 전혀 문제가 없습니다. 실상 위와 같이 구현한 strtok()은 POSIX에 의해 표준화되어 있는 strtok_r()이나 MS Visual C++ 에서 제안한 safe string library에 표함되어 있는strtok_s()와 동일합니다.
reentrant 한 코드는 thread 간에 공유하는 자원 자체가 없어야만 하는 코드입니다.쓰레드간에 동기화 메커니즘 자체가 필요 없게 만드는 코드이고, 따라서 multi threading 환경에서 여러 쓰레드가 해당 코드를 진짜로 동시에 실행하더라도-동시에 실행되는 것처럼 보이기만 하는 것이 아니라-아무런 문제가 없습니다. 그렇지만 thread-safe 하다는 것은 단지 여러 쓰레드에 의해 실행되더라도 문제만 없으면 된다는 완화된 조건이므로 공유하는 자원이 있더라도 이것을 여러 쓰레드가 동시에 접근하지 못하도록 locking mechanism 같은 것으로 막아주기만 하면 됩니다. 결국 thread-safe한 코드는 multi threading 환경에서 reentrant 코드보다는 효율성이 떨어질 가능성이 높습니다. 해당 코드를 수행하고 있는 thread 가 공유 자원에 대한 lock 이 풀리기를 기다리는 동안은 다른 thread 의 수행을 막아버리기 때문입니다.
또 다른 간단한 예를 통해 thread-safe와 reentrant 의 차이점을 살펴 보겠습니다.
이제 thread-safe하게 됐습니다. reentrant 할까요 ? 아니올시다입니다. 여러 쓰레드가 f() 함수를 동시에 수행할 수 없기 때문입니다. 다시 말하면 한 쓰레드가 lock 을 걸고 있다면 다른 쓰레드는 lock 이 풀릴 때까지 기다려야 하므로 reentrant 하지 않은 것입니다. 위 코드를 reentrant하게 고치려면 어떻게 하면 될까요 ?
// 출처: Wikipedia int f(int i) { int priv = i; priv = priv + 2; return priv; }
int g(int i) { int priv = i; return f(priv) + 2; }
아예 전역 변수를 없애 버려서 쓰레드간 동기화가 필요 없게 만들어 버렸습니다. 위 코드에서는 워낙 lock이 걸리는 시간이 적을 것이므로 성능에 거의 영향을 미치지 않겠지만, lock이 걸리는 기간이 길어진다면 성능에 상당한 영향을 미치겠지요. 특히 요즘 유행하는 Multi-Core CPU에서는 그냥 thread-safe 코드와 reentrant 코드간의 성능 차이가 더 많이 발생할 것입니다.
보통은 thread-safe 코드를 만드는 것보다는 reentrant한 코드를 만드는 게 더 어렵습니다. 그리고, thread-safe 한 코드는 내부 구현만 바꾸면 되는 경우가 많지만 reentrant한 코드를 만드는 것은 위에서 제가 제시한 두 가지 예(strtok(), f())처럼 아예 인터페이스 자체를 재설계해야 하는 경우가 많습니다.
가능하다면 그냥 thread-safe한 코드를 만드는 것보다는 reentrant한 코드를 만드는 것이 성능상 훨씬 좋은 선택입니다. 물론 reentrant 한 코드를 만드는 것이 불가능한 경우도 있겠지만, 고민해보면 reentrant한 코드를 만들 수 있는 경우가 상당히 있습니다. 요즘처럼 Multi-Core CPU가 갈수록 일반화되고 있는 상황에서 Reentrance는 다시 한 번 주목을 받아야 할 것입니다.
그럼 Coding Guideline스러운 멘트로 이번 글을 마무리 하도록 하겠습니다. ^^