
Guarantees of the C++ runtime
I already presented the details to the thread-safe initialization of variables in the post Thread-safe initialization of data.
Meyers Singleton
The beauty of the Meyers Singleton in C++11 is that it's automatically thread-safe. That is guaranteed by the standard: Static variables with block scope. The Meyers Singleton is a static variable with block scope, so we are done. It's still left to rewrite the program for four threads.
// singletonMeyers.cpp
#include <chrono>
#include <iostream>
#include <future>
constexpr auto tenMill= 10000000;
class MySingleton{
public:
static MySingleton& getInstance(){
static MySingleton instance;
// volatile int dummy{};
return instance;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
};
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
I use the singleton object in the function getTime (line 24 - 32). The function is executed by the four promise in line 36 - 39. The results of the associate futures are summed up in line 41. That's all. Only the execution time is missing.
Without optimization
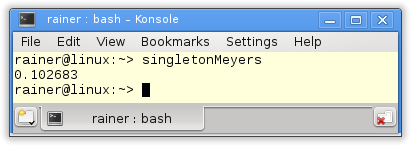

Maximum optimization
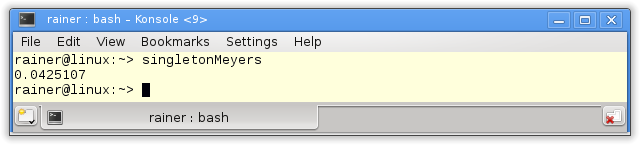
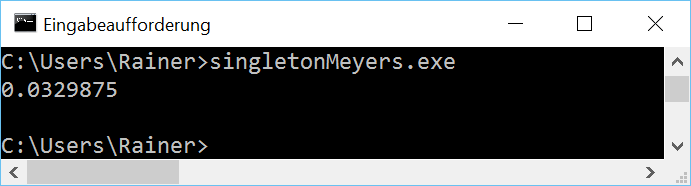
빠르다 Thread safe
The next step is the function std::call_once in combination with the flag std::once_flag.
The function std::call_once and the flag std::once_flag
You can use the function std::call_once to register a callable which will be executed exactly once. The flag std::call_once in the following implementation guarantees that the singleton will be thread-safe initialized.
// singletonCallOnce.cpp
#include <chrono>
#include <iostream>
#include <future>
#include <mutex>
#include <thread>
constexpr auto tenMill= 10000000;
class MySingleton{
public:
static MySingleton& getInstance(){
std::call_once(initInstanceFlag, &MySingleton::initSingleton);
// volatile int dummy{};
return *instance;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
static MySingleton* instance;
static std::once_flag initInstanceFlag;
static void initSingleton(){
instance= new MySingleton;
}
};
MySingleton* MySingleton::instance= nullptr;
std::once_flag MySingleton::initInstanceFlag;
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
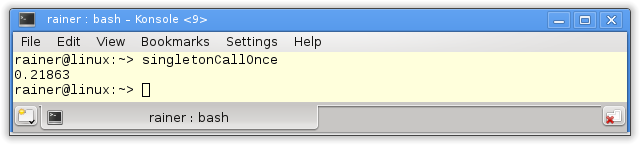
Here are the numbers.
Without optimization
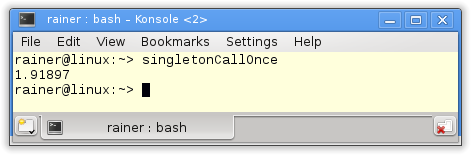
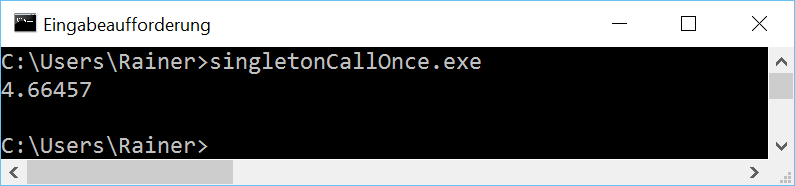
Maximum optimization

Of course, the most obvious way is it protects the singleton with a lock.
Lock
The mutex wrapped in a lock guarantees that the singleton will be thread-safe initialized.
// singletonLock.cpp
#include <chrono>
#include <iostream>
#include <future>
#include <mutex>
constexpr auto tenMill= 10000000;
std::mutex myMutex;
class MySingleton{
public:
static MySingleton& getInstance(){
std::lock_guard<std::mutex> myLock(myMutex);
if ( !instance ){
instance= new MySingleton();
}
// volatile int dummy{};
return *instance;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
static MySingleton* instance;
};
MySingleton* MySingleton::instance= nullptr;
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
How fast is the classical thread-safe implementation of the singleton pattern?
Without optimization
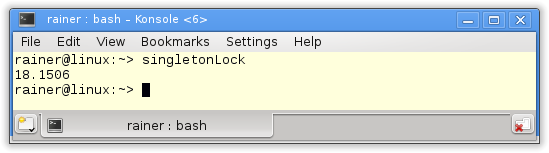
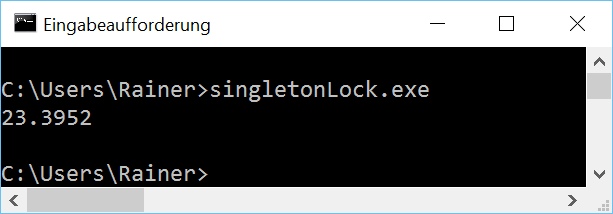
Maximum optimization
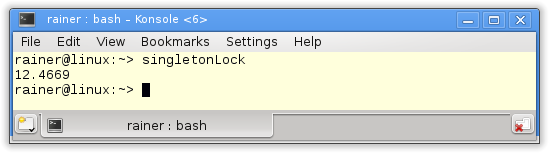

뮤텍스만 적용하면 이때는 Meyers Singleton 에 비해 많이 느리 다는 것을 알 수 있다
아마 그냥 mutex 만 걸면 동기화는 되지만 다른 연산들이 한번에 처리 되는
대체적으로 빠른 원자적 연산이 없기 때문에 몇번 더 연산을 해야 함 => 최적화가 덜 됨
Not so fast. Atomics should make the difference.
하지만 Atomic 을 적용하면 Meyers Singleton 만큼 빨라진다
Atomic variables
With atomic variables, my job becomes extremely challenging. Now I have to use the C++ memory model. I base my implementation on the well-known double-checked locking pattern.
double-checked locking pattern. : (간략하게 말하면 if 문 으로 두번 instnace 를 두번 체크 하는 것)
참고 : 더블체크드 락 패턴 (https://3dmpengines.tistory.com/2201)
Singleton multithreading programs (1)
Static variables with block scope Static variables with block scope will be created exactly once. This characteristic is the base of the so called Meyers Singleton, named after Scott Meyers. Thi..
3dmpengines.tistory.com
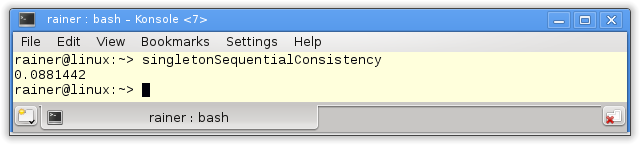
Sequential consistency
The handle to the singleton is atomic. Because I didn't specify the C++ memory model the default applies: Sequential consistency.
// singletonAcquireRelease.cpp
#include <atomic>
#include <iostream>
#include <future>
#include <mutex>
#include <thread>
constexpr auto tenMill= 10000000;
class MySingleton{
public:
static MySingleton* getInstance(){
MySingleton* sin= instance.load();
if ( !sin ){
std::lock_guard<std::mutex> myLock(myMutex);
sin= instance.load();
if( !sin ){
sin= new MySingleton();
instance.store(sin);
}
}
// volatile int dummy{};
return sin;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
static std::atomic<MySingleton*> instance;
static std::mutex myMutex;
};
std::atomic<MySingleton*> MySingleton::instance;
std::mutex MySingleton::myMutex;
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
Now I'm curious.
Without optimization
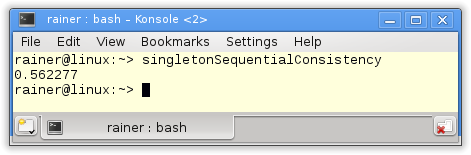

Maximum optimization
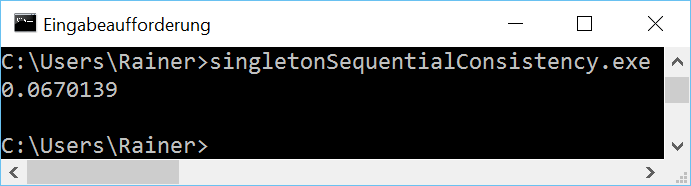
But we can do better. There is an additional optimization possibility.
atomic 만 추가 했는데 Meyers Singleton 만큼 빨라진 것을 볼 수 있다
여기서 약간 더 최적화 할 수 있는데 Acquire-release 체계를 사용 하는것 Memory Model
Acquire-release Semantic
The reading of the singleton (line 14) is an acquire operation, the writing a release operation (line 20). Because both operations take place on the same atomic I don't need sequential consistency. The C++ standard guarantees that an acquire operation synchronizes with a release operation on the same atomic. These conditions hold in this case therefore I can weaken the C++ memory model in line 14 and 20. Acquire-release semantic is sufficient.
// singletonAcquireRelease.cpp
#include <atomic>
#include <iostream>
#include <future>
#include <mutex>
#include <thread>
constexpr auto tenMill= 10000000;
class MySingleton{
public:
static MySingleton* getInstance(){
MySingleton* sin= instance.load(std::memory_order_acquire);
if ( !sin ){
std::lock_guard<std::mutex> myLock(myMutex);
sin= instance.load(std::memory_order_relaxed);
if( !sin ){
sin= new MySingleton();
instance.store(sin,std::memory_order_release);
}
}
// volatile int dummy{};
return sin;
}
private:
MySingleton()= default;
~MySingleton()= default;
MySingleton(const MySingleton&)= delete;
MySingleton& operator=(const MySingleton&)= delete;
static std::atomic<MySingleton*> instance;
static std::mutex myMutex;
};
std::atomic<MySingleton*> MySingleton::instance;
std::mutex MySingleton::myMutex;
std::chrono::duration<double> getTime(){
auto begin= std::chrono::system_clock::now();
for ( size_t i= 0; i <= tenMill; ++i){
MySingleton::getInstance();
}
return std::chrono::system_clock::now() - begin;
};
int main(){
auto fut1= std::async(std::launch::async,getTime);
auto fut2= std::async(std::launch::async,getTime);
auto fut3= std::async(std::launch::async,getTime);
auto fut4= std::async(std::launch::async,getTime);
auto total= fut1.get() + fut2.get() + fut3.get() + fut4.get();
std::cout << total.count() << std::endl;
}
The acquire-release semantic has a similar performance as the sequential consistency. That's not surprising, because on x86 both memory models are very similar. We would get totally different numbers on an ARMv7 or PowerPC architecture. You can read the details on Jeff Preshings blog Preshing on Programming.
Without optimization
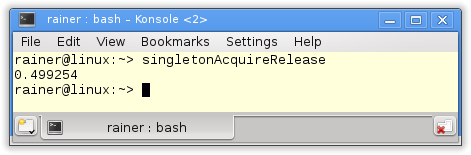
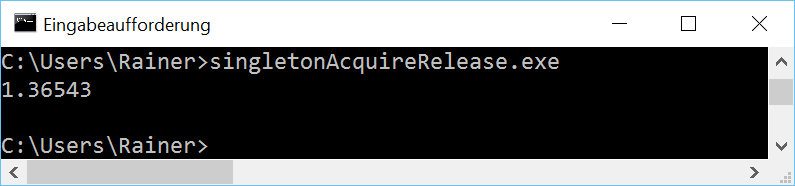
Maximum optimization

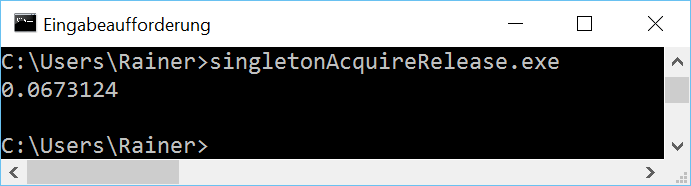
.
If I forget an import variant of the thread-safe singleton pattern, please let me know and send me the code. I will measure it and add the numbers to the comparison.
미소하지만 약간더 빨라 진 것을 볼 수 있다
Momory Model 중
acquire-release 방식의 의미는 순차적 일관성(https://3dmpengines.tistory.com/2205)과 유사하다
그리고 acquire과 release 는 다음과 같은 의미를 갖고 있는데
-
// Load-Acquire 수행
-
int ready = g_guard.load(memory_order_acquire);
-
// memory_order_acquire 이후부터는 Release 이전에 쓰여진 메모리 값들이 모두 제대로 보인다
-
// 여기에서 Write-Release 수행
-
// memory_order_release 키워드 이후 부터는 지금까지 쓴 내용들이 Acquire 이후에 보여진다.
-
g_guard.store(1, memory_order_release);
명령어가 순서적으로 실행된다는 의미 정도로 생각 하면 될것으로 보인다
acqurie-release 방식으로 사용하면 이 중간에 있는 코드는 메모리 재배치를 하지 않겠다는 의미
fence 라고 해서 앞뒤로 장벽을 처서 명령어 재배치 되지 않게 할수 있는데 (acquire-release 방식으로..)
하지만 결과는 거의동일하다
참고 : fence 을 활용한 Singleton (https://3dmpengines.tistory.com/2200)
ref :http://www.modernescpp.com/index.php/component/jaggyblog/thread-safe-initialization-of-a-singleton
'운영체제 & 병렬처리 > Multithread' 카테고리의 다른 글
| TLS(Thread Local Storage) : thread_local (0) | 2022.09.14 |
|---|---|
| Sequential consistency (순차 일관성) (0) | 2022.09.13 |
| Singleton multithreading programs (1) (0) | 2022.09.13 |
| memory fence(memory barrier) (0) | 2022.09.13 |
| atomic 예시 와 Memory Model (정책) , memory_order_... (0) | 2022.09.12 |