개체의 새로운 인스턴스는 해당 개체에 할당된 프로토타입의 동작을 "상속"받습니다. 새로운 객체를 prototype 에 대입하면 대입된 객체가 부모가 됨
예를 들어 가장 큰 배열 요소의 값을 반환하는 Array 개체에 메서드를 추가하려면 함수를 선언하고 이를 Array.prototype에 추가한 후 사용합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
function array_max( )
{
var i, max =this[0]; //이때 this 는 자기자신 배열의 원소들을 가져오기위한 용도로 사용된다
for (i =1; i < this.length; i++)
{
if (max <this[i])
max =this[i];
}
return max;
}
Array.prototype.max = array_max;
var myArray =newArray(7, 1, 3, 11, 25, 9);
document.write(myArray.max());
// 결과 :
// 25
JavaScript는 클래스라는 개념이 없습니다. 그래서 기존의 객체를 복사하여(cloning) 새로운 객체를 생성하는 프로토타입 기반의 언어입니다. 프로토타입 기반 언어는 객체 원형인 프로토타입을 이용하여 새로운 객체를 만들어냅니다. 이렇게 생성된 객체 역시 또 다른 객체의 원형이 될 수 있습니다. 프로토타입은 객체를 확장하고 객체 지향적인 프로그래밍을 할 수 있게 해줍니다. 프로토타입은 크게 두 가지로 해석됩니다. 프로토타입 객체를 참조하는 prototype 속성과 객체 멤버인 proto 속성이 참조하는 숨은 링크가 있습니다. 이 둘의 차이점을 이해하기 위해서는 JavaScript 함수와 객체의 내부적인 구조를 이해 해야합니다. 이번 글에서는 JavaScript의 함수와 객체 내부 구조부터 시작하여 프로토타입에 대해 알아보겠습니다.
1. 함수와 객체의 내부 구조
JavaScript에서는 함수를 정의하고, 파싱단계에 들어가면, 내부적으로 수행되는 작업이 있습니다. 함수 멤버로 prototype 속성이 있습니다. 이 속성은 다른 곳에 생성된 함수이름의 프로토타입 객체를 참조합니다. 프로토타입 객체의 멤버인 constructor 속성은 함수를 참조하는 내부구조를 가집니다. 아래의 그림 1과 같이 표현합니다.
tip : 이미지상 오른쪽을로 '프로토타입 객체' 라고 하는데, '프로토타입 객체'라는 두 단어가 각각 다른것을 의미하는 것이 아니고 두단어가 합쳐져 프로토타입객체 라고 칭하고있음
[그림 1]
function Person(){}
[소스 1]
속성이 하나도 없는 Person이라는 함수가 정의되고, 파싱단계에 들어가면, Person 함수 Prototype 속성은 프로토타입 객체를 참조합니다. 프로토타입 객체 멤버인 constructor 속성은 Person 함수를 참조하는 구조를 가집니다. 여기서 알아야 하는 부분은 Person 함수의 prototype 속성이 참조하는 프로토타입 객체는 new라는 연산자와 Person 함수를 통해 생성된 모든 객체의 원형이 되는 객체입니다. 생성된 모든 객체가 참조한다는 것을 기억해야 합니다. 아래의 그림 2와 같이 표현합니다.
[그림 2]
function Person(){}
var joon = new Person();
var jisoo = new Person();
[소스 2]
JavaScript에서는 기본 데이터 타입인 boolean, number, string, 그리고 특별한 값인 null, undefined 빼고는 모두 객체입니다. 사용자가 정의한 함수도 객체이고, new라는 연산자를 통해 생성된 것도 객체입니다. 객체 안에는 proto(비표준) 속성이 있습니다. 이 속성은 객체가 만들어지기 위해 사용된 원형인 프로토타입 객체를 숨은 링크로 참조하는 역할을 합니다.
2. 프로토타입 객체란?
함수를 정의하면 다른 곳에 생성되는 프로토타입 객체는 자신이 다른 객체의 원형이 되는 객체입니다. 모든 객체는 프로토타입 객체에 접근할 수 있습니다. 프로토타입 객체도 동적으로 런타임에 멤버를 추가할 수 있습니다. 같은 원형을 복사로 생성된 모든 객체는 추가된 멤버를 사용할 수 있습니다.
[그림 3]
function Person(){}
var joon = new Person();
var jisoo = new Person();
Person.prototype.getType = function (){
return "인간";
};
console.log(joon.getType()); // 인간
console.log(jisoo.getType()); // 인간
[소스 3]
위 소스 3 6라인은 함수 안의 prototype 속성을 이용하여 멤버를 추가하였습니다. 프로토타입 객체에 getType()이라는 함수를 추가하면 멤버를 추가하기 전에 생성된 객체에서도 추가된 멤버를 사용할 수 있습니다. 같은 프로토타입을 이용하여 생성된 joon과 jisoo 객체는 getType()을 사용할 수 있습니다.
여기서 알아두어야 할 것은 프로토타입 객체에 멤버를 추가, 수정, 삭제할 때는 함수 안의 prototype 속성을 사용해야 합니다. 하지만 프로토타입 멤버를 읽을 때는 함수 안의 prototype 속성 또는 객체 이름으로 접근합니다.
[그림 4]
joon.getType = function (){
return "사람";
};
console.log(joon.getType()); // 사람
console.log(jisoo.getType()); // 인간
jisoo.age = 25;
console.log(joon.age); // undefined
console.log(jisoo.age); // 25
[소스 4]
위 소스 4 1라인은 joon 객체를 이용하여 getType() 리턴 값을 사람으로 수정하였습니다. 그리고 joon과 jisoo에서 각각 getType()을 호출하면 joon 객체를 이용하여 호출한 결과는 사람으로 출력되고, jisoo로 호출한 결과는 인간이 출력됩니다. joon 객체를 사용하여 getType()을 호출하면 프로토타입 객체의 getType()을 호출한 것이 아닙니다. joon 객체에 추가된 getType()을 호출한 것입니다. 프로토타입 객체의 멤버를 수정할 경우는 멤버 추가와 같이 함수의 prototype 속성을 이용하여 수정합니다.
[그림 5]
Person.prototype.getType = function (){
return "사람";
};
console.log(jisoo.getType()); // 사람
[소스 5]
소스 5를 보게 되면 함수의 prototype 속성을 이용하여 getType() 리턴 값을 사람으로 수정합니다. 그리고 jisoo 객체를 이용하여 호출한 결과 사람이 나옵니다.
결론을 내리면, 프로토타입 객체는 새로운 객체가 생성되기 위한 원형이 되는 객체입니다. 같은 원형으로 생성된 객체가 공통으로 참조하는 공간입니다. 프로토타입 객체의 멤버를 읽는 경우에는 객체 또는 함수의 prototype 속성을 통해 접근할 수 있습니다. 하지만 추가, 수정, 삭제는 함수의 prototype 속성을 통해 접근해야 합니다.
3. 프로토타입이란?
JavaScript에서 기본 데이터 타입을 제외한 모든 것이 객체입니다. 객체가 만들어지기 위해서는 자신을 만드는 데 사용된 원형인 프로토타입 객체를 이용하여 객체를 만듭니다. 이때 만들어진 객체 안에 __proto__ (비표준) 속성이 자신을 만들어낸 원형을 의미하는 프로토타입 객체를 참조하는 숨겨진 링크가 있습니다. 이 숨겨진 링크를 프로토타입이라고 정의합니다.
[그림 6]
function Person(){}
var joon = new Person();
[소스 6]
위 그림 6 joon 객체의 멤버인 __proto__ (비표준) 속성이 프로토타입 객체를 가리키는 숨은 링크가 프로토타입이라고 합니다. 프로토타입을 크게 두 가지로 해석된다 했습니다.
함수의 멤버인 prototype 속성은 프로토타입 객체를 참조하는 속성입니다. 그리고 함수와 new 연산자가 만나 생성한 객체의 프로토타입 객체를 지정해주는 역할을 합니다. 객체 안의 __proto__(비표준) 속성은 자신을 만들어낸 원형인 프로토타입 객체를 참조하는 숨겨진 링크로써 프로토타입을 의미합니다.
JavaScript에서는 숨겨진 링크가 있어 프로토타입 객체 멤버에 접근할 수 있습니다. 그래서 이 프로토타입 링크를 사용자가 정의한 객체에 링크가 참조되도록 설정하면 코드의 재사용과 객체 지향적인 프로그래밍을 할 수 있습니다.
4. 코드의 재사용
코드의 재사용 하면 떠오르는 단어는 바로 상속입니다. 클래스라는 개념이 있는 Java에서는 중복된 코드를 상속받아 코드 재활용을 할 수 있습니다. 하지만 JavaScript에서는 클래스가 없는, 프로토타입 기반 언어입니다. 그래서 프로토타입을 이용하여 코드 재사용을 할 수 있습니다.
이 방법에도 크게 두 가지로 분류할 수 있습니다. classical 방식과 prototypal 방식이 있습니다. classical 방식은 new 연산자를 통해 생성한 객체를 사용하여 코드를 재사용 하는 방법입니다. 마치 Java에서 객체를 생성하는 방법과 유사하여 classical 방식이라고 합니다. prototypal 방식은 리터럴 또는 Object.create()를 이용하여 객체를 생성하고 확장해 가는 방식입니다. 두 가지 방법 중 JavaScript에서는 prototypal 방식을 더 선호합니다. 그 이유는 classical 방식보다 간결하게 구현할 수 있기 때문입니다. 밑의 예제 1 ~ 4번까지는 classical 방식의 코드 재사용 방법이고, 5번은 prototypal 방식인 Object.create()를 사용하여 코드의 재사용을 보여줍니다.
(1) 기본 방법
부모에 해당하는 함수를 이용하여 객체를 생성합니다. 자식에 해당하는 함수의 prototype 속성을 부모 함수를 이용하여 생성한 객체를 참조하는 방법입니다.
[그림 7]
function Person(name) {
this.name = name || "혁준";
}
Person.prototype.getName = function(){
return this.name;
};
function Korean(name){}
Korean.prototype = new Person();
var kor1 = new Korean();
console.log(kor1.getName()); // 혁준
var kor2 = new Korean("지수");
console.log(kor2.getName()); // 혁준
[소스 7]
위 소스 7을 보면 부모에 해당하는 함수는 Person입니다. 10라인에서 자식 함수인 Korean 함수 안의 prototype 속성을 부모 함수로 생성된 객체로 바꿨습니다. 이제 Korean 함수와 new 연산자를 이용하여 생성된 kor 객체의 __proto__속성이 부모 함수를 이용하여 생성된 객체를 참조합니다. 이 객체가 Korean 함수를 이용하여 생성된 모든 객체의 프로토타입 객체가 됩니다. kor1에는 name과 getName() 이라는 속성이 없지만, 부모에 해당하는 프로토타입객체에 name이 있습니다. 이 프로토타입객체의 부모에 getName()을 가지고 있어 kor1에서 사용할 수 있습니다. 이 방법에도 단점이 있습니다. 부모 객체의 속성과 부모 객체의 프로토타입 속성을 모두 물려받게 됩니다. 대부분의 경우 객체 자신의 속성은 특정 인스턴스에 한정되어 재사용할 수 없어 필요가 없습니다. 또한, 자식 객체를 생성할 때 인자를 넘겨도 부모 객체를 생성할 때 인자를 넘겨주지 못합니다. 그림 7 소스 하단 두 번째 줄에서 kor2 객체를 생성할 때 Korean 함수의 인자로 지수라고 주었습니다. 객체를 생성한 후 getName()을 호출하면 지수라고 출력될 거 같지만, 부모 생성자에 인자를 넘겨주지 않았기 때문에 name에는 default 값인 혁준이 들어있습니다. 객체를 생성할 때마다 부모의 함수를 호출할 수도 있습니다. 하지만 매우 비효율적입니다. 그래서 다음 방법은 이 방법의 문제점을 해결하는 방법을 알아보겠습니다.
(2) 생성자 빌려 쓰기
이 방법은 기본 방법의 문제점인 자식 함수에서 받은 인자를 부모 함수로 인자를 전달하지 못했던 부분을 해결합니다. 부모 함수의 this에 자식 객체를 바인딩하는 방식입니다.
[그림 8]
function Person(name) {
this.name = name || "혁준";
}
Person.prototype.getName = function(){
return this.name;
};
function Korean(name){
Person.apply(this, arguments);
}
var kor1 = new Korean("지수");
console.log(kor1.name); // 지수
[소스 8]
위 소스 8 10라인을 보면 Korean 함수 내부에서 apply 함수를 이용합니다.
부모객체인 Person 함수 영역의 this를 Korean 함수 안의 this로 바인딩합니다. 함수를 호출하여 지정된 개체를 함수의 this 값으로 대체하고 지정된 배열을 함수의 인수로 대체합니다.
객체를 생성하고, name을 출력합니다. 객체를 생성할 때 넘겨준 인자를 출력하는 것을 볼 수 있습니다. 기본 방법에서는 부모객체의 멤버를 참조를 통해 물려받았습니다. 하지만 생성자 빌려 쓰기는 부모객체 멤버를 복사하여 자신의 것으로 만들어 버린다는 차이점이 있습니다. 하지만 이 방법은 부모객체의 this로 된 멤버들만 물려받게 되는 단점이 있습니다. 그래서 부모객체의 프로토타입 객체의 멤버들을 물려받지 못합니다. 위 그림 8 그림을 보시면 kor1 객체에서 부모객체의 프로토타입 객체에 대한 링크가 없다는 것을 볼 수 있습니다.
(3) 생성자 빌려 쓰고 프로토타입 지정해주기
이 방법은 방법 1과 방법 2 문제점들을 보완하면서 Java에서 예상할 수 있는 동작 방식과 유사합니다.
[그림 9]
function Person(name) {
this.name = name || "혁준"; }
Person.prototype.getName = function(){
return this.name;
};
function Korean(name){
Person.apply(this, arguments);
}
Korean.prototype = new Person();
var kor1 = new Korean("지수");
console.log(kor1.getName()); // 지수
[소스 9]
위 소스 9 9라인에서 부모 함수 this를 자식 함수 this로 바인딩합니다. 11라인에서 자식 함수 prototype 속성을 부모 함수를 사용하여 생성된 객체로 지정했습니다. 부모객체 속성에 대한 참조를 가지는 것이 아닌 복사본을 통해 내 것으로 만듭니다. 동시에 부모객체의 프로토타입 객체에 대한 링크도 참조됩니다. 부모객체의 프로토타입 객체 멤버도 사용할 수 있습니다. 그림 7과 비교했을 때 kor1 객체에 name 멤버가 없는 반면 그림 9에서는 name 멤버를 가지고 있는 것을 확인할 수 있습니다. 그림 8과 비교했을 때는 프로토타입 링크가 부모 함수로 생성한 객체에 대해 참조도 하고 있습니다. 그리고 부모 객체의 프로토타입 객체도 링크로 연결된 것을 볼 수 있습니다. 이 방법에도 문제점이 있습니다. 부모 생성자를 두 번 호출합니다. 생성자 빌려 쓰기 방법과 달리 getName()은 제대로 상속되었지만, name에 대해서는 kor1 객체와 부모 함수를 이용하여 생성한 객체에도 있는 것을 볼 수 있습니다.
(4) 프로토타입공유
이번 방법은 부모 생성자를 한 번도 호출하지 않으면서 프로토타입 객체를 공유하는 방법입니다.
[그림 10]
function Person(name) {
this.name = name || "혁준";
}
Person.prototype.getName = function(){
return this.name;
};
function Korean(name){
this.name = name;
}
Korean.prototype = Person.prototype;
var kor1 = new Korean("지수");
console.log(kor1.getName()); // 지수
[소스 10]
위 소스 10 12라인에서 자식 함수의 prototype 속성을 부모 함수의 prototype 속성이 참조하는 객체로 설정했습니다. 자식 함수를 통해 생성된 객체는 부모 함수를 통해 생성된 객체를 거치지 않고 부모 함수의 프로토타입 객체를 부모로 지정하여 객체를 생성합니다. 부모 함수의 내용을 상속받지 못하므로 상속받으려는 부분을 부모 함수의 프로토타입 객체에 작성해야 사용자가 원하는 결과를 얻게 됩니다. 그림 9와 비교했을 때 중간에 부모 함수로 생성한 객체가 없고 부모 함수의 프로토타입 객체로 링크가 참조되는 것을 볼 수 있습니다.
(5) prototypal한 방식의 재사용
이 방법은 Object.create()를 사용하여 객체를 생성과 동시에 프로토타입객체를 지정합니다. 이 함수는 첫 번째 매개변수는 부모객체로 사용할 객체를 넘겨주고, 두 번째 매개변수는 선택적 매개변수로써 반환되는 자식객체의 속성에 추가되는 부분입니다. 이 함수를 사용함으로 써 객체 생성과 동시에 부모객체를 지정하여 코드의 재활용을 간단하게 구현할 수 있습니다.
var person = {
type : "인간",
getType : function(){
return this.type;
},
getName : function(){
return this.name;
}
};
var joon = Object.create(person);
joon.name = "혁준";
console.log(joon.getType()); // 인간
console.log(joon.getName()); // 혁준
[소스 11]
위 소스 1라인에서 부모 객체에 해당하는 person을 객체 리터럴 방식으로 생성했습니다. 그리고 11라인에서 자식 객체 joon은 Object.create() 함수를 이용하여 첫 번째 매개변수로 person을 넘겨받아 joon 객체를 생성하였습니다. 한 줄로 객체를 생성함과 동시에 부모객체의 속성도 모두 물려받았습니다. 위의 1 ~ 4번에 해당하는 classical 방식보다 간단하면서 여러 가지 상황을 생각할 필요도 없습니다. JavaScript에서는 new 연산자와 함수를 통해 생성한 객체를 사용하는 classical 방식보다 prototypal 방식을 더 선호합니다.
자바스크립트의 프로토타입(Prototype) 프로퍼티 란?
모든 함수 객체의 Constructor는 prototype 이란 프로퍼티를 가지고 있다. 이 prototype 프로퍼티는 객체가 생성될 당시 만들어지는 객체 자신의 원형이될 prototype 객체를 가리킨다. 즉 자신을 만든 원형이 아닌 자신을 통해 만들어질 객체들이 원형으로 사용할 객체를 말한다. prototype object는 default로 empty Object 를 가리킨다.
이 말이 매우 어렵게 들릴수도 있다. 하지만 정확히 이해한다면 그리 어려운 말이 아니다. 위에서 분명히 프로토타입은 자기 자신을 생성하게 한 자신의 원형 객체라고 정의했다. 그럼 그 원형객체란 프로토타입은 function A() 함수객체 그 차체일가? 전혀 그렇지 않다.
자바스크립트의 모든 객체는 생성과 동시에 자기자신이 생성될 당시의 정보를 취한 Prototype Object 라는 새로운 객체를 Cloning 하여 만들어낸다. 프로토타입이 객체를 만들어내기위한 원형이라면 이 Prototype Object 는 자기 자신의 분신이며 자신을 원형으로 만들어질 다른 객체가 참조할 프로토타입이 된다. 즉 객체 자신을 이용할 다른 객체들이 프로토타입으로 사용할 객체가 Prototype Object 인 것이다. 즉 위에서 언급한 __proto__라는 prototype 에 대한 link는 상위에서 물려받은 객체의 프로토타입에 대한 정보이며 prototype 프로퍼티는 자신을 원형으로 만들어질 새로운 객체들 즉 하위로 물려줄 연결에 대한 속성이다.
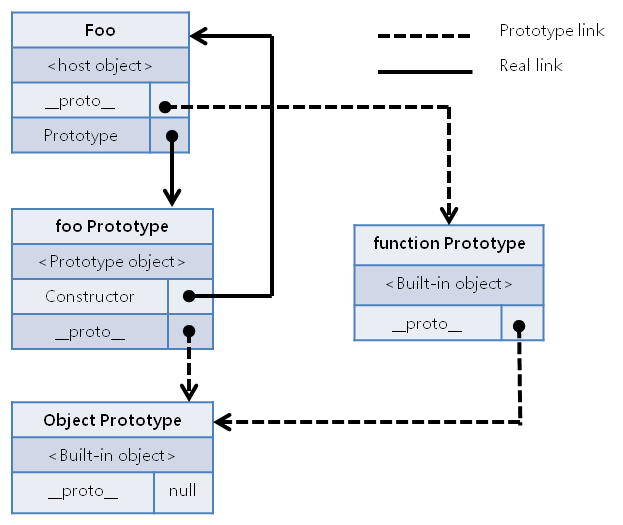
functionfoo(){}varfoo = newfoo();
위 예제코드를 통해 만들어지는 Prototype Link 와 Prototype Property가 가리키는 Prototype Object의 Real Link 에 대한 관계도는 다음과 같다.
1
2
3
4
5
6
7
8
9
10
11
12
//#예제 2.
var A =function () { };
A.x=function() {
console.log('hello');
};
A.prototype.x =function () {
console.log('world');
};
var B =new A();
var C =new A();
B.x(); // 'world'
C.x(); // 'world'
예제2 에서의 결과가 world 가 되는 이유도 같은 이유다. A.prototype 은 A의 Prototype Object를 참조하는 녀석이기 때문에 A.prototype.x 를 정의한다는 것은 A의 Prototype Object를 직접 이용하게 되는 것이고 그에 따라서 A의 Prototype Object를 프로토타입으로 이용하여 만들어지는 B,C 가 알고 있는 x 는 function () {console.log('world');} 가 되는 것이다.
객체는 new Object(), Object.create() 또는 literal 표기법 (initializer 표기법)을 사용하여 초기화될 수 있습니다. 객체 초기자(object initializer)는 0개 이상인 객체 속성명 및 관련값 쌍 목록입니다, 중괄호({})로 묶인.
1
2
3
4
5
6
7
8
9
10
11
var o = {};
var o = { a: "foo", b: 42, c: {} };
var a ="foo", b =42, c = {};
var o = { a: a, b: b, c: c };
var o = {
property: function ([parameters]) {},
get property() {},
set property(value) {},
};
설명
객체 초기자는 Object의 초기화를 기술하는 식(expression)입니다. 객체는 속성으로 구성됩니다, 객체를 설명하는 데 사용되는. 객체의 속성값은 primitive 데이터 형 또는 다른 객체를 포함할 수 있습니다.
객체 생성
속성이 없는 빈 객체는 다음과 같이 만들 수 있습니다:
var object ={};
리터럴(literal) 또는 초기자(initializer) 표기법의 이점은, 빠르게 중괄호 내 속성이 있는 객체를 만들 수 있다는 것입니다. 당신은 그저 쉼표로 구분된 키: 값 쌍 목록을 표기합니다.
다음 코드는 키가 "foo", "age" 및 "baz"인 세 속성이 있는 객체를 만듭니다. 이들 키값은 문자열 "bar", 숫자 42 그리고 세 번째 속성은 그 값으로 다른 객체를 갖습니다.
var object ={
foo:"bar",
age:42,
baz:{ myProp:12},}
javascript : 함수와 객체, new
1
2
3
4
5
6
var n =newNumber();
var s =3;
console.log(typeof n); //대문자 Number 는 정수를 담는 객체, typeof 로 확인 되는 Number 타입 문자열은 object
console.log(typeof s); //변수가 숫자로 정의 될때의 타입은 소문자 문자열로 "number"
결과
object
number
함수가 생성자가 되는 시점
1
2
3
4
5
6
function Person() { //Person 함수 이지만
};
var p =new Person(); //new 함수명을 쓰게 되면 이때 Person 은 생성자가된다
console.log(p); //즉 객체를 만든것
//즉 Person 에 인자를 추가 하게 되면 객체 생성시 생성자 인수를 넘길 수 있는 형태가됨
//단 생성자를 통한 초기화가 이뤄짐으로 멤버 변수에 인자 값을 대입하려면
//this.멤버변수 = 매개변수; 의 형태인 this. 이 들어가야한다
일반 함수 앞에 new 를 붙여 생성하면 이 함수가 생성자가 된다
즉 객체를 생성한다는 것이 javascript 에서 custom 형 객체를 생성하는 법인데
javascript 에선 함수 자체에 this 가 들어가 있다는 것 자체가 원래 함수라기 보단 객체라는 점을 내포하고 있다라고 볼 수 있는 부분이기 대문에
함수가 생성자로 취급 되는 대목이 그렇게 생소하게 와닿지는 않는 부분이긴하다
전역객체와 객체지향 프로그래밍
전역 this 는 전역객체 window 와 동일한 객체를 말한다
즉 this.funcThis === window.funcThis 는 true 를 리턴한다
Func() 가 생성자로 호출 될때 funcThis 변수는 o2 에 대한 this 를 담는 것임으로
funcThis === o2 의 결과는 true 가 된다
그러나 아래의 결과는 false 를 보이는데 전역 왜냐하면 this 와 o2에 대한 this===funcThis 는 서로 다른객체임으로
funcThis === this;
false
이런 결과가 나타남
p.s javascript 가 추구하는 방향을 이해하지 못하는것은 아니지만 그러나 항상 javascript 는 생각 이상으로 이것저것 모아놓은 느낌을 들게한다
일부 ref : https://developer.mozilla.org/ko/docs/Web/JavaScript/Reference/Operators/Object_initializer
일부 ref : https://opentutorials.org/module/532/6571
arguments 개체는 명시적으로 만들 수 없습니다.arguments 개체는 함수가 실행을 시작할 때만 사용할 수 있습니다.함수의 arguments 개체는 배열이 아니지만 배열 요소에 액세스하는 방식과 동일하게 각각의 인수에 액세스할 수 있습니다.n 인덱스는 실제로 arguments 개체의 0n 속성 중 하나에 대한 참조입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
function ArgTest(a, b) {
var s ="";
s +="Expected Arguments: "+ArgTest.length; // 2 : 함수 인자 개수
s +="\n";
s +="Expected Function.arguments: "+ArgTest.arguments.length; //4 : 총 매개변수 개수
s +="\n";
s +="Passed Arguments: "+arguments.length; //4 : 총 매개변수 개수
즉시 실행 함수 (Immediately-invoked function expression)
즉시 실행 함수의 기본 형태는 아래와 같습니다.
1
2
3
(function() {
// statements
})()
함수 표현(Function expression)은 함수를 정의하고, 변수에 함수를 저장하고 실행하는 과정을 거칩니다. 하지만 즉시 실행 함수는 함수를 정의하고 바로 실행하여 이러한 과정을 거치지 않는 특징이 있습니다. 함수를 정의하자마자 바로 호출하는 것을 즉시 실행 함수라고 이해하면 편할 것 같습니다.
Immediately-invoked function expression 영어를 해석하면 즉시-호출 함수 표현 입니다. 즉시 실행 함수(IIFE)는 함수 표현(function expression)과 같이 익명 함수 표현, 기명 함수 표현으로 할 수 있습니다.
1. 즉시 실행 함수 사용법
기명 즉시 실행 함수
1
2
3
4
5
6
7
(functionsquare(x) {
console.log(x*x);
})(2);
(functionsquare(x) {
console.log(x*x);
}(2));
위의 두가지 예는 괄호의 위치가 조금 다를 뿐 같은 기능의 즉시 실행 함수 입니다.
익명 즉시 실행 함수
1
2
3
4
5
6
7
(function(x) {
console.log(x*x);
})(2);
(function(x) {
console.log(x*x);
}(2));
변수에 즉시 실행 함수 저장
즉시 실행 함수도 함수이기 때문에, 변수에 즉시 실행 함수 저장이 가능합니다. 예를 들어 보겠습니다.
1
2
3
4
(mySquare = function(x) {
console.log(x*x);
})(2);
mySquare(3);
변수에 즉시 실행 함수 저장
함수를 mySquare에 저장하고 이 함수를 바로 실행하게 됩니다. mySquare는 즉시 실행 함수를 저장하고 있기 때문에 재호출이 가능하게 됩니다.
마찬가지로 즉시 실행 함수도 함수이기 때문에, 변수에 즉시 실행 함수의 리턴 값 저장도 가능합니다.
1
2
3
4
varmySquare = (function(x) {
returnx*x;
})(2);
console.log(mySquare)
변수에 즉시실행함수 리턴값 저장
위의 두가지는 형태가 유사하지만 엄연히 다른 기능입니다. 괄호의 위치에 주의가 필요할 것 같습니다.
2. 즉시 실행 함수를 사용하는 이유
초기화
즉시 실행 함수는 한 번의 실행만 필요로 하는 초기화 코드 부분에 많이 사용됩니다.
그렇다면 왜 초기화 코드 부분에 많이 사용 할까요? 변수를 전역(global scope)으로 선언하는 것을 피하기 위해서 입니다. 전역에 변수를 추가하지 않아도 되기 때문에 코드 충돌 없이 구현 할 수 있어, 플러그인이나 라이브러리 등을 만들 때 많이 사용됩니다.
예를 하나 들어보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
varinitText;
(function(number) {
vartextList = ["is Odd Text", "is Even Text"];
if(number % 2 == 0) {
initText = textList[1];
} else{
initText = textList[0];
}
})(5);
console.log(initText);
console.log(textList);
즉시실행함수 이용한 초기화
전역에 textList가 저장되지 않고, initText만 초기화 된 것을 확인 할 수 있습니다. 또한 textList는 지역 변수로, 전역 변수와 충돌없이 초기화 할 수 있게 됩니다.
라이브러리 전역 변수의 충돌
jQuery나 Prototype 라이브러리는 동일한 $라는 전역 변수를 사용합니다. 만약, 이 두개의 라이브러리를 같이 사용한다면 $ 변수 충돌이 생기게 됩니다.
즉시 실행 함수를 사용하여 $ 전역 변수의 충돌을 피할 수 있습니다.
1
2
3
(function($) {
// $ 는 jQuery object
})(jQuery);
즉시 실행 함수 안에서 $는 전역변수가 아닌 jQuery object의 지역 변수가 되어, Prototype 라이브러리의 $와 충돌 없이 사용할 수 있습니다.
slice 메서드는 stringObj의 지정된 부분을 포함하는 String 개체를 반환합니다.
slice 메서드는 end로 표시된 문자 앞까지만 복사하고 해당 문자는 포함하지 않습니다.
start가 음수이면 length + start로 처리됩니다. 여기서 length는 배열의 길이입니다.end가 음수이면 length + end로 처리되고,end를 생략하면 stringObj의 끝까지 계속 복사됩니다.end가 start 앞에 나오면 새로운 문자열에 아무 문자도 복사되지 않습니다.
첫 번째 예제에서 slice 메서드는 전체 문자열을 반환합니다.두 번째 예제에서 slice 메서드는 마지막 문자를 제외하고 전체 문자열을 반환합니다.
var str1 = "all good boys do fine";
var slice1 = str1.slice(0);
var slice2 = str1.slice(0,-1);
var slice3 = str1.slice(4);
var slice4 = str1.slice(4, 8);
document.write(slice1 + "<br/>");
document.write(slice2 + "<br/>");
document.write(slice3 + "<br/>");
document.write(slice4);
// Output:// all good boys do fine// all good boys do fin// good boys do fine// good
서버 사이드(server-side)란 네트워크의 한 방식인 클라이언트-서버 구조의 서버 쪽에서 행해지는 처리를 말한다.
예시
HTTP 통신에 있어서 브라우저의 주요 기능 중 하나는 서버에서 HTML 문서를 수신하는 것인데, 브라우저에서 요청한 HTML 문서가 PHP 등의 서버 사이드 스크립트 언어를 포함하고 있으면 서버 쪽에서 이 부분을 처리하여 결과를 브라우저에 송신하게 된다.
(여기서 브라우저를 클라이언트로 이해 하면 됨)
MMORPG(대규모 다중 사용자 온라인 롤플레잉 게임)에서도 클라이언트-서버 구조가 사용된다. 대부분의 게임에서는 게임 캐릭터 정보와 게임 아이템 정보의 위조를 방지하기 위해 이를 서버 사이드로 처리한다.[1]
데이터를 서버 사이드로 처리할 경우의 장단점
(클라이언트 사이드로 처리할 때와 비교하여)
장점: 서버 관리자의 입장에서, 데이터 위조의 가능성을 줄일 수 있다. 서버 쪽의 데이터가 확실한 진위이며 클라이언트 쪽에서 위조해서는 안 되는 민감한 데이터의 경우 서버 사이드로 처리해야 한다. 예로 인터넷 뱅킹의 이체 관련 처리나 MMORPG의 게임 아이템 관련 처리에서는 클라이언트 사이드 처리를 최소화해야 한다. 한편 클라이언트 사용자의 입장에서는 클라이언트 컴퓨터의 처리 부담이 줄어든다.
단점: 서버 관리자의 입장에서, 서버의 처리 부담이 커져 결과적으로 서버 비용이 늘어날 수 있다.
클라이언트 사이드(client-side)란 네트워크의 한 방식인 클라이언트-서버 구조의 클라이언트 쪽에서 행해지는 처리를 말한다.
HTTP 통신에 있어서 브라우저의 주요 기능 중 하나는 서버에서 수신한 HTML 문서를 해석하여 화면에 표시해 주는 것인데, HTML 문서가 동적인 부분을 갖고 있지 않다면 문서 수신이 끝나고부터는 서버와 교신하지 않고 브라우저가 클라이언트 사이드에서 처리하여 화면에 내용을 표시한다.
MMORPG(대규모 다중 사용자 온라인 롤플레잉 게임)에서도 클라이언트-서버 구조가 사용된다. 대부분의 MMORPG는 화려한 그래픽 효과를 사용하는데 이를 위해서는 많은 연산이 필요하며 이러한 연산을 서버 쪽에서 모두 부담할 수 없으므로 그래픽 처리나 소리 처리의 대부분을 클라이언트 사이드로 처리한다.
서버 관리자의 입장에서, 서버의 처리 부담을 줄여서 결과적으로 서버 비용을 줄일 수 있다.
처리하는 데이터가 보안에 민감한 경우, 클라이언트 내에서 처리가 가능한 부분에 대해서는 통신에 대비하여 암호화할 필요가 없으므로 암호화 소요가 줄어든다.
단점
서버 관리자의 입장에서, 클라이언트 사이드에서 처리한 결과를 되받아야 하는 경우, 결과의 진위성을 알기 어렵다. 반대로 말하면 클라이언트 쪽에서 데이터를 위조하기 쉽다. 따라서 서버 쪽의 데이터가 확실한 진위이며 클라이언트 쪽에서 위조해서는 안 되는 민감한 데이터의 경우 서버 사이드로 처리해야 한다. 예로 인터넷 뱅킹의 이체 관련 처리나 위의 MMORPG의 게임 아이템 관련 처리에서는 클라이언트 사이드 처리를 최소화해야 한다.
클라이언트, 서버 나누는 기준 : 웹서버가 설치 되어 있다면 웹서버, 웹 브라우저로 접근한다면 클라이언트
.net 구조 .net 프레임 워크는 마치 자바의 virtual machine 과 유사한 형태로 여기 저기 플랫폼에서 돌아갈 수 있는 기본 환경을 제공을 목표로하며 닷넷 프레임 워크가 있다는 가정하네 C++, C# , VB, JSCRIPT 등이 돌아 갈 수 있게 되고 이것들을 .NET 언어라 하며 어떤 언어이든 간에 공통언어명세(CLS)에 맞게 만들어져있다면 이 언어들은 닷넷 환경에 서 돌아 가는 요구 조건을 갖췄다고 할 수 있다 또한 그림에서 볼 수있듯이 ASP.NET 이 .net framework 안에 들어 가있다는 것은 ASP.NET이 프로그램 랭귀지가 아니고 위에서 설명한것과 마찬가지로 개발기술 이라 한다, 또한 ASP.NET, ADO.NET, CLR 등등이 .net framework 의 구성요소가 된다
ASP.NET의 정의
ASP.NET은 동적 웹 사이트(웹 응용 프로그램)을 만들기 위한 마이크로소프트의 웹 개발 기술이다. 다른 웹 개발기술인 ASP, PHP, JSP는 웹 스크립트 언어(Web Script Language)라고도 부른다. 하지만, ASP.NET은 웹 스크립트 언어라고 부르지 않는다. 웹 개발 기술이라고 하는 것이 가장 정확하다. 이유는 차후에 설명한다.
ASP.NET 버전은 다음과 같이 변화되었다. ASP.NET 1.0(2000년) → ASP.NET 1.1(2003년) →ASP.NET 2.0 (2005년)
ASP.NET은 .NET Framework에서만 동작한다. ASP.NET 1.X는 .NET Framework 1.1에서 ASP.NET 2.0은 .NET Framework 2.0에서 동작한다. 그리고 .NET Framework의 포괄적인 개념은 .NET이다. 따라서 다음과 같은 포함관계가 성립한다.
.NET > .NET Framework > ASP.NET
물론 윈도우 응용프로그램이라면 다음과 같은 포함관계도 성립한다.
.NET > .NET Framework > Windows Programming based C#
웹기술은 로그인의 처리에서 처럼, 웹서버에서 내부 사용되는 로직을 개발하고 동작되게 해주는 프로그래밍언어를 뜻한다. ASP.NET, JSP, PHP, ASP, Perl 등을 모두 웹 기술이라고 할 수 있다. 또한 웹 스크립트 언어라고도 부를 수 있다. ASP, JSP, PHP, Perl 등은 그 이름 자체를 스크립트 언어라도고 지칭할 수 있다. 하지만 ASP.NET 은 언어라고 할 수 없는 것이 ASP.NET을 구현할 수 있는 언어가 C#, VB, J#, C++ 등으로 나뉘어지기 때문에 ASP.NET은 웹 개발 기술이라고만 부른다.
ASP.NET의 장점은 다음과 같다.
강력한 캐싱 기능
강력한 개발도구 TOOL 제공 Visual Studio는 웹, Windows, 콘솔 및 모바일 응용 프로그램까지 개발 할 수 있는 통합 개발 환경(IDE, Integrated Development Environment)이다. 각 ASP.NET의 버전별로 Visual Studio역시 다른 버전이 사용되고 있다. ASP.NET 1.0 → Visual Studio .NET 2002 ASP.NET 1.1 → Visual Studio .NET 2003 ASP.NET 2.0 →Visual Studio 2005/ Visual Studio 2008
유연성 : 웹사이트에의 개발 및 실행 시 발생될 수 있는 모든 문제에 대한 대처기능 제공되어있다.
언어독립적 협업 : 언어가 무엇이든 상관없는 것이 특징이다. 일부는 VB로 일부는 C#으로 구현하여 하나의 웹사이트로 동작시킬 수 있다.
개발의 단순성 : 인터페이스를 서버콘트롤로 제공, 도구상자이용
사이트 관리의 용이성 Machine.config / Web.config 등으로 사이트를 쉽게 관리할 수 있다.
뛰어난 확장성 : 서버콘트롤을 상속받아 자신의 콘트롤을 만들어 서버콘트롤처럼 사용가능
보안기능 인증(Authentication) / 권한 부여(Authorization) 를 쉽게할 수 있도록 도와준다. 이 역시 web.config를 사용하는 경우도 있다.
ASP.NET 구현환경
ASP.NET 1.x에서는 개발자들이 자신의 PC에 IIS 탑재가 가능한 Windows 또는 서버 급 Windows를 설치했다. VS 2005에서는ASP.NET Development Server라는 내장 웹 서버를 제공하기 때문에 개발 PC의 Windows에 반드시 IIS가 탑재되어 있지 않아도 된다.
가용구역이란? 한 Region 내에 있는 서버들의 구역이라고 볼 수 있는데 한 Region 에 있는 서버들끼리는 전용 회선으로 연결되어 있어 일반 연결 보다
데이터 전송이 빠른 구역을 말한다, 그렇지만 다른 가용 구역끼리의 연결은 전용회선으로는 연결되어 있지 않아 일반 인터넷으로 데이터를 주고 받아야한다
RDS 는 Database를 생성 및 빽업 하는 AWS 서비스를 말하는데 기능 중 자동 빽업/복원을 설정 할 수 있다
빽업 기간이 길어질 수록 비용이 올라간다
DB 생성옵션 중 MultiAZ(다중 가용 구역) 를 yes 로 해놓을 경우 다른 가용구역(건물이 다른곳에 있는DB)과 연결 관계가 형성이 되면서
저장할 정보를 가용구역의 DB에도 자동으로 저장시킨다
이것의 장점은 한곳의 가용 구역이 먹통(고장)이 됐을때 다른 가용구역의 DB를 사용하면 된다는 장점이 있음
예약이나 특정 시점에서 수동으로 빽업 또한 가능
RDS 에서 도 스케일 Up 또 한 가능하다(특정 시간이나 즉시 옵션중에 선택하여 복사하는 형태로 진행)
=> 스케일 아웃도 가능한데 이럴때는 먼저
한대의 컴퓨터를 만들어 놓는다 이것을 Master 라 함
나머지 서버를 Slave n 로 만든다(Replica 들) (DB 인스턴스 생성)
그 후 Master 와 Slave 들간의 동기화를 한다
=> 이렇게 설정 된 이후
쓰기 작업을 할때는 Master 에 쓰기 작업이 들어가면 나머지 Slave 들에서 최근 쓰여진 정보를 읽어 동기화를 한다
읽기 작업을 할때는 각 Slave 를 대상으로만 읽도록 처리하여 부하를 줄인다
[이때 master 에 과부하가 일어 날 수 있다]
이때 이런 기술은 RDS 가 알아서 해주지 않는데 이를 해결 하기 위한 방법 중 sharding 이라는 기술로 슬레이브 모두가 가져가는 것이 아니고 예를 들어 인덱스로 나누어서 데이터가 쓰여질 슬레이브에 대한 인덱스를 계산해 관련 슬레이스에서만 쓰기가 일어나도록 할 수 있다
Amazon Relational Database Service(RDS)를 사용하면 클라우드에서 관계형 데이터베이스를 더욱 간편하게 설정, 운영 및 확장할 수 있습니다. 하드웨어 프로비저닝, 데이터베이스 설정, 패치 및 백업과 같은 시간 소모적인 관리 작업을 자동화하면서 비용 효율적이고 크기 조정 가능한 용량을 제공합니다. 애플리케이션에 집중하여 애플리케이션에 필요한 빠른 성능, 고가용성, 보안 및 호환성을 제공할 수 있도록 지원합니다.
Amazon RDS의 자동 백업 기능은 기본적으로 활성화되어 있으며, 이를 통해 데이터베이스 인스턴스를 특정 시점으로 복구할 수 있습니다. Amazon RDS는 데이터베이스와 트랜잭션 로그를 백업하고 이 둘을 모두 사용자가 지정한 보존 기간 동안 저장합니다. 이를 통해 데이터베이스를 보존 기간 중 어느 시점(초 단위)으로나 복원할 수 있습니다(최근 5분 전까지 가능). 자동 백업 보존 기간은 최대 35일로 구성할 수 있습니다.
한 서버로 트래픽이 몰리게 되면 한 서버에 부하가 커짐으로 여러 인스턴스를 만들어 놓고 각 서버로 트래픽을 분산하는 처리를 할 수 있는데
이때 분산해주는 서버를 ELB(Elastic Load Balancer)라 한다
ELB 를 사용하게 되면 사용자들이 처음 만나는 서버가 기존 서버가 아닌 ELB를 처음 만나 미리 분산해 놓은 서버중 한곳으로 가게된다
ELB는 오토스케일링과 같이 접목 될 수 있는 기술이라 볼 수 있겠다
ELB : Elastic Load Balancing은 들어오는 애플리케이션 트래픽을 Amazon EC2 인스턴스, 컨테이너, IP 주소와 같은
여러 대상에 자동으로 분산시킵니다.
Elastic Load Balancing은 단일 가용 영역 또는 여러 가용 영역에서 다양한 애플리케이션 부하를 처리할 수 있습니다.
Elastic Load Balancing이 제공하는 세 가지 로드 밸런서는 모두 애플리케이션의 내결함성에 필요한 고가용성, 자동 확장/축소, 강력한 보안을 갖추고 있습니다.
AWS 에서 제공하는 제품들은 다음과 같은것들이 있음
Application Load Balancer
Application Load Balancer는 HTTP 및 HTTPS 트래픽의 로드 밸런싱에 가장 적합하며, 마이크로서비스와 컨테이너 등 최신 애플리케이션 아키텍처 전달을 위한 고급 요청 라우팅 기능을 제공합니다. 개별 요청 수준(레이어 7)에서 작동하는 Application Load Balancer는 요청의 콘텐츠를 기반으로 Amazon Virtual Private Cloud(Amazon VPC) 내의 대상으로 트래픽을 라우팅합니다.
Network Load Balancer
Network Load Balancer는 극한의 성능이 요구되는 TCP 트래픽의 로드 밸런싱에 가장 적합합니다. 연결 수준(레이어 4)에서 작동하는 Network Load Balancer는 Amazon Virtual Private Cloud(Amazon VPC) 내의 대상으로 트래픽을 라우팅하며, 초당 수백만 개의 요청을 처리하면서 극히 낮은 지연 시간을 유지할 수 있습니다. Network Load Balancer는 갑작스러운 일시적 트래픽 패턴 처리에도 최적화되어 있습니다.
Classic Load Balancer
Classic Load Balancer는 여러 Amazon EC2 인스턴스에서 기본적인 로드 밸런싱을 제공하며, 요청 수준 및 연결 수준에서 작동합니다. Classic Load Balancer는 EC2-Classic 네트워크 내에 구축된 애플리케이션용입니다.
장점
고가용성
Elastic Load Balancing은 들어오는 트래픽을 여러 가용 영역에 있는 여러 대상(Amazon EC2 인스턴스, 컨테이너, IP 주소)에 자동으로 분산시키고 정상 상태인 대상만 트래픽을 수신하도록 합니다. Elastic Load Balancing은 리전에 걸친 로드 밸런싱을 통해 서로 다른 가용 영역에 있는 정상 상태의 대상으로 트래픽을 라우팅할 수도 있습니다.
탄력성
Elastic Load Balancing은 네트워크 트래픽 패턴의 빠른 변화에 대처할 수 있습니다. 또한 Auto Scaling과의 완벽한 통합을 통해 수동 개입의 필요성 없이 다양한 수준의 애플리케이션 부하를 충족하기에 충분한 애플리케이션 용량을 확보합니다.
Auto Scaling 그룹의 EC2 인스턴스에는 다른 EC2 인스턴스와는 다른 경로, 즉 수명 주기가 있습니다. 수명 주기는 Auto Scaling 그룹이 인스턴스를 시작하고 서비스에 들어갈 때 시작됩니다. 수명 주기는 인스턴스를 종료하거나 Auto Scaling 그룹이 인스턴스를 서비스에서 제외시키고 이를 종료할 때 끝납니다.
참고
인스턴스가 시작되는 즉시 인스턴스에 대한 요금이 청구되며, 아직 서비스되지 않는 시간도 포함됩니다.
다음 그림에서는 Auto Scaling 수명 주기에서 인스턴스 상태 간 전환을 보여 줍니다.
보류(Pending)
Auto Scaling에서 확장 이벤트에 응답하면 하나 이상의 인스턴스를 시작합니다. 이러한 인스턴스는 Pending 상태에서 시작됩니다.
확장(Scale Out)
다음 확장 이벤트는 Auto Scaling 그룹에 EC2 인스턴스를 시작하고 이를 그룹에 연결하라고 지시합니다.
지정된 수요 증가에 따라 그룹의 크기를 자동으로 늘리는 조정 정책을 만듭니다. 자세한 내용은 동적 조정 단원을 참조하십시오.
특정 시간에 그룹의 크기를 늘리도록 조정을 일정 기반으로 설정합니다. 자세한 내용은 예약된 조정 단원을 참조하십시오.
확장 이벤트가 발생하면 Auto Scaling 그룹이 할당된 시작 구성을 사용하여 필요한 수의 EC2 인스턴스를 시작합니다. 이러한 인스턴스는 Pending 상태에서 시작됩니다. Auto Scaling 그룹에 수명 주기 후크를 추가하면 여기에서 사용자 지정 작업을 수행할 수 있습니다. 자세한 내용은 수명 주기 후크 단원을 참조하십시오.
각 인스턴스가 완전히 구성되고 Amazon EC2 상태 확인을 통과하면, Auto Scaling 그룹에 연결되고 InService 상태에 들어갑니다. 이 인스턴스는 원하는 Auto Scaling 그룹 용량에서 감산됩니다.
서비스 상태의 인스턴스(Instances In Service)
인스턴스는 다음 중 하나가 발생할 때까지 InService(서비스중) 상태로 유지됩니다.
축소 이벤트가 발생하면 Auto Scaling은 Auto Scaling 그룹의 크기를 줄이기 위해 이 인스턴스를 종료합니다. 자세한 내용은 축소 시 Auto Scaling 인스턴스 종료 제어단원을 참조하십시오.
인스턴스를 Standby 상태로 설정하는 경우 자세한 내용은 대기 모드 시작 및 종료 단원을 참조하십시오.
Auto Scaling 그룹에서 인스턴스를 분리합니다. 자세한 내용은 인스턴스 분리 단원을 참조하십시오.
인스턴스가 필요한 수의 상태 확인에 실패한 경우, Auto Scaling 그룹에서 제거, 종료 및 교체됩니다. 자세한 내용은 Auto Scaling 인스턴스 상태 확인 단원을 참조하십시오.
축소(Scale In)
생성한 확장 이벤트 각각에 대해 축소 이벤트를 생성하는 것이 중요합니다. 이렇게 하면 애플리케이션에 할당된 리소스와 그러한 리소스의 수요를 가능한 한 가깝게 일치시킬 수 있습니다.
다음 축소 이벤트는 Auto Scaling 그룹이 그룹에서 EC2 인스턴스를 분리하고 이를 종료하라고 지시합니다.
그룹의 크기를 수동으로 줄입니다.
지정된 수요 감소에 따라 그룹의 크기를 자동으로 줄이는 조정 정책을 만듭니다.
특정 시간에 그룹의 크기를 줄이도록 조정을 일정 기반으로 설정합니다.
축소 이벤트가 발생하면 Auto Scaling 그룹에서 하나 이상의 인스턴스를 분리합니다. Auto Scaling 그룹이 종료 정책을 사용하여 종료할 인스턴스를 결정합니다. Auto Scaling 그룹에서 분리되어 종료 중인 인스턴스는 Terminating 상태로 들어가며, 다시 서비스 상태로 돌아갈 수 없습니다. Auto Scaling 그룹에 수명 주기 후크를 추가하면 여기에서 사용자 지정 작업을 수행할 수 있습니다. 마지막으로 인스턴스가 완전히 종료되고 Terminated 상태로 들어갑니다.
인스턴스 연결(Attach an Instance)
Auto Scaling 그룹에 특정 기준을 충족하는 실행 중인 EC2 인스턴스를 연결할 수 있습니다. 인스턴스가 연결되면 Auto Scaling 그룹의 일부로 관리됩니다.
인스턴스를 시작하거나 종료할 때 사용자 지정 작업을 수행할 수 있도록 Auto Scaling 그룹에 수명 주기 후크를 추가할 수 있습니다.
Auto Scaling에서 확장 이벤트에 응답하면 하나 이상의 인스턴스를 시작합니다. 이러한 인스턴스는 Pending 상태에서 시작됩니다. Auto Scaling 그룹에 autoscaling:EC2_INSTANCE_LAUNCHING 수명 주기 후크를 추가한 경우, 인스턴스가 Pending 상태에서 Pending:Wait 상태로 이동합니다. 수명 주기 작업을 완료하면 인스턴스가 Pending:Proceed 상태로 들어갑니다. 인스턴스가 완전히 구성되면 Auto Scaling 그룹에 연결되고 InService 상태로 들어갑니다.
Auto Scaling에서 축소 이벤트에 응답하면 하나 이상의 인스턴스를 종료합니다. Auto Scaling 그룹에서 이러한 인스턴스가 분리되고 Terminating 상태로 들어갑니다. Auto Scaling 그룹에 autoscaling:EC2_INSTANCE_TERMINATING 수명 주기 후크를 추가한 경우, 인스턴스가 Terminating 상태에서 Terminating:Wait 상태로 이동합니다. 수명 주기 작업을 완료하면 인스턴스가 Terminating:Proceed 상태로 들어갑니다. 인스턴스가 완전히 종료되면 Terminated 상태로 들어갑니다.
AMI : 이미지화 시킨다는 말은 현재 컴퓨터(윈도우일경우)의 OS/소프트웨어들 포함 복사본을 만들어 이것을 파일 형태로 만들어 놓는데 이 파일을 이미라 부름(.iso 파일 같은 느낌)으로 AWS 에서는 이 이미지들을 유니티의 에셋스토어에서 처럼 사람들이 만들어 놓고 이미지들에 대한 공유/판매가 이뤄진다
인스턴스 및 AMI
Amazon 머신 이미지(AMI)은 필요한 소프트웨어가 이미 구성되어 있는 템플릿입니다(예: 운영 체제, 애플리케이션 서버, 애플리케이션). AMI에서 인스턴스를 바로 시작하실 수 있는데, 이 인스턴스는 AMI의 사본으로, 클라우드에서 실행되는 가상 서버입니다. 다음 그림과 같이, 한 AMI로 여러 인스턴스를 실행할 수 있습니다.
중지하거나 종료할 때까지 또는 실패하기 전까지 인스턴스는 계속 실행됩니다. 인스턴스가 실패하면 AMI에서 새로 실행할 수 있습니다.
AMI
Amazon Web Services(AWS)에서는 자주 사용되는 소프트웨어 구성을 포함하는 다양한 Amazon 머신 이미지(AMI)가 공개 게시하고 있습니다. 그 뿐 아니라 AWS 개발자 커뮤니티 회원들이 올린 자체 구성 AMI도 게시되어 있습니다. 또한 얼마든지 사용자 정의된 AMI을 생성할 수 있어서, 고객님께서 필요하신 기능을 모두 갖춘 새로운 인스턴스를 쉽고 빠르게 시작할 수 있습니다. 예를 들어 고객님의 애플리케이션이 웹사이트나 웹 서비스인 경우, 웹 서버와 관련 고정 콘텐츠, 그리고 동적 페이지에 사용할 코드가 포함된 AMI를 정의해 만드실 수 있습니다. 그래서, 이 AMI에서 인스턴스가 시작이 되면, 고객님의 웹 서버가 자동으로 시작되고 애플리케이션은 바로 Request를 처리할 수 있습니다.
모든 인스턴스는 Amazon EBS 기반(AMI의 인스턴스가 실행되는 루트 디바이스가 Amazon EBS 볼륨인 경우) 또는 인스턴스 스토어 기반(AMI의 인스턴스가 실행되는 루트 디바이스가 Amazon S3에 저장된 템플릿에서 생성된 인스턴스 스토어 볼륨인 경우) 중 하나에 해당됩니다.
AMI에대한 설명을 보시면, 그 인스턴스의 루트디바이스가 ebs 인지 instance store인지 알수 있습니다. 각 AMI 유형별로 수행할 수 있는 작업이나 기능이 달라지기 때문에 이 차이점을 아는 것이 중요합니다. 해당 차이점에 대한 자세한 내용은 루트 디바이스 스토리지 단원을 참조하십시오.
인스턴스 : 컴퓨터 한대를 AWS 에서 만든것이라는 개념으로 하드웨어 사양등을 선택하여 인스턴스를 구성할 수 있음
인스턴스
동일한 AMI에서 다른 유형의 인스턴스를 실행할 수 있습니다. 인스턴스 유형에 따라 인스턴스에 사용되는 호스트 컴퓨터의 하드웨어가 결정됩니다. 각 인스턴스 유형은 서로 다른 컴퓨팅 및 메모리 기능을 제공합니다. 인스턴스에서 실행하려는 애플리케이션 또는 소프트웨어에 필요한 메모리 양과 컴퓨팅 파워를 기준으로 인스턴스 유형을 선택하십시오. Amazon EC2 인스턴스 유형별 하드웨어 사양에 대한 자세한 내용은 Amazon EC2 인스턴스 유형 단원을 참조하십시오.
일단 인스턴스가 시작되면, 인스턴스는 다른 컴퓨터와 다를 것이 없고, 어느 컴퓨터와 동일한 방식으로 다루시면 됩니다. 인스턴스의 완벽한 통제가 가능하며, 루트 권한이 필요한 명령어는 sudo를 사용해 실행할 수 있습니다.
AWS 계정당 동시 수행할 수 있는 인스턴스 수는 제한됩니다. 해당 제한 및 추가 요청 방법에 대한 자세한 내용은 Amazon EC2의 실행 인스턴스 한도(종합 FAQ의 Amazon EC2) 단원을 참조하십시오.
인스턴스 스토리지
인스턴스의 루트 디바이스에는 인스턴스 부팅에 사용되는 이미지가 포함되어 있습니다. 자세한 내용은 Amazon EC2 루트 디바이스 볼륨 단원을 참조하십시오.
인스턴스에는 로컬 스토리지 볼륨이 포함될 수 있는데 이것을 인스턴스 스토어 볼륨이라고 하며, 인스턴스 실행 시 블록 디바이스 매핑으로 구성할 수 있습니다. 자세한 내용은 블록 디바이스 매핑 단원을 참조하십시오. 고객님의 인스턴스용 볼륨 추가와 매핑이 완료되면, 마운트하여 사용할 수 있습니다. 인스턴스 오류가 발생하거나 중지 혹은 종료된 경우, 해당 볼륨에 저장된 데이터는 손실되기 때문에 이런 볼륨은 임시 데이터 작성에 사용하는 것이 가장 좋습니다. 중요한 데이터는 여러 인스턴스를 연결하는 복제 방법을 사용하여 데이터를 보호하거나 지속적인 보관이 필요한 데이터를 Amazon S3 또는 Amazon EBS 볼륨에 저장하는 방법이 있습니다. 자세한 내용은 스토리지 단원을 참조하십시오.
보안 구현 모범 사례
AWS Identity and Access Management(IAM)을 사용하여 고객님의 인스턴스를 비롯한 AWS 리소스의 액세스를 제어할 수 있습니다. AWS 계정으로 IAM 사용자와 그룹을 생성하고 사용자나 그룹별로 보안 자격 증명을 할당하고 AWS 서비스 및 리소스에 대한 액세스 권한을 부여할 수 있습니다. 자세한 내용은 Amazon EC2 리소스에 대한 액세스 제어을 참조하십시오.
신뢰할 수 있는 호스트나 네트워크만 인스턴스 포트에 액세스할 수 있도록 제한할 수 있습니다. 예를 들어 22번 포트의 유입 트래픽을 제한하면 SSH 액세스 제한이 가능합니다. 자세한 내용은 Linux 인스턴스에 대한 Amazon EC2 보안 그룹 단원을 참조하십시오.
보안 그룹의 규칙을 정기적으로 검토하고 최소 권한 부여—라는 개념을 항상 적용하고 필요한 경우 필요한 권한만 허가하십시오. 보안 요구 사항이 다른 각 인스턴트를 처리하기 위해 서로 다른 보안 그룹을 생성할 수도 있습니다. 외부 로그인을 허용하는 접속 보안 그룹을 생성하고 여기에 해당되지 않는 나머지 인스턴스는 외부 로그인을 허용하지 않는 그룹으로 할당하는 것도 생각해 볼 수 있습니다.
AMI 실행 인스턴스는 비밀번호를 사용한 로그인을 비활성화합니다. 비밀번호는 유출이나 해킹이 가능해 보안 위험이 됩니다. 자세한 내용은 루트 사용자의 암호 방식 원격 로그인 비활성화 단원을 참조하십시오. 안전한 AMI 공유에 대한 자세한 내용은 공유 AMI 단원을 참조하십시오.
인스턴스 중지, 시작 및 종료
인스턴스 중지
인스턴스를 중단하면 정상적인 실행종료 과정이 이루어지고 stopped 상태가 됩니다. 인스턴스의 모든 Amazon EBS 볼륨이 연결된 상태로 유지되므로 나중에 언제든지 다시 시작할 수 있습니다.
인스턴스가 중지됨 상태에 있는 동안에는 추가 인스턴스 사용량에 대한 요금이 부과되지 않습니다. 중지됨 상태에서 실행 중 상태로 전환할 때마다 최소 1분의 요금이 부과되며. 인스턴스가 중지된 상태에서 인스턴스 유형을 변경하면, 다음에 인스턴스가 시작된 후 신규 인스턴스 유형에 대한 요금이 부과됩니다. 모든 연결 Amazon EBS 루트 디바이스 사용을 비롯한 인스턴스 사용에 관련된 비용은 일반 Amazon EBS 요금이 적용됩니다.
인스턴스가 중지 상태인 경우 인스턴스에 Amazon EBS 볼륨을 연결하거나 분리할 수 있습니다. 또한 인스턴스로부터 AMI를 만들수도 있으며, 커널, 램 디스크, 인스턴스 유형을 변경할 수 있습니다.
인스턴스 종료
인스턴스가 종료될 때 인스턴스는 일반 종료를 수행합니다. 루트 디바이스 볼륨은 기본적으로 삭제되지만 모든 연결된 Amazon EBS 볼륨은 기본적으로 유지됩니다. 이는 각 볼륨의 deleteOnTermination속성 설정에 따라 결정됩니다. 인스턴트 자체도 삭제되므로 나중에 다시 시작할 수 없게 됩니다.
인스턴스 종료를 비활성화하면 실수로 인스턴스를 종료하는 일을 방지할 수 있습니다. 이 경우에는 해당 인스턴스에 관련된 disableApiTermination 속성을 true로 설정했는지 확인하십시오. Linux의 shutdown -h 및 Windows의 shutdown 같은 인스턴스 실행종료 동작을 제어하려면 instanceInitiatedShutdownBehavior 인스턴스 속성을 stop이나 terminate로 적절히 설정하십시오. 기본 설정은 인스턴스 실행종료 시 Amazon EBS 볼륨을 루트 디바이스로 사용하는 인스턴스는 stop 상태, 인스턴스 스토어를 루트 디바이스로 사용하는 인스턴스는 항상 종료 상태로 변경됩니다.
Amazon EC2는 웹 서비스 인터페이스를 사용해 다양한 운영 체제로 인스턴스를 시작하고, 이를 사용자 정의 애플리케이션 환경으로 로드하며, 네트워크의 액세스 권한을 관리하고, 원하는 수의 시스템을 사용해 이미지를 실행할 수 있는 진정한 가상 컴퓨팅 환경을 제공합니다.
Amazon EC2를 사용하려면 다음을 수행하면 됩니다.
즉시 가져와서 실행할 수 있도록 미리 구성된 템플릿 기반의 Amazon 머신 이미지(AMI)를 선택합니다. 또는 애플리케이션, 라이브러리, 데이터 및 관련 구성 설정을 포함하는 AMI를 만듭니다.
Amazon EC2 인스턴스에 대한 보안 및 네트워크 액세스를 구성합니다.
원하는 인스턴스 유형을 선택한 다음 웹 서비스 API 또는 제공된 다양한 관리 도구를 사용하여 AMI 인스턴스를 필요한 수만큼 시작, 종료, 모니터링합니다.
여러 위치에서 실행할지, 고정 IP 끝점을 사용할지, 인스턴스에 영구 블록 스토리지를 추가할지 여부를 결정합니다.
인스턴스 시간 또는 데이터 전송과 같은 실제로 소비한 리소스에 대해서만 비용을 지불합니다.
대규모 부동 소수점 처리 능력이 필요한 고객은 최대 8개의 NVIDIA Volta GV100 GPU가 탑재된 AWS의 차세대 범용 GPU 컴퓨팅 인스턴스인 Amazon EC2 P3 인스턴스의 이점을 활용할 수 있습니다. P3 인스턴스는 최대 1페타플롭스의 혼합 정밀도, 125테라플롭스의 단정밀도, 62테라플롭스의 배정밀도 부동 소수점 성능을 제공합니다. 초당 300GB의 2세대 NVLink interconnect는 빠른 속도와 짧은 지연 시간으로 GPU 대 GPU 통신을 지원합니다. 또한 P3 인스턴스는 사용자 지정 인텔 제온 E5(코드명 Broadwell) 프로세서를 기반으로 하는 최대 64개의 vCPU와 488GB의 DRM을 제공하며, Elastic Network Adapter(ENA)를 사용하여 초당 25GB의 전용 집계 네트워크 대역폭을 제공합니다. P3 인스턴스는 기계 학습, 고성능 컴퓨팅, 전산 유체 역학, 컴퓨팅 금융, 내진 해석, 분자 모델링, 유전체학 및 렌더링 워크로드에 매우 적합합니다.
뛰어난 그래픽 성능이 필요한 고객은 GPU 그래픽 인스턴스의 이점을 활용할 수 있습니다. 현재 세대 GPU 그래픽 인스턴스인 G3 인스턴스는 NVIDIA Tesla M60 GPU에 대한 액세스를 제공하며, GPU당 최대 2,048개의 병렬 처리 코어, 8GiB의 GPU 메모리, 최대 10개의 H.265(HEVC) 1080p30 스트림 및 최대 18개의 H.264 1080p30 스트림을 지원하는 하드웨어 인코더를 지원합니다. 최신 드라이버 릴리스를 설치하면 이러한 GPU가 OpenGL, DirectX, CUDA, OpenCL 및 Capture SDK(GRID SDK라고도 함)에 대한 지원을 제공합니다. GPU 그래픽 인스턴스는 3D 시각화, 그래픽 집약적 원격 워크스테이션, 3D 렌더링, 애플리케이션 스트리밍, 비디오 인코딩 및 기타 서버 측 그래픽 워크로드에 적합합니다.
지연 시간은 최소화하면서 데이터에 대한 높은 랜덤 I/O 액세스가 필요한 고객에게는 높은 I/O 인스턴스가 도움이 될 수 있습니다. 높은 I/O 인스턴스는 고객에게 3백만 이상의 임의 I/O 속도를 제공할 수 있는 Amazon EC2 인스턴스 유형입니다. 높은 I/O I3 인스턴스는 NVMe(Non-Volatile Memory Express) SSD를 기반으로 하며, 매우 높은 성능의 NoSQL 데이터베이스, 트랜잭션 시스템 및 Elasticsearch 워크로드를 실행하는 고객에게 매우 적합합니다. 또한, 높은 I/O 인스턴스는 최대 16GB/초의 순차 디스크 처리량을 제공하므로 분석 워크로드에도 적합합니다.
인스턴스당 매우 높은 스토리지 밀도와 MPP(대량 병렬 처리: Massively Parallel Processing) 데이터 웨어하우스, MapReduce 및 하둡 분산 컴퓨팅, 로그 및 데이터 프로세싱과 같은 데이터 집약적인 애플리케이션을 위한 높은 순차적 I/O를 필요로 하는 고객은 고밀도 스토리지 인스턴스를 활용하여 도움을 받을 수 있습니다. Dense Storage 인스턴스는 Amazon EC2 인스턴스 유형으로, 최대 3.9GB/s의 순차 I/O 처리량 및 24개 하드 디스크 드라이브 전체에 최대 48TB의 인스턴스 스토리지 용량을 제공합니다. 또한 ENA 기반 네트워킹으로 vCPU당 스토리지 및 메모리를 줄여 배치 그룹 내에서 최대 25Gbps의 네트워크 대역폭을 제공합니다. 고밀도 스토리지 인스턴스에 대한 자세한 내용은 Amazon EC2 인스턴스 유형을 참조하십시오.
Amazon EBS는 Amazon EC2 인스턴스에서 사용할 수 있는 일관되고, 가용성이 뛰어나며, 지연 시간이 짧은 영구 블록 스토리지 볼륨을 제공합니다. 각 Amazon EBS 볼륨은 가용 영역 내에 자동으로 복제되어 구성요소 장애로부터 보호하고, 뛰어난 가용성 및 내구성을 제공합니다. 용량, 성능 및 비용에 따라 워크로드를 조정해야 하는 애플리케이션 관리자를 위해 설계되었습니다.
Amazon EFS는 공유 액세스를 위한 간단하고 확장 가능한 완전관리형 영구 클라우드 파일 스토리지를 제공합니다. 여러 가용 영역에 걸쳐 뛰어난 가용성과 내구성을 제공하도록 설계된 Amazon EFS는 표준 파일 시스템 액세스 의미 체계를 지원하는 파일 시스템 인터페이스를 제공하고, 용량을 자동으로 증가 및 축소하며, 애플리케이션 관리자에게 페타바이트 규모에서 높은 처리량과 일관되게 짧은 지연 시간을 제공합니다.
예를 들어, 특정 시점에 시간당 비용이 0.085 USD인 스몰 유형 인스턴스 20개를 시작한다고 가정해 보겠습니다. 인스턴스는 즉시 부팅을 시작하지만 모든 인스턴스가 항상 동시에 시작되는 것은 아닙니다. 각 인스턴스는 실제 시작 시간을 저장합니다. 그 후에 각 인스턴스가 시작된 시간을 기준으로 매시간이 시작될 때 실행 시간(0.085 USD/시간)에 대한 요금이 부과됩니다. 각 인스턴스는 사용자가 TerminateInstances API 호출(또는 이에 상응하는 도구)을 사용해 인스턴스를 종료하거나, 인스턴스가 저절로 종료(예: UNIX “shutdown” 명령)되거나, 소프트웨어 또는 하드웨어 오류로 인해 호스트가 종료될 때까지 실행됩니다. 인스턴스를 1시간 미만으로 사용한 경우에도 1시간을 사용한 것으로 청구됩니다.
Amazon EC2는 인스턴스를 여러 위치에 배치할 수 있는 기능을 제공합니다. Amazon EC2 위치는 리전과 가용 영역으로 구성됩니다. 가용 영역은 다른 가용 영역에 오류가 발생할 경우 오류 지점으로부터 분리되도록 설계된 별개의 위치로, 동일 지역의 다른 가용 영역에 저렴하고 지연 시간이 낮은 네트워크 연결을 제공합니다. 별도의 가용 영역에서 인스턴스를 실행함으로써 단일 위치에서 오류가 발생할 경우 애플리케이션을 보호할 수 있습니다. 리전은 하나 이상의 가용 영역으로 구성되고, 지리적으로 분산되어 있으며, 분리된 지리적 영역 또는 국가에 위치합니다. Amazon EC2 서비스 수준 계약은 각 Amazon EC2 리전에 99.95%의 가용성을 보장합니다. AWS 제품 및 서비스의 리전별 가용성은 리전별 제품 및 서비스를 참조하십시오.
엘라스틱 IP 주소는 동적 클라우드 컴퓨팅에 적합하게 설계된 고정 IP 주소입니다. 엘라스틱 IP 주소는 특정 인스턴스가 아닌 사용자의 계정과 연결되며 사용자는 명시적으로 해제할 때까지 해당 주소를 제어합니다. 그러나 기존의 고정 IP 주소와는 달리 엘라스틱 IP 주소를 사용하면 공인 IP 주소를 계정의 인스턴스에 프로그래밍 방식으로 다시 매핑하여 인스턴스 또는 가용 영역 장애를 마스킹할 수 있습니다. Amazon EC2를 사용하면 데이터 기술자가 호스트를 재구성하거나 교체할 때까지 기다리거나 DNS 정보가 모든 고객에게 적용될 때까지 기다리지 않고 엘라스틱 IP 주소를 교체 인스턴스에 빠르게 다시 매핑하여 인스턴스 또는 소프트웨어 문제를 해결할 수 있습니다. 또한 이 양식을 작성하여 엘라스틱 IP 주소의 역방향 DNS 레코드를 구성할 수도 있습니다.
Amazon EC2 Auto Scaling을 사용하면 정의한 조건에 따라 Amazon EC2 용량을 자동으로 확장하거나 축소할 수 있습니다. EC2 Auto Scaling은 용량에 대한 수요가 급증할 경우에는 사용 중인 Amazon EC2 인스턴스 수를 자동으로 늘려 성능을 유지할 수 있게 하고, 수요가 감소할 경우에는 인스턴스 수를 자동으로 줄여 비용을 최소화할 수 있게 합니다. EC2 Auto Scaling은 사용량이 시간, 일 또는 주 단위로 바뀌는 애플리케이션에 특히 적합하고 EC2 Auto Scaling은 Amazon CloudWatch를 통해 활성화되며 Amazon CloudWatch 요금 외에 추가 비용이 발생하지 않습니다. 자세한 내용은 Amazon EC2 Auto Scaling을 참조하십시오. EC2뿐만 아니라 다른 서비스의 크기도 조정하려면 AWS Auto Scaling을 사용하면 됩니다.
긴밀하게 연결된 병렬 처리와 같은 복잡한 연산 워크로드 또는 네트워크 성능에 민감한 애플리케이션을 사용하는 고객은 Amazon EC2의 탄력성, 유연성 및 비용 이점을 활용하는 동시에 사용자 구성 인프라가 제공하는 것과 동일한 뛰어난 컴퓨팅 및 네트워크 성능을 실현할 수 있습니다. 클러스터 컴퓨팅, 클러스터 GPU 및 고용량 메모리 클러스터 인스턴스는 고성능 네트워크 기능을 제공하도록 특별히 설계되었으며, 프로그래밍 방식을 통해 클러스터에 실행할 수 있으므로, 긴밀하게 연결된 노드 간 통신에 필요한 지연 시간이 짧은 네트워크 성능을 애플리케이션에 제공할 수 있습니다. 클러스터 인스턴스는 처리 속도를 크게 향상하므로 네트워크 집약적 작업을 수행해야 하는 고객 애플리케이션에도 적합합니다. Amazon EC2 및 다른 AWS 서비스를 HPC 애플리케이션에 사용할 수 있는 방법에 대해 자세히 알아보십시오.
향상된 네트워킹을 사용하면 PPS(Packet Per Second) 성능이 크게 높아지고, 네트워크 지터 및 지연 시간이 낮아집니다. 이 기능은 일반 구현에 비해 높은 I/O 성능 및 낮은 CPU 사용률을 제공하는 새로운 네트워크 가상화 스택을 사용합니다. 향상된 네트워킹을 이용하려면 VPC에서 HVM AMI를 시작하고 적절한 드라이버를 설치해야 합니다. EC2 인스턴스에서 향상된 네트워킹 기능을 활성화하는 방법에 대해 알아보려면 지원 Linux 인스턴스에서 향상된 네트워킹 기능 사용 및 지원 Windows 인스턴스에서 향상된 네트워킹 기능 사용 자습서를 참조하십시오. 이 기능의 인스턴스별 가용성이나 자세한 내용을 알아보려면 향상된 네트워킹 FAQ 섹션을 참조하십시오.
고객은 Amazon Virtual Private Cloud(VPC) 또는 AWS Direct Connect를 통해 Amazon EC2 API에 비공개로 액세스할 수 있으며, 퍼블릭 IP를 사용하거나 트래픽이 인터넷을 통과할 필요가 없습니다. AWS PrivateLink는 고객이 AWS 네트워크 내에 모든 네트워크 트래픽을 유지하면서 가용성과 확장성이 뛰어난 방식으로 Amazon 서비스에 액세스할 수 있도록 특별히 개발된 기술입니다. AWS PrivateLink로 Amazon EC2를 사용하려면 VPC에 EC2용 엔드포인트를 생성해야 합니다. 이 엔드포인트로 향하는 모든 트래픽이 비공개로 EC2 서비스로 라우팅됩니다. AWS PrivateLink에 대해 자세히 알아보려면 PrivateLink 설명서를 참조하십시오.
Amazon Time Sync Service는 EC2 인스턴스를 포함하여 AWS 서비스에 매우 정확하고 안정적이며 가용성이 뛰어난 시간 소스를 제공합니다. VPC에서 실행 중인 모든 인스턴스는 범용적으로 연결 가능한 IP 주소에서 서비스를 액세스할 수 있습니다. 서비스는 AWS 리전에서 일련의 예비 위성 연결 및 원자 기준 시계를 사용하여 UTC(Coordinated Universal Time) 글로벌 표준을 준수하는 매우 정확하고 신뢰할 수 있는 현재 시간 판독값을 제공합니다. 서비스를 액세스하는 방법에 대한 지침은Linux및Windows사용자 설명서의 시간 설정 섹션을 참조합니다.
이 강좌는 안드로이드 단말기와 서버와의 자료 및 정보 교환을 하는 방법에 대한 것이므로 잘 배워두면 곧바로 실무에 적용할 수 있을 것입니다.
단말기와 웹서버와 통신 방식은 다음과 같이 크게 두 가지로 구분할 수 있습니다.
① HTTP 통신
② Socket 통신
HTTP와 Socket의 가장 큰 차이점은 접속(Connection)을 유지하는지의 여부입니다. 물론 파일 전송만을 전문으로 처리하는 FTP도 있지만 이것은 HTTP를 확장한 개념이므로 HTTP에 포함시키겠습니다.
1. HTTP 통신
HTTP 통신은 웹브라우저에 정보를 표시하는 것과 같이 클라이언트의 요청이 있을 때 서버가 해당 페이지에 대한 자료를 전송하고 곧바로 연결을 끊는 방식입니다. 현재 여러분이 제 블로그를 보고 있지만 맨 처음 이 페이지가 보여지는 순간만 서버와 연결되고 현재는 서버와 접속이 끊어진 상태입니다. 이 상태에서 F5 키를 눌러 새로고침을 하거나 다른 페이지로 이동하면 그때 다시 서버에 연결이 될 것입니다.
이렇게 하는 이유는 단 한가지. 서버의 부하를 줄여서 다른 접속을 원활하게 처리하기 위해서입니다. 여러분이 F5 키를 계속 누르거나 아예 F5 키에 연필을 꽂아서 클라이언트가 서버를 계속해서 물고 늘어지면 서버는 이 클라이언트의 연결을 유지하느라 다른 컴퓨터의 응답이 늦어질 것입니다. 이런 방식으로 여러 대의 PC가 서버를 붙잡고 늘어져서 서버가 다른 일을 하지 못하도록 하는 것을 DDOS 공격이라고 하죠...
2. Socket 통신
Socket 통신은 클라이언트가 서버와 접속이 되면 서버나 클라이언트에서 강제로 접속을 해제할 때까지는 계속해서 접속이 유지됩니다. 따라서 서버의 능력이 무한대가 아닌 이상 동시에 접속할 수 있는 클라이언트의 수가 제한이 될 수 밖에 없겠죠.
Socket 통신은 실시간으로 정보 교환이 필요하는 채팅이나 온라인 게임, 실시간 동영상 강좌 등에 사용됩니다. 따라서 이와 같은 경우가 아니라면 서버와의 통신은 HTTP를 사용하는 것이 시스템의 자원을 보다 효과적으로 사용할 수 있습니다.
3. 시스템의 구성
단말기가 서버에 접속하기 위해서는 서버에 단말기의 응답을 처리하는 별도의 프로그램이 있어야 합니다. 저는 이것을 서버 모듈이라고 부르겠습니다. 서버 모듈은 C, PHP, Java, ASP 등 다양한 언어로 작성될 수 있을 것지만, 제가 사용하는 서버가 아파치 웹서버를 사용하므로 PHP로 구성하기로 합니다. 서버와 통신하기 위한 시스템의 구성은 다음 그림과 같습니다.
기본적인 개념을 세웠으므로 다음 강좌에서는 단말기 모듈과 서버 모듈을 설계하는 과정에 대해 알아보기로 하고 이번 강좌는 간단히 마무리합니다.