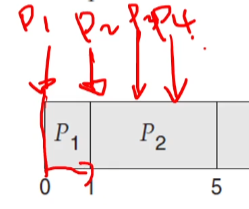
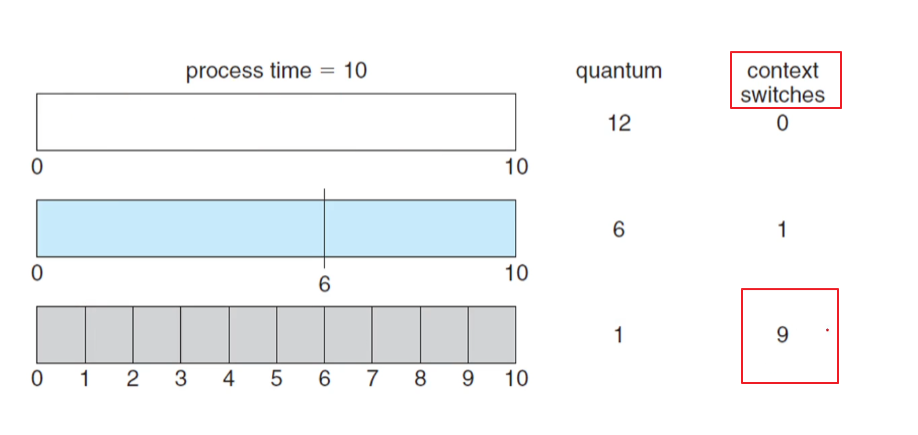
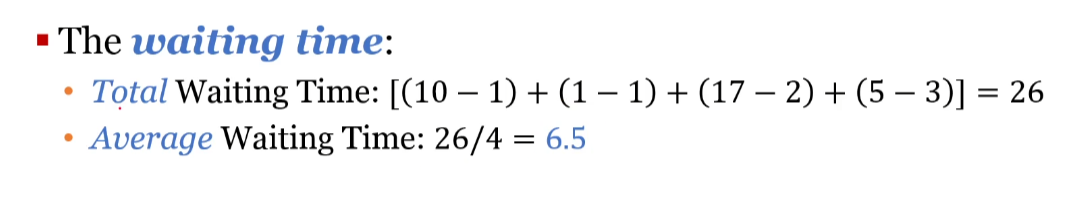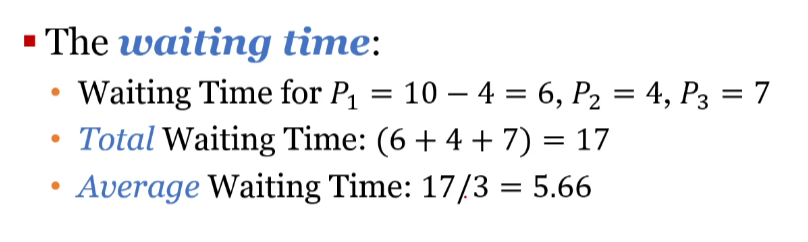반응형
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
namespace ConsoleApp2
{
public enum ClassType
{
Knight,
Archer,
Mage
}
public class Player
{
public ClassType ClassType { get; set; }
public int Level { get; set; }
public int HP { get; set; }
public int Attack { get; set; }
public List<int> Items { get; set; } = new List<int>();
}
class Linq
{
static List<Player> _players = new List<Player>();
static void Main(string[] args)
{
Random rand = new Random();
for(int i=0;i<100;++i)
{
ClassType type = ClassType.Knight;
switch(rand.Next(0, 3))
{
case 0:
type = ClassType.Knight;
break;
case 1:
type = ClassType.Archer;
break;
case 2:
type = ClassType.Mage;
break;
}
Player player = new Player()
{
ClassType = type,
Level = rand.Next(1, 100),
HP = rand.Next(100, 1000),
Attack = rand.Next(5, 50)
};
for(int j=0;j<5;++j)
{
player.Items.Add(rand.Next(1, 101));
}
_players.Add(player);
}
//join
{
List<int> levels = new List<int>() { 1, 5, 9};
var playerLevels =
from p in _players
join l in levels //player와 levels를 조인하는데
on p.Level equals l //레벨 i 와 player.level 이 같은것만 조인한다
select p;
foreach(var p in playerLevels)
{
Console.WriteLine(p.Level);
}
int test = 0;
}
GetHightLevelKnights();
}
//레벨이 50 이상인 knight 만 추려서 레벨을 낮음->놎음 순으로 정렬
private static void GetHightLevelKnights()
{
//linq 문법으로 db 쿼리문 처럼 조회 할 수 있다
//from 은 foreach 로 생각해도 괜찮다
//실행 순서는 from where orderby select 순으로실행된다 생각하면 된다
var players =
from p in _players
where p.ClassType == ClassType.Knight && p.Level >= 50
orderby p.Level
select p;
foreach (Player p in players)
{
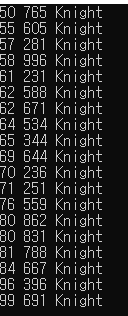
Console.WriteLine($"{ p.Level} {p.HP} {p.ClassType}");
}
}
}
}
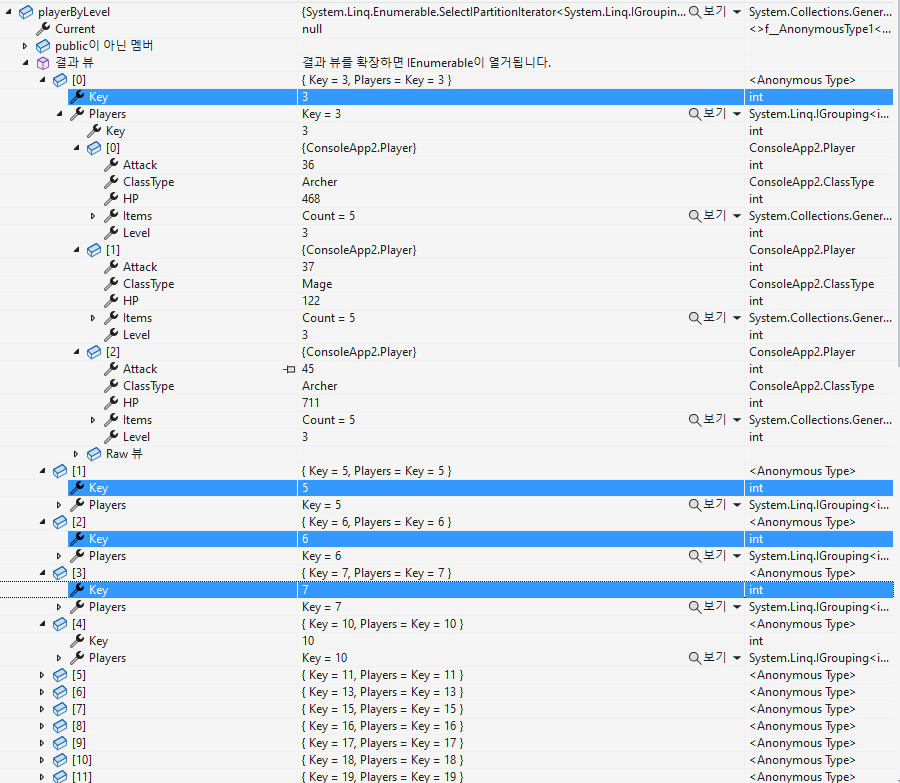
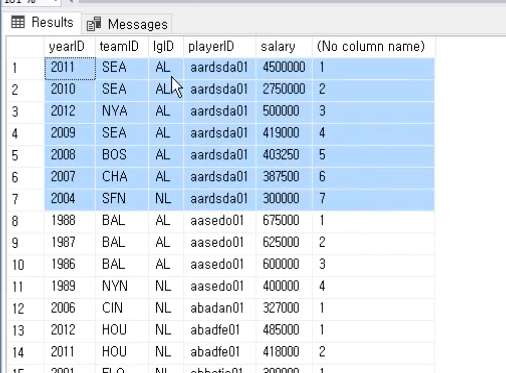
player와 levels를 조인하는데 레벨 i 와 player.level 이 같은것만 조인하게 한다
List<int> levels = new List<int>() { 1, 5, 9};
var playerLevels =
from p in _players
join l in levels
on p.Level equals l
select p;
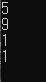
표준 Linq 방식
public enum ClassType
{
Knight,
Archer,
Mage
}
public class Player
{
public ClassType ClassType { get; set; }
public int Level { get; set; }
public int HP { get; set; }
public int Attack { get; set; }
public List<int> Items { get; set; } = new List<int>();
}
class Linq
{
static List<Player> _players = new List<Player>();
static void Main(string[] args)
{
Random rand = new Random();
for(int i=0;i<100;++i)
{
ClassType type = ClassType.Knight;
switch(rand.Next(0, 3))
{
case 0:
type = ClassType.Knight;
break;
case 1:
type = ClassType.Archer;
break;
case 2:
type = ClassType.Mage;
break;
}
Player player = new Player()
{
ClassType = type,
Level = rand.Next(1, 100),
HP = rand.Next(100, 1000),
Attack = rand.Next(5, 50)
};
for(int j=0;j<5;++j)
{
player.Items.Add(rand.Next(1, 101));
}
_players.Add(player);
}
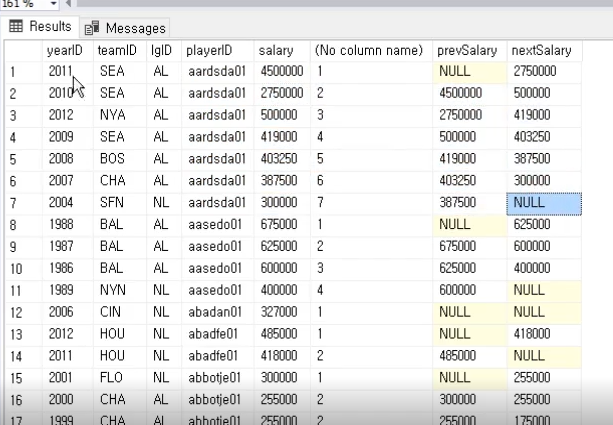
//중첩 from , ex : 모든 아이템 목록을 추출할때
{
var items = from p in _players
from i in p.Items
where i > 95
select new { p, i };
var li = items.ToList();
foreach(var elem in li)
{
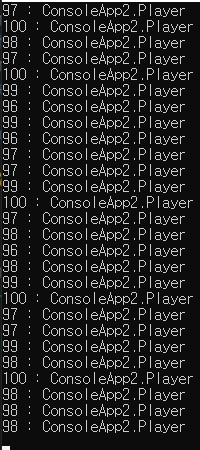
Console.WriteLine(elem.i +" : " + elem.p);
}
}
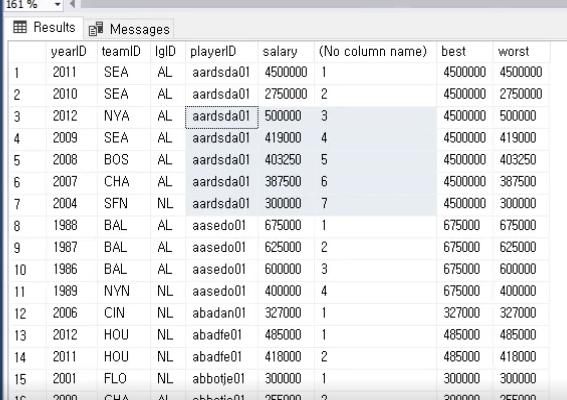
//linq 표준연산자
{
var players =
from p in _players
where p.ClassType == ClassType.Knight && p.Level >= 50
orderby p.Level
select p;
//위 결과와 아래 결과는 같다
//from 은 생략 가능
var sameResult = _players
.Where(p => p.ClassType == ClassType.Knight && p.Level >= 50)
.OrderBy(p => p.Level)
.Select(p => p);
int iii = 0;
}두개의 결과가 같은 것을 볼 수 있다
//linq 표준연산자
{
var players =
from p in _players
where p.ClassType == ClassType.Knight && p.Level >= 50
orderby p.Level
select p;
//위 결과와 아래 결과는 같다
//from 은 생략 가능
var sameResult = _players
.Where(p => p.ClassType == ClassType.Knight && p.Level >= 50)
.OrderBy(p => p.Level)
.Select(p => p);
결과 :

세부적인 기능을 사용하고 싶다면 함수형 linq 를 사용하면 된다
반응형
'프로그래밍(Programming) > C#' 카테고리의 다른 글
| default 연산자 (0) | 2023.04.25 |
|---|---|
| linq (2) (0) | 2023.04.09 |
| Linq (1) (0) | 2023.04.08 |
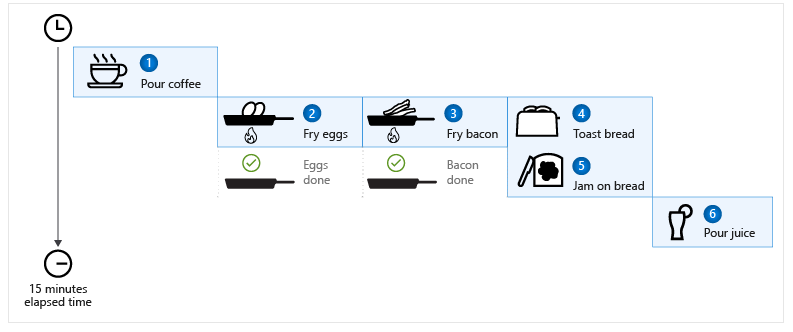
| async/await & 커피와 베이컨 (0) | 2023.04.07 |
| C# - ArraySegment (0) | 2023.01.04 |