
atomic<bool> flag = false;
//true 가 나오면 원래 원자적으로 처리 되는거라 lock 할 필요 없음
bool isAtomic = flag.is_lock_free();
//flag.store(true);
flag.store(true, memory_order::memory_order_seq_cst); //위의 한줄과 동일한 연산이다
bool val = flag.load(memory_order::memory_order_seq_cst);기본 적인 store 와 load 이전에 사용했던 것에서 뒤에 인자를 넣어 줄수 있다는 것
#include "pch.h"
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
#include <future>
#include "windows.h"
using namespace std;
atomic<bool> flag = false;
int main()
{
flag = false;
flag.store(true, memory_order::memory_order_seq_cst); //memory_order_seq_cst 가 위에선 기본으로 들어간다
bool val = flag.load(memory_order::memory_order_seq_cst);
{
bool prev = flag; //이렇게 하면 만약 다른 쓰레드에서 flag 값을 중간에 바꾸면 prev 는 falg 과 동일한 값이 아닐 수도 있게된다
flag = true;
}
//위의 것을 원자적으로 한번에 변경 하려면 다음 처럼 하면 된다
{
//이렇게 한번에 처리하는 atomic 의 함수를 사용 하면 된다
bool prev = flag.exchange(true);
}
//cas (compare-and-swap) 조건부 수정
{
bool expected = false;
bool desired = true;
flag.compare_exchange_strong(expected, desired); //현재 값이 기대한 값과 같다면 희망하는 값으로 바꿔주는 함수
}
{
bool expected = false;
bool desired = true;
flag.compare_exchange_weak(expected, desired); //동작은 compare_exchange_strong 과 같은데 spruious failure 가 발생 할 수 있다
//즉 이 함수 내에서 다른 스레드의 Interruption 을 받아서 값 변경이 중간에 실패 할 수 있음
//lock 해야 하는데 다른곳에서 먼저 lock 해서 가짜 wakup 이 일어나 제대로 처리 되지 않는 묘한 상황이 발생 할 수 있다는 것
//compare_exchange_weak 이게 기본적인 형태인데 만약에 이렇게 실패가 일어나면 다시 한번 시도해서 성공할대까지 시도하는게 compare_exchange_strong 이 된다
//compare_exchange_strong 그래서 이게 좀 더 부하가 있을 수 있다
//그래서 compare_exchange_weak 이걸 사용할대는 while 루프를 사용해서 처리 한다, 하지만 성능 차이가 엄청 크게 차이 나진 않는다
}
return 0;
}compare_exchange_weak 같은 경우
compare_exchange_weak 함수 내에서 if(flag==expected){ 여기 안에서 실패 발생 가능성 } 이런 내부적 유사구문에서 실패를 할수 있기 때문에 가짜기상이 일어날 수 있다 compare_exchange_strong 같은경우는 이 실패가 일어날 경우 성공 할떄까지 반복해서 실행하게 된다
그래서 compare_exchange_weak 은 while 루프와 함께 사용 되어서 성공할때까지 시도 하는 형태로 코드를 작성하게 된다
Memory Model (정책) 에는 다음과 같은 것들이 있다
load, store 의 뒤에 넣는 인자들이 다음 처럼 있다는 얘기
- Sequentianlly Consistent (seq_cst)
- Acquire-Release (consume, acquire, release, acq_rel)
- Relaxed (relaxed)
consume 은 뭔가 문제가 있음
여기서 중요한것은 seq_cst, acquire, release, acq_rel 이렇게 4개 이다
이 중 acq_rel 이것은 acquire, release 을 합처 놓은 것이다
정리하면..
- Sequentianlly Consistent (memory_order_seq_cst) : 가장 엄격
[컴파일러에서 최적화 여지 적음=>코드 직관적] =>코드 재배치 잘 안됨 : 가시성 문제와 코드 재배치 문제가 해결 된다 - Acquire-Release (memory_order_acquire, memory_order_release) : 중간 엄격
ex) ready.store(true, memory_order_release);
release 명령 이전의 메모리 명령들이, 해당 명령 이후로 재배치 되는 것을 막는다 => 즉 재배치 억제
ready.store(true, memory_order_acquire); // acquire 로 같은 변수를 읽는 쓰레드가 있다면
release 이전의 명령들이 ->acqurie 하는 순간에 관찰 가능하다(가시성 보장)
즉 memory_order_release와 memory_order_relase 이전의 내용들이
memory_order_acquire 한 이후의 가시성이 보장이 된다는 얘기,
다시 말해 memory_order_release 이전에 오는 모든 메모리 명령들이 memory_order_acquire 한
이후의 해당 쓰레드에 의해서 관찰 될 수 있어야 합니다. - Relaxed (memory_order_relaxed) : 사용할 일이 거의 없다
자유로워짐 [컴파일러 최적화 여지가 많다 => 코드가 복잡] =>
코드 재배치 잘 될 수 있음, 가시성도 해결 되지 못한다
단 동일 객체에 대한 동일 수정 순서만 보장한다
참고 (https://3dmpengines.tistory.com/2198?category=511463)
atomic 은 아무것도 입력하지 않으면 seq_cst 이 기본 버전으로 처리 된다 => 가장 많이 사용 됨
[1] atomic 중에서 memory_order::memory_order_seq_cst
#include "pch.h"
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
#include <future>
#include "windows.h"
using namespace std;
atomic<bool> ready = false;
int32 value;
void producer()
{
value = 10;
//seq_cst를 하게 되면 ready 이 값이 consumer 에서의 ready 에서도 그대로 보이고 재배치문제도 해결됨
// cst 를 하게 되면 value 값이 cst 이후에 정확하게 갱신되어 값이 이후에 보여지게 된다
//releaxed 같은 경우는 재배치로 인해 0이 나올 수도 있다, 대부분 테스트하면 10이 나오긴 하지만..
ready.store(true, memory_order::memory_order_seq_cst);
}
void consumer()
{
while (ready.load(memory_order::memory_order_seq_cst) == false)
;
cout << value << endl;
}
int main()
{
ready = false;
value = 0;
thread t1(producer);
thread t2(consumer);
t1.join();
t2.join();
/*
memory_order_seq_cst 이걸 쓰면 가시성 문제와 코드 재배치 문제가 해결 된다!!!
모든게 정상적으로 작동
*/
return 0;
}ready.store(true, memory_order::memory_order_seq_cst); 이 한줄에 대해서만
memory_order_seq_cst
memory_order_seq_cst 는 메모리 명령의 순차적 일관성(sequential consistency) 을 보장해줍니다.
순차적 일관성이란, 메모리 명령 재배치도 없고, 모든 쓰레드에서 모든 시점에 동일한 값을 관찰할 수 있는, 여러분이 생각하는 그대로 CPU 가 작동하는 방식이라 생각하면 됩니다.
memory_order_seq_cst 를 사용하는 메모리 명령들 사이에선 이러한 순차적 일관성을 보장해줍니다.
[3] atomic 중에서 memory_order_relaxed
#include "pch.h"
#include <iostream>
#include <thread>
#include <mutex>
#include <chrono>
#include <future>
#include "windows.h"
using namespace std;
atomic<bool> ready = false;
int32 value;
void producer()
{
value = 10;
ready.store(true, memory_order::memory_order_relaxed);
}
void consumer()
{
while (ready.load(memory_order::memory_order_relaxed) == false)
;
cout << value << endl;
}
int main()
{
ready = false;
value = 0;
thread t1(producer);
thread t2(consumer);
t1.join();
t2.join();
return 0;
}memory_order_relaxed : 가장 루즈한 규칙으로 가시성과 코드 재배치가 해결되지 않는다
사실상 거의 쓰이지 않는다
즉
value = 10;
ready.store(true, memory_order::memory_order_relaxed);
이 코드가
ready.store(true, memory_order::memory_order_relaxed);
value = 10;
이렇게 컴파일 될 수도 있단 얘기임
또 다른 얘시
#include <atomic>
#include <cstdio>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
void t1(std::atomic<int>* a, std::atomic<int>* b) {
b->store(1, memory_order_relaxed); // b = 1 (쓰기)
int x = a->load(memory_order_relaxed); // x = a (읽기)
printf("x : %d \n", x);
}
void t2(std::atomic<int>* a, std::atomic<int>* b) {
a->store(1, memory_order_relaxed); // a = 1 (쓰기)
int y = b->load(memory_order_relaxed); // y = b (읽기)
printf("y : %d \n", y);
}
int main() {
std::vector<std::thread> threads;
std::atomic<int> a(0);
std::atomic<int> b(0);
threads.push_back(std::thread(t1, &a, &b));
threads.push_back(std::thread(t2, &a, &b));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}성공적으로 컴파일 하였다면 아래와 같은 결과들을 확인할 수 있습니다.
실행 결과
x : 1
y : 0
혹은
실행 결과
x : 0
y : 1
혹은
실행 결과
y : 1
x : 1
을 말이지요.
b->store(1, memory_order_relaxed); // b = 1 (쓰기)
int x = a->load(memory_order_relaxed); // x = a (읽기)store 과 load 는 atomic 객체들에 대해서 원자적으로 쓰기와 읽기를 지원해주는 함수 입니다. 이 때, 추가적인 인자로, 어떠한 형태로 memory_order 을 지정할 것인지 전달할 수 있는데, 우리의 경우 가장 느슨한 방식인 memory_order_relaxed 를 전달하였습니다.
여기서 잠깐 궁금한게 있습니다. 과연 아래와 같은 결과를 볼 수 있을까요?
실행 결과
x : 0
y : 0
상식적으로는 불가능 합니다. 왜냐하면 x, y 둘다 0 이 나오기 위해서는 x = a 와 y = b 시점에서 a 와 b 모두 0 이어야만 합니다. 하지만 위 명령어들이 순서대로 실행된다면 이는 불가능 하다는 사실을 알 수 있습니다.
예를 들어서 x 에 0 이 들어가려면 a 가 0 이어야 합니다. 이 말은 즉슨, x = a 가 실행된 시점에서 a = 1 이 실행되지 않았어야만 합니다. 따라서 t2 에서 y = b 를 할 때 이미 b 는 1 인 상태이므로, y 는 반드시 1 이 출력되어야 하지요.
하지만, 실제로는 그렇지 않습니다. memory_order_relaxed 는 앞서 말했듯이, 메모리 연산들 사이에서 어떠한 제약조건도 없다고 하였습니다. 다시 말해 서로 다른 변수의 relaxed 메모리 연산은 CPU 마음대로 재배치 할 수 있습니다 (단일 쓰레드 관점에서 결과가 동일하다면).
예를 들어서
int x = a->load(memory_order_relaxed); // x = a (읽기)
b->store(1, memory_order_relaxed); // b = 1 (쓰기)순으로 CPU 가 순서를 재배치 하여 실행해도 무방하다는 뜻입니다.
그렇다면 이 경우 x 와 y 에 모두 0 이 들어가겠네요. memory_order_relaxed 는 CPU 에서 메모리 연산 순서에 관련해서 무한한 자유를 주는 것과 같습니다. 덕분에 CPU 에서 매우 빠른 속도로 실행할 수 있게됩니다.
이렇게 relaxed 메모리 연산을 사용하면 예상치 못한 결과를 나을 수 있지만, 종종 사용할 수 있는 경우가 있습니다.
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
void worker(std::atomic<int>* counter) {
for (int i = 0; i < 10000; i++) {
// 다른 연산들 수행
counter->fetch_add(1, memory_order_relaxed);
}
}
int main() {
std::vector<std::thread> threads;
std::atomic<int> counter(0);
for (int i = 0; i < 4; i++) {
threads.push_back(std::thread(worker, &counter));
}
for (int i = 0; i < 4; i++) {
threads[i].join();
}
std::cout << "Counter : " << counter << std::endl;
}
성공적으로 컴파일 하였다면
실행 결과
Counter : 40000
와 같이 나옵니다. 여기서 중요한 부분은
counter->fetch_add(1, memory_order_relaxed);로 이는 counter ++ 와 정확히 하는 일이 동일하지만, counter++ 와는 다르게 메모리 접근 방식을 설정할 수 있습니다. 위 문장 역시 원자적으로 counter 의 값을 읽고 1 을 더하고 다시 그 결과를 씁니다.
다만 memory_order_relaxed 를 사용할 수 있었던 이유는, 다른 메모리 연산들 사이에서 굳이 counter 를 증가시키는 작업을 재배치 못하게 막을 필요가 없기 때문입니다. 비록 다른 메모리 연산들 보다 counter ++ 이 늦게 된다고 하더라도 결과적으로 증가 되기만 하면 문제 될게 없기 때문 입니다, 그렇다고 이것을 권하는 것은 아님
[2] memory_order_acquire 과 memory_order_release
memory_order_relaxed 가 사용되는 경우가 있다고 하더라도 너무나 CPU 에 많은 자유를 부여하기에 그 사용 용도는 꽤나 제한적입니다. 이번에 살펴볼 것들은 memory_order_relaxed 보다 살짝 더 엄격한 친구들 입니다.
relaxed 로 된ㄷ 아래와 같은 producer - consumer 관계를 생각해봅시다.
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
void producer(std::atomic<bool>* is_ready, int* data) {
*data = 10;
is_ready->store(true, memory_order_relaxed);
}
void consumer(std::atomic<bool>* is_ready, int* data) {
// data 가 준비될 때 까지 기다린다.
while (!is_ready->load(memory_order_relaxed)) {
}
std::cout << "Data : " << *data << std::endl;
}
int main() {
std::vector<std::thread> threads;
std::atomic<bool> is_ready(false);
int data = 0;
threads.push_back(std::thread(producer, &is_ready, &data));
threads.push_back(std::thread(consumer, &is_ready, &data));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}
성공적으로 컴파일 하였다면
실행 결과
Data : 10
일반적인 경우 위와 같이 나옵니다. 하지만, 아래와 같은 결과를 얻을 수 도 있을까요?
실행 결과
Data : 0
있습니다! 왜냐하면 producer 쓰레드를 살펴보자면
*data = 10;
is_ready->store(true, memory_order_relaxed);위 is_ready 에 쓰는 연산이 relaxed 이기 때문에 위의 *data = 10 과 순서가 바뀌어서 실행된다면 is_ready 가 true 임에도 *data = 10 이 채 실행이 끝나지 않을 수 있다는 것이지요.
따라서 consumer 쓰레드에서 is_ready 가 true 가 되었음에도 제대로된 data 를 읽을 수 없는 상황이 벌어집니다.
consumer 쓰레드에서도 마찬가지 입니다.
while (!is_ready->load(memory_order_relaxed)) {
}
std::cout << "Data : " << *data << std::endl;아래에 data 를 읽는 부분과 위 is_ready 에서 읽는 부분이 순서가 바뀌어 버린다면, is_ready 가 true 가 되기 이전의 data 값을 읽어버릴 수 있다는 문제가 생깁니다. 따라서 위와 같은 생산자 - 소비자 관계에서는 memory_order_relaxed 를 사용할 수 없습니다.
본론으로 돌아와서.. memory_order_release, memory_order_acquire 된 코드
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
void producer(std::atomic<bool>* is_ready, int* data) {
*data = 10;
is_ready->store(true, std::memory_order_release);
//----------------------여기부터 ---------------------------------
//is_ready->store(true, std::memory_order_release); 이코드 위에 있는 것들이
//--------줄 아래로 내려갈 수 없다는 것을 말한다
}
void consumer(std::atomic<bool>* is_ready, int* data) {
// data 가 준비될 때 까지 기다린다.
//memory_order_acquire 는 같은 변수로 읽는 스레드가 있다면 release 이전의 명령들이
//acquire 하는 순간에 관찰 가능하다
//----------------------여기까지 ---------------------------------
//!is_ready->load(std::memory_order_acquire) 아래 있는 명령들이 이 위로 못올라오게 막고
//is_ready->store(true, std::memory_order_release); 이전의 내용들이
//memory_order_acquire 이후에 모두다 값들이 갱신되어 정확히 보여지게 된다
while (!is_ready->load(std::memory_order_acquire))
{
}
std::cout << "Data : " << *data << std::endl;
}
int main() {
std::vector<std::thread> threads;
std::atomic<bool> is_ready(false);
int data = 0;
threads.push_back(std::thread(producer, &is_ready, &data));
threads.push_back(std::thread(consumer, &is_ready, &data));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}
성공적으로 컴파일 하였다면
실행 결과
Data : 10
와 같이 나옵니다. 이 경우 data 에 0 이 들어가는 일은 불가능 합니다. 이유는 아래와 같습니다.
*data = 10;
is_ready->store(true, std::memory_order_release);memory_order_release 는 해당 명령 이전의 모든 메모리 명령들이 해당 명령 이후로 재배치 되는 것을 금지 합니다. 또한, 만약에 같은 변수를 memory_order_acquire 으로 읽는 쓰레드가 있다면, memory_order_release 이전에 오는 모든 메모리 명령들이 해당 쓰레드에 의해서 관찰 될 수 있어야 합니다.
쉽게 말해 is_ready->store(true, std::memory_order_release); 밑으로 *data = 10 이 올 수 없게 됩니다.
또한 is_ready 가 true 가 된다면, memory_order_acquire 로 is_ready 를 읽는 쓰레드에서 data 의 값을 확인했을 때 10 임을 관찰할 수 있어야하죠.
while (!is_ready->load(std::memory_order_acquire)) {
}
실제로 cosnumer 쓰레드에서 is_ready 를 memory_order_acquire 로 load 하고 있기에, is_ready 가 true 가 된다면, data 는 반드시 10 이어야만 합니다.
memory_order_acquire 의 경우, release 와는 반대로 해당 명령 뒤에 오는 모든 메모리 명령들이 해당 명령 위로 재배치 되는 것을 금지 합니다.
이와 같이 두 개의 다른 쓰레드들이 같은 변수의 release 와 acquire 를 통해서 동기화 (synchronize) 를 수행하는 것을 볼 수 있습니다.
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
using std::memory_order_relaxed;
std::atomic<bool> is_ready;
std::atomic<int> data[3];
void producer() {
data[0].store(1, memory_order_relaxed);
data[1].store(2, memory_order_relaxed);
data[2].store(3, memory_order_relaxed);
is_ready.store(true, std::memory_order_release);
}
void consumer() {
// data 가 준비될 때 까지 기다린다.
while (!is_ready.load(std::memory_order_acquire)) {
}
std::cout << "data[0] : " << data[0].load(memory_order_relaxed) << std::endl;
std::cout << "data[1] : " << data[1].load(memory_order_relaxed) << std::endl;
std::cout << "data[2] : " << data[2].load(memory_order_relaxed) << std::endl;
}
int main() {
std::vector<std::thread> threads;
threads.push_back(std::thread(producer));
threads.push_back(std::thread(consumer));
for (int i = 0; i < 2; i++) {
threads[i].join();
}
}성공적으로 컴파일 하였다면
실행 결과
data[0] : 1
data[1] : 2
data[2] : 3
data[0].store(1, memory_order_relaxed);
data[1].store(2, memory_order_relaxed);
data[2].store(3, memory_order_relaxed);
is_ready.store(true, std::memory_order_release);여기서 data 의 원소들을 store 하는 명령들은 모두 relaxed 때문에 자기들 끼리는 CPU 에서 마음대로 재배치될 수 있겠지만, 아래 release 명령을 넘어가서 재배치될 수 는 없습니다.
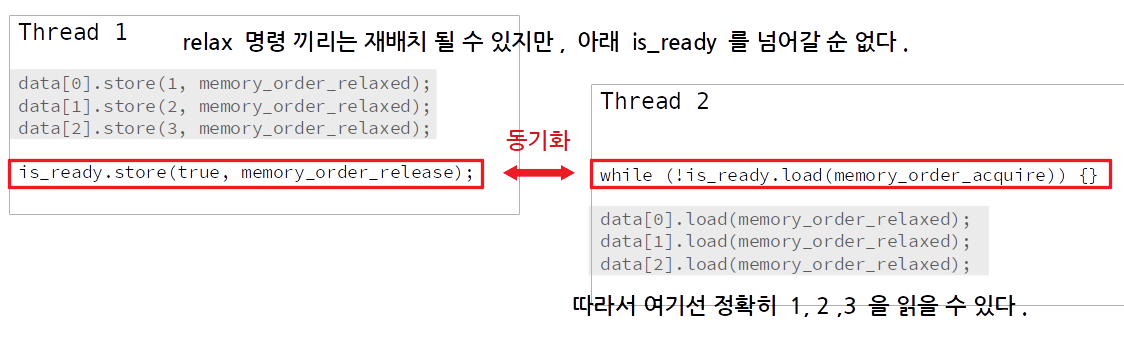
release - acquire 동기화
따라서 consumer 에서 data 들의 값을 확인했을 때 언제나 정확히 1, 2, 3 이 들어있게 됩니다.
[4] memory_order_acq_rel
memory_order_acq_rel 은 이름에서도 알 수 있듯이, acquire 와 release 를 모두 수행하는 것입니다. 이는, 읽기와 쓰기를 모두 수행하는 명령들, 예를 들어서 fetch_add 와 같은 함수에서 사용될 수 있습니다.
Sequentially-consistent Ordering
memory_order_seq_cst 플래그로 설정된 아토믹 객체는 memory_order_seq_cst와 마찬가지로 store 이전의 상황이 다른 스레드의 load시 동기화가 되는 기능을 제공한다. 또한 memory_order_seq_cst는 "single total modification order" 단일 수정 순서 = 전지적 시점에서 실행된 순서가 모든 아토믹 객체를 사용하는 쓰레드 사이에 동기화된다.
#include <atomic>
#include <iostream>
#include <thread>
std::atomic<bool> x(false);
std::atomic<bool> y(false);
std::atomic<int> z(0);
void write_x() { x.store(true, std::memory_order_release); }
void write_y() { y.store(true, std::memory_order_release); }
void read_x_then_y() {
while (!x.load(std::memory_order_acquire)) {
}
if (y.load(std::memory_order_acquire)) {
++z;
}
}
void read_y_then_x() {
while (!y.load(std::memory_order_acquire)) {
}
if (x.load(std::memory_order_acquire)) {
++z;
}
}
int main() {
thread a(write_x);
thread b(write_y);
thread c(read_x_then_y);
thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
std::cout << "z : " << z << std::endl;
}
성공적으로 컴파일 하였다면
실행 결과
z : 2
혹은
실행 결과
z : 1
과 같이 나옵니다. 그렇다면
실행 결과
z : 0
은 발생할 수 있을까요?
기존 release-acquire 관계를 이용하는 a, b, c, d의 스레드를 실행했을 때 보장하는 것은 다음과 같다.
- write_x()에서 x(store) 이전의 문맥 = read_x_then_y()의 x(load) 시점의 문맥
- write_y()에서 y(store) 이전의 문맥 = read_y_then_x()의 y(load) 시점의 문맥
따라서 실행 결과 값은 다음과 같이 나올 수 있다.
| Z 값 | 전지적 실행 순서 | |
| z = 2 | a -> b -> c(d) -> d(c) | x,y 결과가 정해진 이후 이기 때문에 c, d의 결과는 순서에 상관없이 같다. |
| z = 1 | a -> c -> b -> d b -> d -> a -> c |
쓰레드 c는 y가 0으로 관측되기 때문에 z를 증가시키지 않는다. 혹은 그 반대. |
| z = 0 | CPU 1: a -> c CPU 2: b -> d |
이러한 상황은 두 흐름이 다른 CPU에서 일어날 때 발생한다. |
z = 0인 상황이 발생하는 이유
CPU의 계산 결과가 항상 메모리에 써지는 것은 아니다. 실제 CPU 명령어들을 빨리 처리하기 위해 메모리에 접근하는 것을 피하기 때문에 캐시에 두었다가 캐시에서 내보내질 때 메모리에 쓰는 방식 write-back을 많이 사용한다. 이런 경우 각 CPU마다 고유한 캐시를 사용할 경우 메모리에 직접 쓰기 전까지는 동기화가 안 되어 있을 수 있다.
기존 release-acquire는 store 이전의 상황이 load 시점에서 보이는 것을 보장하나 그러한 release-acquire 발생 사건이 모든 쓰레드에 보여지는 것은 아니다.
예를 들어서
write_x 와 read_x_and_y 쓰레드가 코어 1 에,
write_y 와 read_y_and_x 쓰레드가 코어 2 에
배치되어 있다고 해봅시다.
코어 1 에서 write x 가 끝나고 load x 를 한 시점에서 x 의 값은 true 겠지요?
근데 acquire-release sync 는 해당 사실이 (x 가 true 라는게) 코어 2 에서도 visible 하다는 것은 보장되지 않습니다.
그쪽 세상에서는 x 가 아직 false 여도 괜찮습니다. 물론 여기서 acquire-release sync 에 위배되는 것은 전혀 없습니다. acquire-release 가 보장하는 것은 store x 전에 무언가 작업을 했다면 load x 할 때 해당 작업이 그 쓰레드에서 보여진다 라는 약속밖에 없죠.
반면 memory_order_seq_cst 는 어떤 아토믹 객체에 대한 실제 수정 순서가 모든 스레드에게 동일하게 보임을 보장한다.
atomoic 객체의 기본 memory_order 플래그의 기본 값은 memory_order_seq_cst이다.
하지만 memory_order_seq_cst 를 사용하게 된다면
해당 명령을 사용하는 메모리 연산들 끼리는 모든 쓰레드에서 동일한 연산 순서를 관찰할 수 있도록 보장해줍니다. 참고로 우리가 atomic 객체를 사용할 때, memory_order 를 지정해주지 않는다면 디폴트로 memory_order_seq_cst 가 지정이 됩니다. 예컨대 이전에 counter ++ 은 사실 counter.fetch_add(1, memory_order_seq_cst) 와 동일한 연산입니다.
문제는 멀티 코어 시스템에서 memory_order_seq_cst 가 꽤나 비싼 연산이라는 것입니다.
인텔 혹은 AMD 의 x86(-64) CPU 의 경우에는 사실 거의 순차적 일관성이 보장되서 memory_order_seq_cst 를 강제하더라도 그 차이가 그렇게 크지 않습니다. 하지만 ARM 계열의 CPU 와 같은 경우 순차적 일관성을 보장하기 위해서는 CPU 의 동기화 비용이 매우 큽니다. 따라서 해당 명령은 정말 꼭 필요 할 때만 사용해야 합니다.
#include <atomic>
#include <iostream>
#include <thread>
using std::memory_order_seq_cst;
using std::thread;
std::atomic<bool> x(false);
std::atomic<bool> y(false);
std::atomic<int> z(0);
void write_x() { x.store(true, memory_order_seq_cst); }
void write_y() { y.store(true, memory_order_seq_cst); }
void read_x_then_y() {
while (!x.load(memory_order_seq_cst)) {
}
if (y.load(memory_order_seq_cst)) {
++z;
}
}
void read_y_then_x() {
while (!y.load(memory_order_seq_cst)) {
}
if (x.load(memory_order_seq_cst)) {
++z;
}
}
int main() {
thread a(write_x);
thread b(write_y);
thread c(read_x_then_y);
thread d(read_y_then_x);
a.join();
b.join();
c.join();
d.join();
std::cout << "z : " << z << std::endl;
}위 코드는 memory_order_seq_cst 로 바꾼 코드이다
성공적으로 컴파일 하였다면
실행 결과
z : 2
혹은
실행 결과
z : 1
과 같이 나옵니다. x.store 와 y.store 가 모두 memory_order_seq_cst 이므로, read_x_then_y 와 read_y_then_x 에서 관찰했을 때 x.store 와 y.store 가 같은 순서로 발생해야 합니다. 따라서 z 의 값이 0 이 되는 경우는 발생하지 않습니다.
즉 다른 CPU 에서
CPU 1: a -> c
CPU 2: b -> d
이렇게 돌아도 다른 cpu 에서 상대의 공유 값을 가시적으로 볼 수 있다는것(정확히 볼 수 있다는 것)
정리해보자면 다음과 같습니다.
연산허용된 memory order
| 쓰기 (store) | memory_order_relaxed, memory_order_release, memory_order_seq_cst |
| 읽기 (load) | memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_seq_cst |
| 읽고 - 수정하고 - 쓰기 (read - modify - write) | memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel, memory_order_seq_cst |
참고로 memory_order_consume 은 다루지 않았는데 C++ 17 현재, memory_order_consume 의 정의가 살짝 수정 중에 있기에 memory_order_consume 의 사용이 권장되지 않습니다.
이렇게 C++ 에서 atomic 연산들에 대해 memory_order 을 지정하는 방법에 대해 알아보았습니다. C++ atomic 객체들의 경우 따로 지정하지 않는다면 기본으로 memory_order_seq_cst 로 설정되는데,
이는 일부 CPU 에서 매우 값비싼 명령 입니다. 만약에 제약 조건을 좀 더 느슨하게 할 수 있을 때 더 약한 수준의 memory_order 을 사용한다면 프로그램의 성능을 더 크게 향상 시킬 수 있습니다.
'운영체제 & 병렬처리 > Multithread' 카테고리의 다른 글
| Singleton multithreading programs (1) (0) | 2022.09.13 |
|---|---|
| memory fence(memory barrier) (0) | 2022.09.13 |
| 원자적 연산과 동일한객체 동일한 수정 순서 (0) | 2022.09.12 |
| 코드 재배치 및 메모리 가시성문제 예제 (0) | 2022.09.12 |
| CPU 파이프라인과 코드 재배치 (0) | 2022.09.12 |