현재의 내 컴퓨터 작업환경이 WindowsXP (서비스팩3), 비주얼스튜디오 2005 이므로, 이 환경을 기준으로 작성하였습니다. 혹 비주얼 스튜디오의 버전이나 윈도우를 업글하게 되면 해당 버전에 대해서도 새로 포스트 하도록 하겠습니다.
1. 설치전 준비사항
오우거를 설치하기 전에 먼저 컴퓨터에 DirectX SDK가 설치되어야 합니다.
DirectX SDK 최신버전인 June 2010 버전은 여기에서 다운 받을 수 있습니다.
http://www.microsoft.com/downloads/en/details.aspx?displaylang=en&FamilyID=3021d52b-514e-41d3-ad02-438a3ba730ba
그런데, 이 다운로드 페이지에 다음과 같은 내용이 있군요.
The June 2010 DirectX SDK includes support for Visual Studio 2010. The DirectX SDK will continue to support Visual Studio 2008 as well. However, Visual Studio 2005 will no longer be supported.
즉, June 2010 버전은 비주얼 스튜디오 2010을 지원하고 2008도 여전히 지원하지만, 비주얼 스튜디오 2005는 더이상 지원하지 않는다는 것입니다. 비주얼 스튜디오 2005를 사용하는 환경에서 DirectX June 2010을 링크하고 컴파일하려고 하면 에러가 발생할 것입니다. 깡패같은 놈들이 아닐 수 없습니다. 다이렉트 엑스 최신버전 사용하고 싶으면 새 컴파일러를 사라, 뭐 이런 소리이군요.
비주얼 스튜디오를 상위버전으로 새로 설치할 생각이 없고 계속해서 2005 버전을 사용할 계획이라면, 다음의 링크에서 제가 알고있는 DirectX의 2009년 마지막 릴리즈인 August 2009 버전을 받아서 설치하시면 되겠습니다.
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=b66e14b8-8505-4b17-bf80-edb2df5abad4&displaylang=en
만일, 컴퓨터에 이미 다른 버전의 DirectX 9.0c SDK가 설치되어 있고 이걸 최근의 버전으로 패치할 생각이 없다면, DirectX SDK 설치는 그냥 건너뛰어도 상관없겠습니다.
다음으로, 비주얼 스튜디오 2005를 사용하고 계시는 경우, 비주얼 스튜디오 2005 서비스팩1을 설치해야 합니다.
그 이유는 오우거 엔진의 비주얼 스튜디오 2005 버전의 소스가 서비스팩1 버전을 기준으로 작성되어 있기 때문에 서비스팩 없이 컴파일을 시도하면 여러가지 에러를 만나게 되고, 서비스팩을 설치하지 않으면 해결이 불가능하기 때문이지요.
비주얼 스튜디오 2005 서비스팩1은 여기에서 다운로드 받을 수 있습니다.
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=bb4a75ab-e2d4-4c96-b39d-37baf6b5b1dc
만일 사용중인 운영체제가 Windows Vista, Windows Server 2008, Windows7 이라면 다음의 서비스팩을 설치하는 것이 좋습니다.
http://www.microsoft.com/downloads/en/details.aspx?FamilyID=90E2942D-3AD1-4873-A2EE-4ACC0AACE5B6
비주얼 스튜디오 2005가 아닌 다른 컴파일러를 사용하고 있는 경우라면, 혹시 다른 요구사항이 있는지 확인하기 위해 오우거 홈페이지에 가서 인스톨 가이드를 읽어 보시길 바랍니다.
위에 제시한 다운로드 URL들은 2010년 9월 16일 현재 유효한 경로로써, 구버전 SDK나 서비스팩의 다운로드 경로를 마이크로소프트가 수시로 변경하기 때문에 향후 어느 시점에서 더이상 유효한 경로가 아닐 수도 있습니다. 이런 경우에는 마이크로소프트 다운로드 페이지에서 검색하여 새 경로를 찾거나, 운영체제 또는 컴파일러의 업그레이드를 추천합니다.
2. 오우거의 다운로드 및 설치
위의 과정을 모두 마쳤다면 이제 오우거 소스를 다운로드해야 겠지요.
오우거 1.7.1 버전의 자동압축 파일을 여기에서 다운로드할 수 있습니다.
http://www.ogre3d.org/download/source
다운로드 받은 파일을 실행하면 다음과 같이 압축을 해제할 경로를 묻습니다.
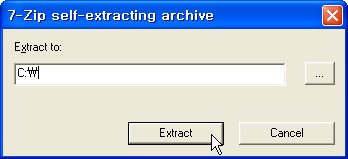
제 경우는 압축을 해제할 경로를 단순히 C드라이브로 지정했는데, 그 이유는 압축을 해제하면 지정된 경로에 ogre_src_v1-7-1 이라는 서브 폴더가 생성되고, 소스들이 그 폴더안에 존재하게 되기 때문입니다.
압축을 해제할 경로로 다른 폴더 이름을 지정해주게 되면 나중에 컴파일하고 나서 생성된 라이브러리들은 상당히 여러 단계 아래의 폴더에 존재하게되고, 나중에 응용프로그램(즉, 게임과 같이 오우거를 사용하는 프로그램)을 만들 때 비주얼 스튜디오에 오우거 라이브러리 경로를 지정해야 하는데, 이 경로 이름의 길이가 매우 길어질 것이기 때문입니다.
저는 개인적으로 긴 경로이름을 싫어하므로 이렇게 한 것인데, 머 임시 폴더를 지정해주고 압축을 해제한 후에 서브폴더들을 상위 경로로 옮기거나, 혹은 긴 경로를 그대로 사용하거나, 또는 오우거 컴파일을 완료한 후에 출력된 라이브러리들과 헤더들 만을 별도의 경로로 옮겨 사용해도 됩니다.
이건 각자의 취향에 따라 선택하면 되고 꼭 제가 한 그대로 하실 필요는 없습니다.
압축을 해제할 경로를 지정했다면, Extract를 클릭하여 압축 해제를 시작합니다.
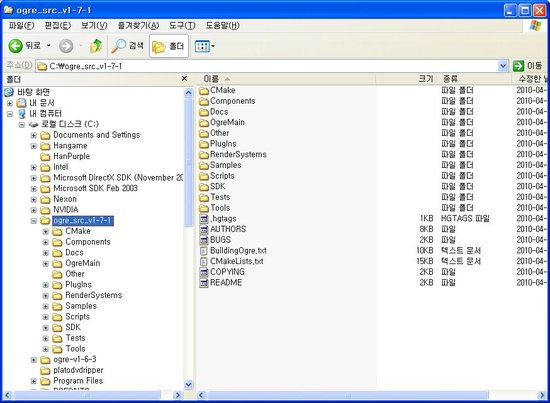
압축 해제가 완료된 후에 지정했던 경로에 가보면 위에 보시는 것과 같이 ogre_src_v1-7-1 이라는 폴더가 새로 생성된 것이 보입니다. 그 폴더 안에는 오우거 엔진, 데모들, 도구들의 소스와 도큐먼트들이 들어 있습니다.
BuildingOgre.txt 라는 텍스트 파일이 보이는 군요. 사실 이 파일에 설치와 관련된 모든 내용이 설명되어 있습니다. 단지 (영국식)영어로 되어 있다는 것이 단점이지요.
위에 압축 해제 이미지를 보시면 제 컴퓨터에 이미 오우거 1.6.3 버전이 설치되어 있는 것이 보이실 것입니다. 제 경우와 같이 이전 버전의 오우거가 이미 설치되어 있다고 하더라도 아무 상관없이 1.7.1 버전을 새로 설치하실 수 있습니다. 다만, 폴더 이름만 다른 이름을 사용하시면 되는 것이지요.
이제, Boost 라이브러리를 설치해야 합니다.
Boost는 오우거를 컴파일하기 위해 반드시 필요한 것은 아닙니다. 그러나 오우거의 지형(Terrain) 라이브러리의 페이징 기술에서 리소스의 백그라운드 로딩에 Boost 라이브러리를 사용할 경우 좀 더 빠른 성능을 보여주기 때문에 설치하는 것이 좋겠죠.
물론, 이 라이브러리가 없어도 동작합니다.
다음의 경로에서 Boost 라이브러리 인스톨러를 다운로드 할 수 있습니다.
이 포스트를 쓰는 현재 최신버전은 1.44이지만, 오우거 1.7.1은 1.42버전을 사용하여 작성되었으므로, 1.42 버전을 다운 받도록 합니다. (1.44 버전은 오우거를 컴파일할 때 에러가 발생합니다)
http://www.boostpro.com/download/
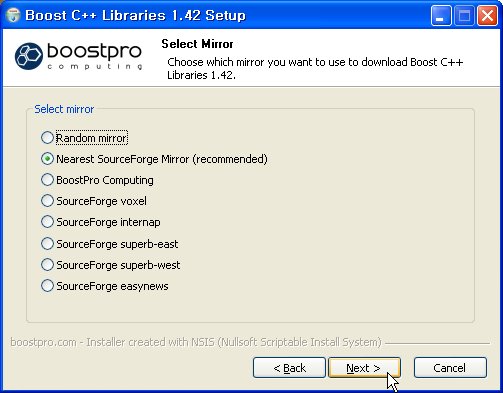
다운받은 인스톨러를 실행하면 위와 같이 Boost라이브러리를 어디에서 다운 받을 것인가를 묻습니다. 적당한 다운로드 서버를 지정해주고 Next를 클릭합니다.
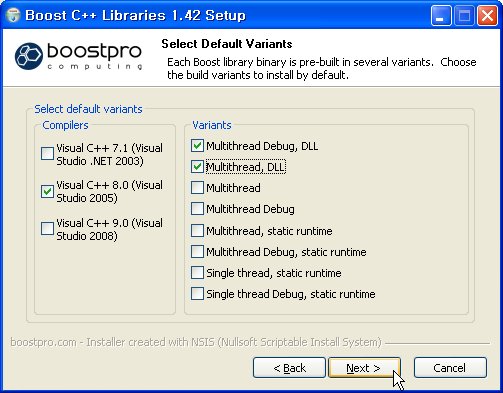
Boost 라이브러리는 몇 가지 형태로 미리 컴파일된 라이브러리인데 설치하길 원하는 형식을 선택하라는 창이 뜹니다.
좌측 컴파일러 항목에서는 오우거 컴파일에 사용할 컴파일러의 버전을 선택해 줍니다.
우측 라이브러리 형식에서는 원하는 형식의 라이브러리를 선택합니다. 제 경우에는 최소 설치를 위해 멀티스레드 DLL만을 선택해 주었습니다.
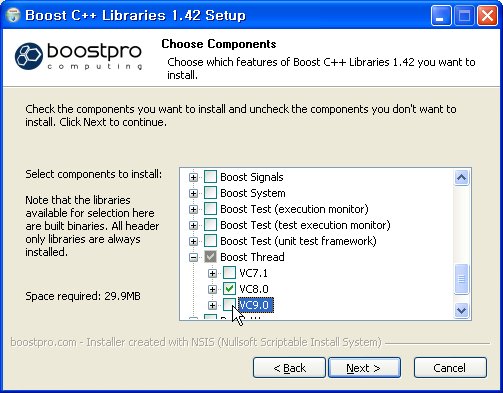
다음으로 설치할 라이브러리 항목들을 선택하는 창이 뜹니다.
오우거의 지형엔진이 사용하는 라이브러리는 Boost DateTime과 Boost Thread 입니다. 이 두 항목은 반드시 체크해 주어야 합니다.
선택한 항목의 서브 항목에서 필요하지 않은 버전의 컴파일러는 체크를 해제해 줍니다.
선택을 완료하고 Next를 클릭하면 다운로드 및 설치가 시작됩니다.
Boost는 상당히 쓸만한 라이브러리이므로, 꼭 오우거가 아니라도 다른 프로그램을 만드는 작업에서 이 라이브러리를 사용할 수도 있으므로 죄다 설치해 주는 것이 좋지만 많은 항목을 선택할 수록 다운로드 시간이 더 오래 걸린다는 것도 염두에 두시기 바랍니다.
저는 중국에 거주하고 있는데 인터넷 속도가 엉망이라 다운 받는데 돌아버릴거 같군요.
Boost의 인스톨이 완료되었다면 나중에 cmake가 Boost를 제대로 찾을 수 있도록 환경변수를 등록해 주어야 합니다.
[내 컴퓨터 -> 속성 -> 고급 -> 환경 변수 -> 시스템 변수 -> 새로 만들기] 를 선택해서 다음과 같이 BOOST_ROOT 시스템 환경 변수를 추가해 줍니다.
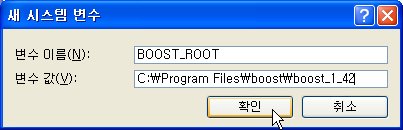
변수 값에는 여러분이 설치한 경로를 입력해 주어야 합니다. 인스톨 과정에서 특별히 설치경로를 변경하지 않았다면 위의 이미지와 같은 경로일 것입니다.
같은 방법으로 아래 두 개의 변수를 더 등록해 줍니다.
BOOST_INCLUDEDIR -> C:\Program Files\boost\boost_1_42
BOOST_LIBRARYDIR -> C:\Program Files\boost\boost_1_42\lib
이제 의존성 패키지를 설치해야 합니다.
앞서 오우거의 소스코드를 다운로드 했던 페이지(http://www.ogre3d.org/download/source)에서 Microsoft Visual C++ Dependencies Package를 다운로드 합니다.
OgreDependencies_MSVC_20100501.zip이라는 파일을 다운로드하게 될 것입니다.
이 파일을 앞서 오우거 소스를 압축 해제해서 생성된 폴더 안에 압축을 해제합니다. 이 파일의 압축을 해제하면 Dependencies라는 폴더가 생성되는데, 이 폴더는 오우거 소스 폴더의 OgreMain 폴더와 같은 위치에 존재해야 합니다.
즉, 저의 경우에는 C:\ogre_src_v1-7-1 라는 폴더에 압축을 해제하게 되는 거죠.
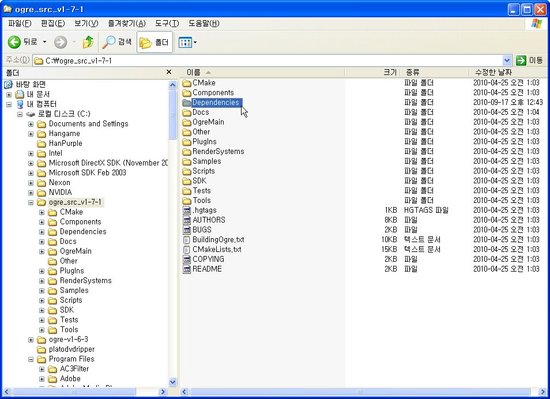
압축을 해제하고 난 후 오우거 소스 폴더의 모습입니다. 보시는 바와 같이 C:\ogre_src_v1-7-1 폴더 안에 Dependencies라는 폴더가 새로이 생성된 것을 알 수 있습니다.
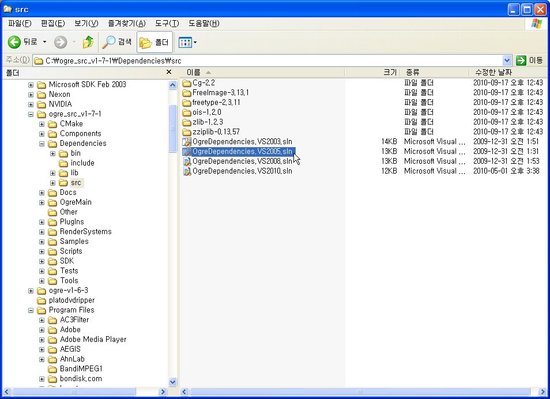
Dependencies 폴더 안에 src라는 폴더가 있을 것인데 그 폴더 안에 들어가 보면 지원되는 비주얼 스튜디오 각 버전에 따른 솔루션 파일 (*.sln)이 있을 것입니다.
자신이 사용하는 버전에 맞는 이름을 가진 솔루션 파일을 비주얼 스튜디오를 사용해서 엽니다.
이 솔루션에는 14개의 프로젝트가 포함되어 있을 것입니다. 이 솔루션을 디버그 모드와 릴리즈 모드에서 각각 컴파일합니다.
디버그 모드와 릴리즈 모드를 따로 한번씩 컴파일하는 것 보다는 일괄 빌드 기능을 사용하는 것이 편리합니다.
비주얼 스튜디오에서 [빌드 -> 일괄 빌드]를 선택합니다.
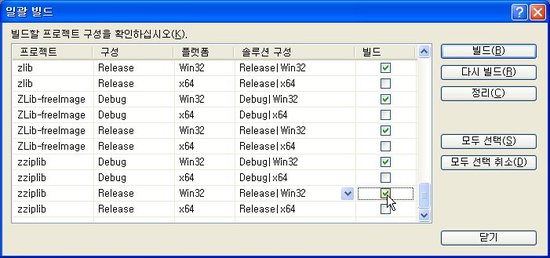
일괄 빌드 대화상자에서 솔루션에 포함된 모든 프로젝트에 대해서 Win32 디버그와 Win32 릴리즈를 선택해주고 빌드를 클릭합니다.
컴파일이 시작되고, 약간의 시간이 소요될 것입니다.
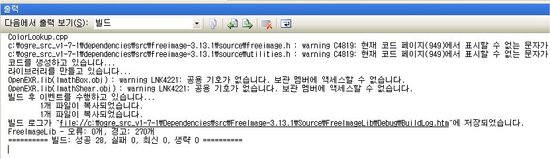
컴파일이 완료되고 난 후에 위와 같이 실패가 없으면 성공입니다.
이제 cmake를 이용하여 소스로부터 오우거 프로젝트들을 생성해야 합니다.
cmake는 크로스 플랫폼 빌드 시스템인데, 정확히 말하면 빌드 환경 설정 프로그램이라고 할 수 있습니다. 소스 코드들과 개발 도구 등의 시스템 환경들에 맞춰 가장 적합한 빌드 환경을 만들어 주는 프로그램이라고 할 수 있습니다.
마치 리눅스에서 make 명령을 실행하기 전에 configure를 사용하여 컴파일 환경을 수집하는 것과 같은 역할을 한다고 보면 되겠습니다.
우리는 윈도우즈 환경에서 작업하고 있으므로, cmake-gui (윈도우즈 환경에 맞춰진 GUI를 지원하는 버전)를 사용하면 됩니다.
cmake-gui는 여기에서 다운로드 할 수 있습니다.
http://www.cmake.org
특별히 cmake의 소스를 살펴보고 싶은게 아니라면 RESOURCES->Download 에서 Binary distributions -> Windows (Win32 Installer)라고 되어 있는 인스톨러를 다운로드 하도록 합니다.
cmake는 최신버전을 다운로드 하도록 합니다.
다운로드가 완료되면 인스톨러를 실행하여 원하는 위치에 설치하고, 설치가 완료되면 cmake-gui를 실행합니다.
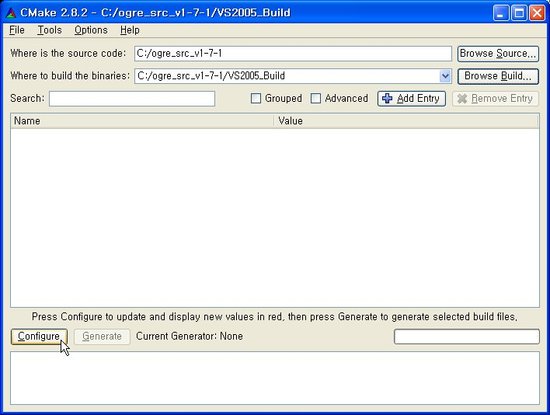
실행하면 위와 같은 창이 열리는데, Where is the source code: 항목에 우리가 앞서 오우거 소스를 압축해제한 폴더 (즉, OgreMain 폴더가 존재하는 폴더)를 지정해주고, Where to build binaries: 항목에 cmake가 빌드 시스템을 출력하기를 원하는 경로를 지정해 줍니다.
cmake가 만드는 결과물은 컴파일이 완료된 오우거 엔진이 아니라, 비주얼 스튜디오로 컴파일할 수 있는 오우거 엔진의 소스 프로젝트라는 것을 기억하시기 바랍니다. cmake로 빌드 환경을 만들고 나서 최종적으로 비주얼 스튜디오를 이용해서 다시 한번 빌드해주어야 비로서 오우거 엔진이 만들어진다는 것이지요.
제 경우는 앞서 오우거 소스를 압축해제한 폴더 안에 VS2005_Build라는 새 폴더를 만들어서 지정해 주었습니다.
경로 설정이 완료되었으면, 아래쪽에 있는 Configure 버튼을 클릭합니다.
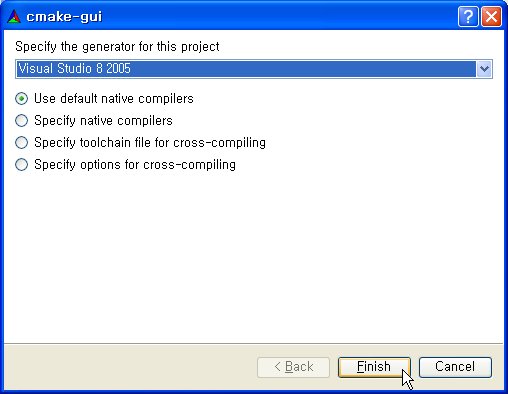
사용하려는 컴파일러 버전을 묻는 대화상자가 나타나는데, 위의 콤보 박스에서 자신이 사용하는 버전의 컴파일러를 선택해 준 후에 Finish를 클릭합니다.
그러면 cmake는 시스템 정보와 소스의 정보를 수집하기 시작할 것입니다.
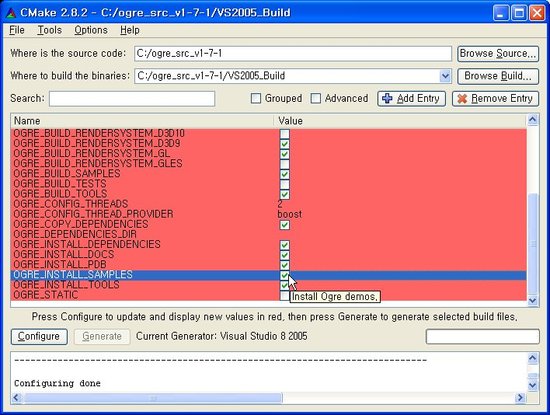
정보 수집이 완료되면 아래쪽 안내 창에 Configuring done 이라는 메시지가 나타나면서 프로젝트의 설정 옵션들이 보여집니다.
이 설정들은 대부분 디폴트 상태로 그대로 사용해도 상관이 없습니다. 각 설정 옵션들의 의미를 알고 싶다면 오우거 홈페이지 wiki에서 인스톨 관련 문서를 참조하시기 바랍니다.
제 경우에는 디폴트 설정에서 맨 아래에 OGRE_INSTALL_DOCS, OGRE_INSTALL_PDB, OGRE_INSTALL_SAMPLES를 추가로 체크해 주었습니다.
설정이 완료되었다면 Configure 버튼을 한번 더 클릭하여 설정을 저장합니다. 저장이 완료되고 나면 옆에 있는 Generate 버튼이 활성화 될 것인데, 이를 클릭합니다.
이제 cmake는 우리를 위해서 비주얼 스튜디오 2005로 컴파일할 수 있는 오우거 엔진의 프로젝트들과 솔루션을 만들어 줄 것입니다.
아무런 오류없이 Generating done 이라는 메시지가 나오면 완료된 것입니다.
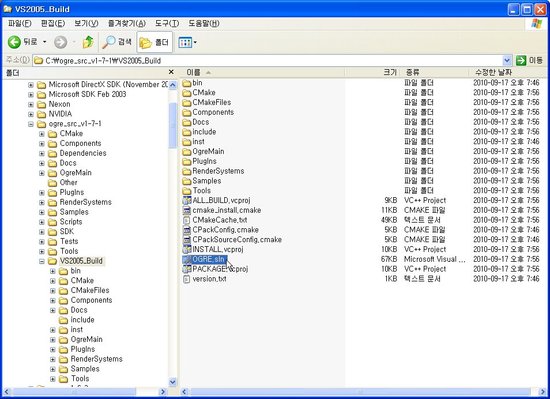
cmake가 빌드 환경 만들기를 완료하고 난 후, 우리가 cmake에게 지정해 주었던 출력 폴더로 가보면 빌드에 필요한 모든 소스들과 솔루션 파일이 생성된 것을 볼 수 있을 것입니다.
이 폴더 안에 OGRE.sln 솔루션 파일이 있을 것인데, 이것을 비주얼 스튜디오로 엽니다.
솔루션을 열면, 51개의 프로젝트가 포함되어 있을 것인데, 이 중에 ALL_BUILD라는 프로젝트가 보일 것입니다. 이것은 cmake가 우리를 위해 만들어준 프로젝트로, 이 프로젝트만 빌드하면 솔루션의 모든 프로젝트를 빌드해주게 됩니다.
이 역시 디버그 모드, 릴리즈 모드로 각각 컴파일 해야 하므로, 일괄 빌드 기능을 이용하도록 합니다.
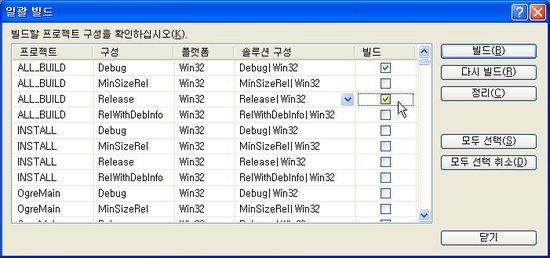
[빌드 -> 일괄 빌드]를 선택하고, 일괄 빌드 대화상자에서 ALL_BUILD 프로젝트에 대해서만 Debug|Win32, Release|Win32 항목을 체크해주고 빌드를 클릭하여 빌드를 시작합니다.
이 작업은 시간이 꽤 걸릴 것입니다. 커피한잔 마시면서 담배나 한대 피우며 빌드가 완료되기를 기다립시다.
아마도 문제없이 컴파일이 완료되었을 것입니다. 혹시 실패가 하나라도 발생한 다면 빌드 과정을 다시 한번 수행해 줍니다.
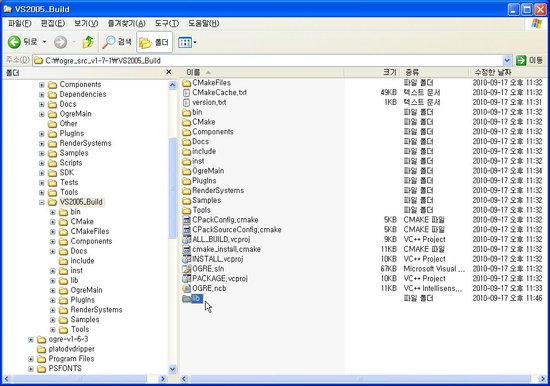
컴파일이 완료되고 나면 솔루션이 있는 경로에 lib 라는 폴더가 새로이 생성된 것이 보일 것입니다. 이 폴더에는 오우거 엔진의 lib 파일들(여러분이 오우거를 사용하는 응용프로그램을 만들때 링크해주어야 하는 파일들)이 추가되었을 것이며, bin 폴더에는 오우거 엔진의 각종 dll 들이 추가되었을 것입니다.
이제, 오우거 엔진이 제대로 컴파일 되었는지 확인 해 봅시다.
솔루션에 포함된 프로젝트들 중에서 SampleBrowser 프로젝트를 시작 프로젝트로 설정합니다.
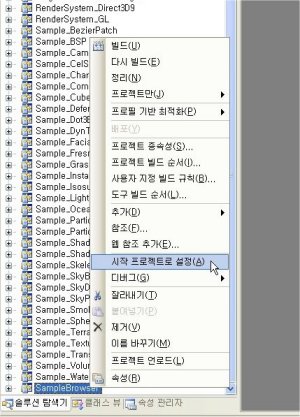
솔루션 탐색기에서 SampleBrowser 프로젝트를 우클릭하고 시작 프로젝트로 설정을 클릭하여 시작 프로젝트로 지정해준 뒤, [디버그 -> 디버그 시작] 또는 툴바의 플레이 버튼을 클릭하여 실행시킵니다.
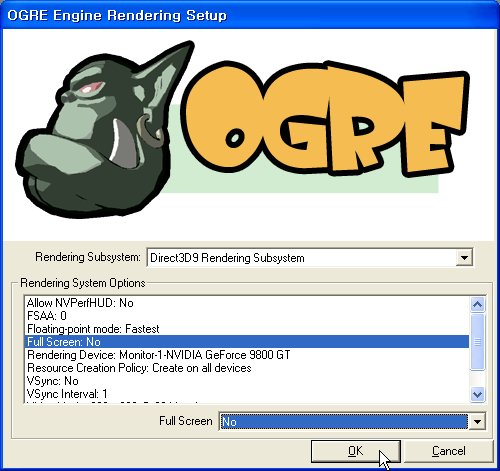
오우거의 설정 대화상자가 나타날 것입니다. Rendering Subsystem: 은 Direct3D9 Rendering Subsystem으로 지정해주고 Full Screen: 을 No로 설정한 뒤 OK를 클릭합니다.
오, 마이 갇 !
오우거 1.7.1 엔진의 중대한 버그가 발견되는 순간입니다!

오우거가 설정 내용을 저장하기를 시도하려고 할 때 위와 같은 예외가 발생하는 경우가 있습니다.
이 예외의 내용으로 검색을 해보니, 다양한 운영체제에서 동일한 예외를 만나는 사람들이 꽤 있는 것 같습니다.
포럼에서 사람들이 하는 이야기로는, 오우거 응용프로그램을 처음 시작할 때 나타난 설정 대화상자에서 선택한 (우리가 조금 전 설정 대화상자에서 선택한 옵션들) 내용을 오우거는 사용자의 홈 디렉토리, 즉, 제 경우에는 "C:\Documents and Settings\리치왕\My Documents\Ogre\Cthugha\ogre.cfg" 이런 경로에 저장하려고 시도하는데, 이 경로에 영문이 아닌 문자가 들어갈 때에 문제가 발생한다고 합니다.
그러나, 제가 디버깅해 본 바에 의하면 위의 경로가 정확하게 Root 객체에게 전달되는 것을 확인했습니다. 더우기, 회사에 있는 제 컴퓨터에서는 실행에 아무런 문제가 없었습니다. 또 집에서 사용중인 이 컴퓨터는 1.6.3 버전을 사용할 때에는 아무런 문제가 없었습니다!
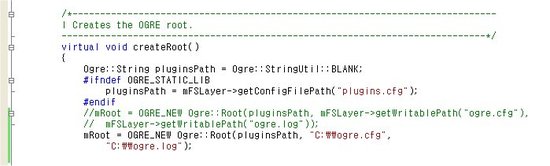
오우거의 Root 객체가 설정 파일의 경로를 어떻게 결정하는지 디버깅을 해보니, SampleBrowser의 createRoot라는 함수에서 Root 객체의 인스턴스를 생성하면서 생성자에게 경로명을 넘겨주고 있었습니다.
위의 코드는 SampleBrowser의 SampleContext.h 파일의 474번째 라인입니다. 위의 이미지에서는 주석처리된 부분이 원래 코드이고, 바로 아래는 제가 테스트를 위해 경로명을 변경하여 하드코딩으로 대체한 코드입니다.
일단 이렇게 처리한 후에 SampleBrowser를 다시 컴파일하고 실행하니 정상적으로 실행이 되는 군요.
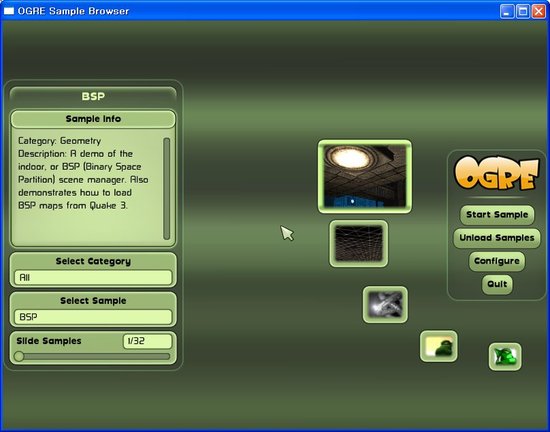
SampleBrowser가 실행된 모습입니다.
일단 오우거 엔진의 컴파일은 문제없이 정상적으로 이루어졌다는 것을 확인 할 수 있습니다.
위의 예외 문제의 정확한 원인을 진단하기 위해서는 좀 더 디버깅을 해 봐야 할 것 같습니다.
이제, 다 되었습니다. 오우거 설치를 마무리 지을 시간입니다.
다시 비주얼 스튜디오의 솔루션 탐색기를 보면 INSTALL 이라는 이름의 프로젝트가 보일 것입니다. 이 프로젝트를 빌드해주면 우리가 cmake에서 인스톨하기로 선택한 모든 항목들이 sdk라는 새 폴더가 생성되면서 이 폴더로 인스톨이 진행됩니다.
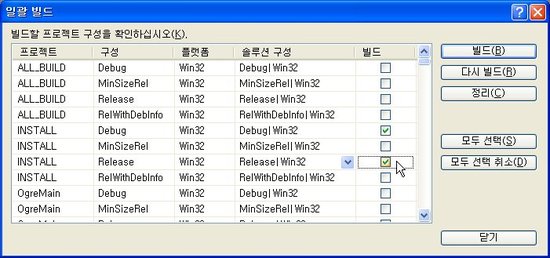
일괄 빌드 대화상자를 열고, INSTALL 프로젝트에 대해서만 Debug|Win32, Release|Win32 항목을 체크해주고 빌드합니다.
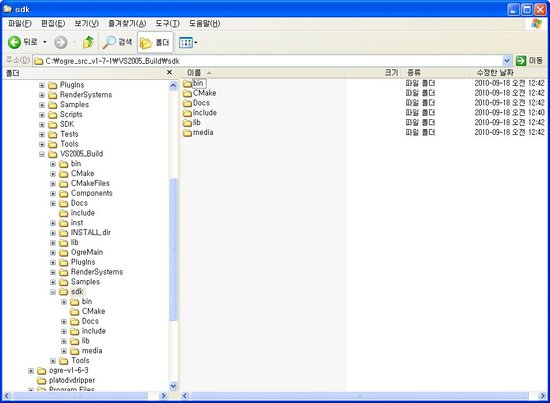
INSTALL 프로젝트를 모두 빌드하고 나면, 솔루션 폴더 아래에 sdk라는 폴더가 새로이 생성된 것이 보일 것입니다. 이 폴더 안의 bin 폴더에는 실제의 오우거 엔진 파일들 즉, DLL 파일들과 CFG 파일들이 인스톨되어 있고, lib 폴더에는 우리가 앞으로 만들게 될 프로그램이 링크할 수 있는 lib 파일들이, 그리고 include 폴더에는 프로그램이 포함할 수 있는 헤더 파일들이 인스톨되어 있습니다.
즉, 우리가 오우거를 이용하여 프로그램을 작성할 때, 프로젝트에 추가 포함 디렉터리로 이 include 폴더를, 추가 라이브러리 디렉터리로 이 lib 폴더를 지정해 주어야 한다는 것이지요.
media 폴더에는 데모 프로그램들이 사용하는 각종 리소스들(메시 파일들, 텍스처 파일들 등)이 들어 있습니다.
Docs 폴더에는 오우거 매뉴얼과 API 레퍼런스와 같은 문서가 들어 있습니다. 오우거를 공부하면서 참조하면 좋을 것입니다.
이 sdk 폴더는 현재 이 경로 그대로 두고 사용해도 되고, sdk 폴더를 따로 다른 경로로 이동시키고 폴더 이름을 자신이 알기 쉽도록 변경해서 사용해도 됩니다. 각자의 취향에 따라 선택하시면 될 것이나, 중요한 것은 여러분이 응용 프로그램 프로젝트를 만들 때 인클루드 디렉토리와 라이브러리 디렉토리의 경로를 지정해 주어야 그 프로젝트가 제대로 컴파일 될 것이란 점이지요.
자, 이제 오우거 1.7.1의 설치가 완료되었습니다. 수고하셨습니다 ^^







































![[http]](http://www.redwiki.net/wiki/imgs/http.png)


























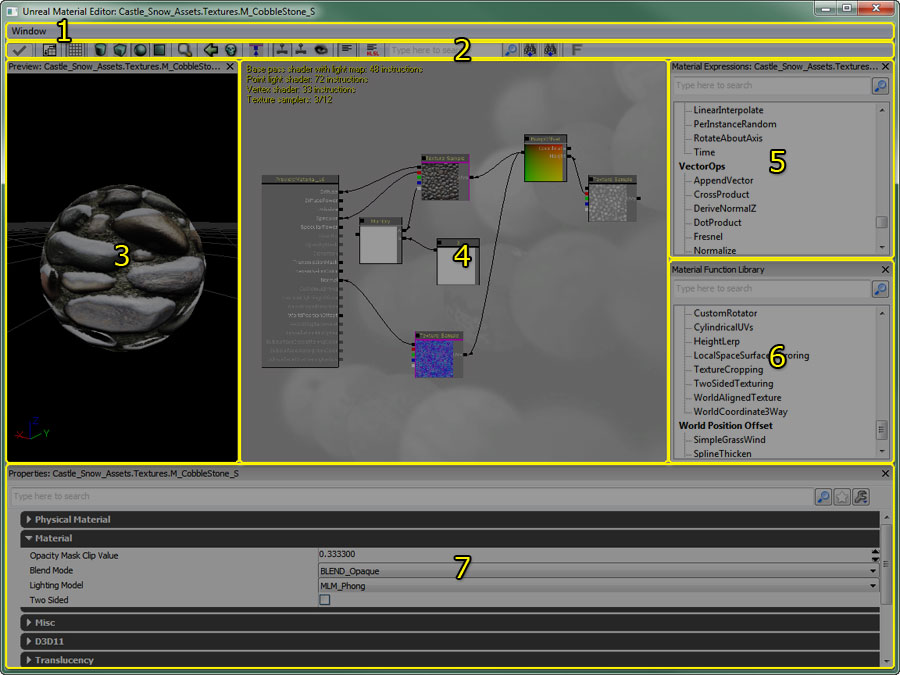



















 와
와  버튼을 사용하여 검색 결과
표현식 전부를 돌아가며 볼 수 있습니다.
버튼을 사용하여 검색 결과
표현식 전부를 돌아가며 볼 수 있습니다.
 버튼을 누르면 됩니다.
버튼을 누르면 됩니다.

about 7 months ago
You are looking up 10 and not 9 pixels! Coordinate 0.0 intersects two pixels and so you take full advantage of linear interpolation! Else you need to offset by half a pixel!
Where is the benefit of the usual easier way? Lookup at coordinates [-4, -2, 0, 2, 4] to get 10 pixel range and then apply the weighting of each two texels and calculate final value?
about 6 months ago
Hi Daniel,
This article was incredibly clear and informative. Thank you for taking the time to put it together. I’m still learning this stuff, so this was very helpful.
I wrote up a small Python script based on this post to generate the gaussian texture lookups, optimized for linear sampling. Maybe it can be useful to someone else too:
https://gist.github.com/2332010
Thanks again
about 1 month ago
Hey Daniel,
nice article, the connection with Pascal’s triangle is indeed very interesting.
I would like to add two things. First, maybe it would be good to add that Gaussian has a unit integral, since it’s probably one of the reasons the filtering works (in the continuous case at least). The 3D plot should also reflect this (meaning that such a wide Gaussian certainly wouldn’t reach a value of 1.6). This is of course just minor.
The second thing that struck me was:
“A Gaussian function with a distribution of 2σ is equivalent with the product of two Gaussian functions with a distribution of σ.”
This is just my opinion, but I think this doesn’t hold. First, I think such product won’t be a 2σ-Gaussian (properly normalized and all). Second, a repeated application of any filter corresponds to applying their *convolution*, which differs from product. And, convolution of two Gaussians with StD=σ produces a Gaussian with StD=Sqrt(2*σ^2)=σ*Sqrt(2).
I think what you meant was that product of 2 polynoms with order n (n-th row of Pascal triangle) gives you a polynom of order 2n? That should be true.
What do you think?
Oskar
about 1 month ago
You can do a 9-tap gaussian using only 2 texture fetches by sampling at one of corner of the center pixel in the first pass (f.x with an xy-offset of -0.5,0.5 ) and then sample the opposite corner in the next pass ( xy-offset of 0.5,-0.5 )
This results in the standard
121
242
121
9-tap gaussian.
You can do the same gaussian in a single pass if you sample at all 4 corners (4 texture fetches)
You can do a nice and very fast 7-tap blur in a single pass if you sample two opposite corners with an offset of 1/3 away from the center.
This results in a
121
282
121
convolution kernel.
If you calculate the strength of the blur by subtracting from the center pixel you can then scale the result so that it closely matches the regular 9-tap gaussian.
I also do a 17-tap blur using only 5 fetches in a single pass by sampling the center pixel and then offsets (0.4,-1.2) , (-1.2,-0.4) , (1.2,0.4) and (-0.4,1.2).
I then adjust the strength of it to more closely match the 9-tap gaussian.