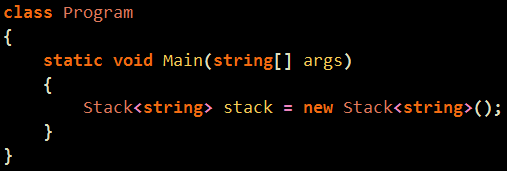
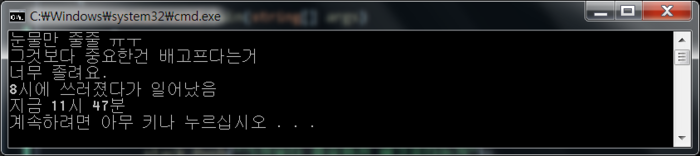
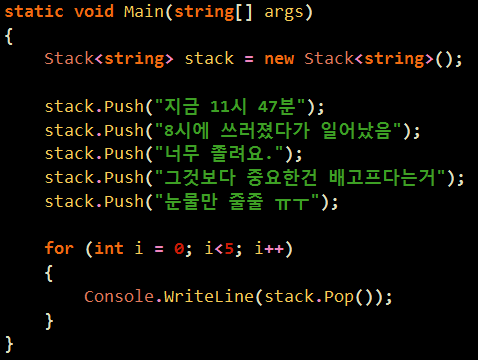
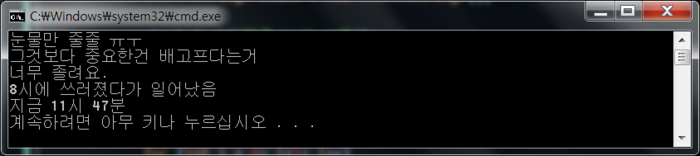
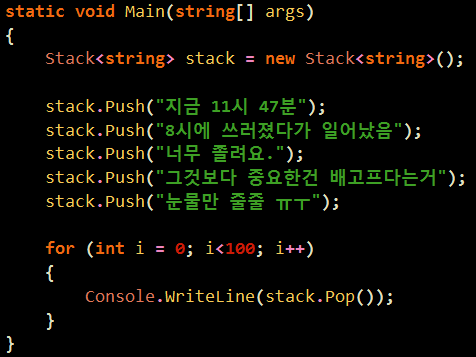
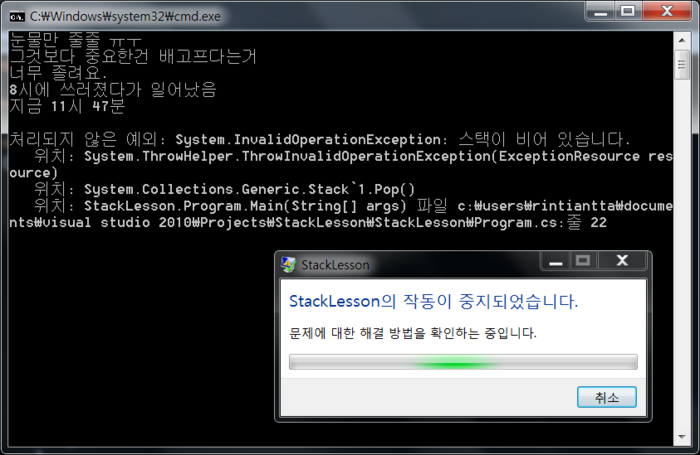
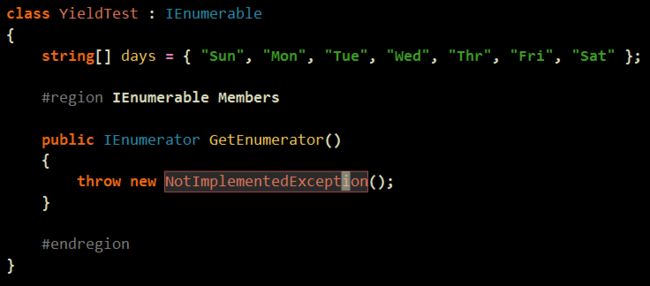
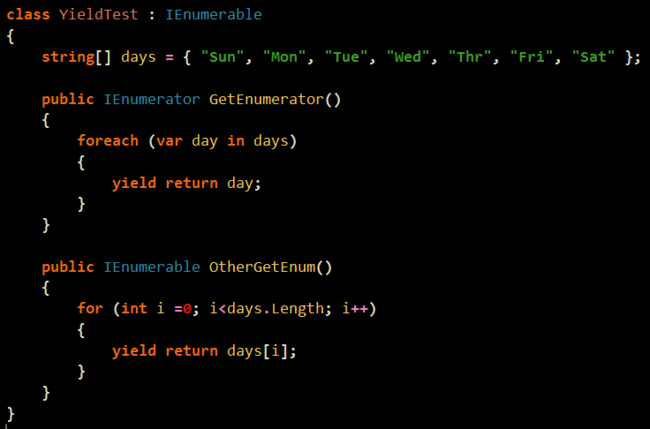
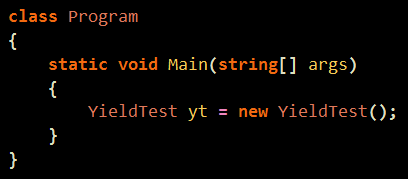
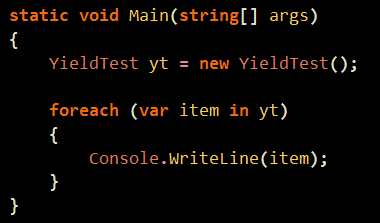
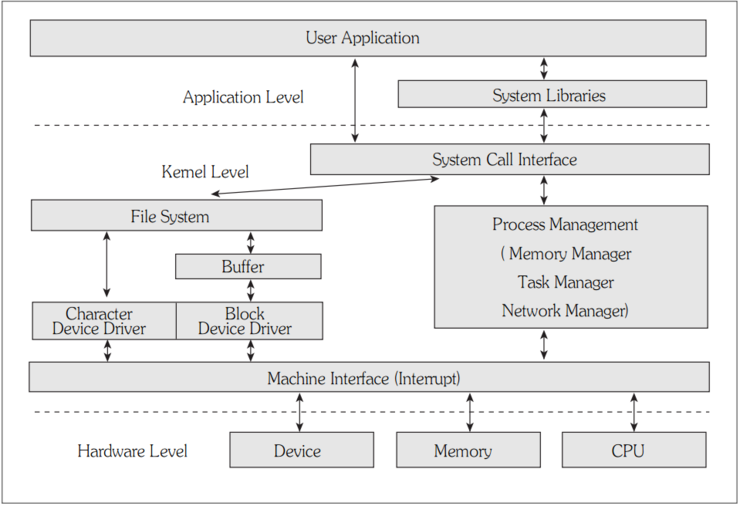
예전에 한번 비슷한 글을 레퍼런스 한적이 있는데 같은건지는 모르겠으나.. 괜찮은 글이라서 ㄱ ㄱ
출처 : http://itguru.tistory.com/196
안녕하세요? 이 글은 지난번에 우측값 레퍼런스에 관련한 글에 이어서 두 번째로 쓰는 C++ 토막글 입니다. C++ 토막글에서는 주로 C++ 11 에 추가된 최신 기술들을 다루고 있는데요, 아직 국내에 자료가 많이 부족하다 보니 체계적으로 쓰인 외국 자료들을 번역하는 형태로 제공하고 있습니다. 이 글은 http://ciere.com/cppnow12/lambda.pdf 에 올라온 pdf 자료를 바탕으로 번역된 글입니다. 사실 이 pdf 는 내용은 없고 소스만 있는 발표 자료이지만, 제가 발표자가 되었다고 가정해서 내용을 소개해보고자 합니다. 이 글이 C++ 11 의 강력한 기술인 Lambda 를 이해하는데 많은 도움이 되기를 바라겠습니다 :)
어떤 벡터의 원소들의 모든 곱을 계산하는 코드를 구성한다고 생각해봅시다. 아마 가장 초보적으로 이 코드를 구성하는 방법은 아마 아래와 같을 것입니다.
vector<int>::const_iterator iter = cardinal.begin();
vector<int>::const_iterator iter_end = cardinal.end();
int total_elements = 1;
while( iter != iter_end )
{
total_elements *= *iter;
++iter;
}
위는 반복자(iterator) 를 이용해서 cardinal 이라는 vector<int> 의 각 원소들을 순차적으로 참조해가며 total_elements 에 곱해나가는 코드입니다. 아주 직관적이고 단순하지만, C++ 을 처음 배우는, 아직 C++ 의 기능을 전부 접해보지 못한 초보자 수준의 코드이겠죠?
만일 "나는 C++ 쫌 해" 정도 되는 사람이라는 Functor 를 이용해서 아래와 같은 코드를 짜냈을 것입니다.
int total_elements = 1;
for_each( cardinal.begin(), cardinal.end(), product<int>(total_elements) );
template <typename T>
struct product
{
product( T & storage ) : value(storage) {}
template< typename V>
void operator()( V & v )
{
value *= v;
}
T & value;
};
위 코드는 C++ 고수 답게 for_each 와 Functor 를 이용한 코드를 짜냈습니다. for_each 를 사용해서 이전 코드의 while 문 부분을 싸그리 없앨 수 있지만, 이를 위해 필요한 Functor 를 구성하는 코드가 훨씬 깁니다. 마치 배보다 배꼽이 더 큰 격이군요. 물론 전체적인 코드의 질이 높아졌다고 볼 수 있지만, Functor 을 이용하기 위해 product 라는 구조체를 생성하면서 구질구질하게 생성자도 만들고, 또 void operator() 도 정의해주어야겠죠. 상당히 귀찮은 일이 아닐 수 없습니다.
int total_elements = 1;
for_each( cardinal.begin(), cardinal.end(), [&total_elements](int i){total_elements *= i;} );
자. 그럼 위 코드를 한번 봅시다. 짧고 간결하며, 무엇 보다도 while 문이나 functor 와 같은 구질구질한 코드 없이 깔끔하게 for_each 의 특징을 그대로 살려주었다고 볼 수 있습니다. 즉 Functor 에 들어갈 내용을 product 라는 구조체를 정의하면서 쭉 써내려갈 내용을 한 번에 깔끔하게 정리해놓은 것이지요. 이것이 바로 Lambda 의 위력입니다.
간단히 Functor 를 이용한 코드와 Lambda 를 이용한 코드를 비교해 보아도 그 차이를 실감할 수 있을 것입니다.
// Functor 사용
struct mod
{
mod(int m) : modulus(m) {}
int operator()(int v){ return v % modulus; }
int modulus;
};
int my_mod = 8;
transform( in.begin(), in.end(), out.begin(),
mod(my_mod) );
// Lambda 사용
int my_mod = 8;
transform( in.begin(), in.end(), out.begin(),
[my_mod](int v) ->int
{ return v % my_mod; } );
자 그럼 Lambda 를 사용하기 위해 Lambda 를 어떻게 C++ 에서 정의하는지 살펴보도록 합시다.

람다는 위 그림과 같이 4 개의 부분으로 구성되어 있습니다. 그 4 개의 부분은 각각 개시자 (introducer), 인자(parameters), 반환 타입 (return type), 그리고 함수의 몸통 (statement) 라 합니다. 일단, 람다 맨 처음에 나타나는 [] 는 개시자로, 그 안에 어떤 외부 변수를 써 넣는다면 람다 함수가 이를 Capture 해서, 이 변수를 람다 내부에서 이용할 수 있게 됩니다 (이에 대한 이야기는 뒤에서...) 위 경우 my_mod 라는 변수를 람다 내부에서 이용할 수 있게 됩니다.
그 다음의 () 는 람다가 실행시 받을 인자들을 써 넣습니다. 위 람다는 int 형의 v_ 를 인자로 받는 군요. 여기는 그냥 실제로 함수에서 사용하는 인자 리스트와 동일하게 적어주면 됩니다. 이제, 그 옆으로 보면 -> 가 있고 반환 타입을 적어주시면 됩니다. 위 람다의 경우 int 를 리턴합니다. 마지막으로 람다 내부에서 실행할 내용을 적어주면 되는데, 위 람다의 경우 v_ 와 my_mod 를 모듈러 연산해서 그 결과를 리턴하네요.
만일 우리가
[my_mod](int v_)->int{return v_ % my_mod;}
위와 같이 코드 상에 Lambda 를 썼다고 해봅시다. 그러면 런타임시 이름은 없지만, 메모리 상에 임시적으로 존재하는 클로져 (Closure) 객체가 생성됩니다. 이 클로져 객체는 함수 객체(function object)처럼 행동합니다. (이러한 연유로 람다를 람다 함수라고 부르는 경우가 있습니다 - 사실 엄밀히 말하면 클로져 객체지 함수는 아닙니다)
그렇다면
[](){ cout << "foo" << endl; }()
를 실행하였을 때 어떠한 결과가 나올까요? 일단
[](){ cout << "foo" << endl; }
로 임시적인 클로져 객체가 생성되었는데 () 를 붙여서 바로 이 임시 클로져 객체를 실행시켜 버리지요. 위 람다는 Capture 하는 변수들도 없고, 인자로 받는 것도 없고 리턴 타입도 없고 (참고로 리턴 타입이 void 일 경우 -> 를 생각 가능합니다) 함수 몸통만 덜렁 있기에 특별히 생각할 것도 없이 함수 몸통만 덜렁 실행되서

라고 나오게 됩니다.
그러면 조금 더 복잡한 예제를 살펴볼까요?
[](int v){cout << v << "*6=" << v*6 << endl;} (7);
는 어떨까요.
[](int v){cout << v << "*6=" << v*6 << endl;}
부분에서 인자로 v 를 받는 클로져가 생성되었는데, (7) 로 이 클로져에 인자로 7 을 전달시키면서 실행시켜버립니다. 따라서 모두가 예상 하였던 결과인

가 나오겠네요.
람다 자체가 함수 처럼 자유롭게 사용할 수 있는 것이기 때문에 인자로 (당연히) 레퍼런스 들도 전달 가능합니다. 예를 들어
int i = 7;
[](int & v){ v*= 6; } (i);
cout << "the correct value is: " << i << endl;
를 실행해보면

가 나옵니다.
참고로 받는 인자가 없을 경우, 예컨대
[](){ cout << "foo" << endl; }
의 경우 인자 () 를 생략 할 수 있습니다. 즉,
[]{ cout << "foo" << endl; }
도 동일한 의미입니다. (하지만 [] 는 지울 수 없습니다! )
사실 많은 경우 우리의 람다 안에서 람다 밖에 있는 변수들에게 접근하고 싶을 때가 있을 것입니다. 물론 "그렇다면 그 변수들을 그냥 인자로 받아버리면 되자나!" 라고 반문할 수 도 있겠지만, for_each 나 fill, transform 등의 C++ 의 파워풀한 STL 을 수행하기 위해서는 인자들을 맞추어 주어야 하는데 이 때문에 함수 내부로 전하고 싶어도 전달하지 못하는 인자들이 있기 마련 입니다.
따라서 이를 방지하기 위해, 람다 내부와 소통할 수 있는 또다른 문, Capture 를 제공하고 있습니다. Capture 하고자 하는 내용은 앞에서 말했듯이 [] 안에 들어오게 되는데, 대표적으로 아래의 4 개의 형태들이 있습니다.
- [&]() { . . . } 외부의 모든 변수들을 레퍼런스로 가져온다. (함수의 Call - by - reference 를 생각)
- [=]() { . . . } 외부의 모든 변수들을 값으로 가져온다. (함수의 Call - by - value 를 생각)
- [=, &x, &y] { . . . }, [&, x, y] { . . . } 외부의 모든 변수들을 값/레퍼런스로 가져오되, x 와 y 만 레퍼런스/값으로 가져온다
- [x, &y, &z] { . . . } 지정한 변수들을 지정한 바에 따라 가져온다.
그렇다면 한 번 예제를 살펴볼까요.
int total_elements = 1;
vector<int> cardinal;
cardinal.push_back(1);
cardinal.push_back(2);
cardinal.push_back(4);
cardinal.push_back(8);
for_each( cardinal.begin(), cardinal.end(),[&](int i){ total_elements*= i; } );
cout << "total elements : " << total_elements << endl;
위 코드에서 cardinal 에는 1, 2, 4, 8 이라는 원소들이 들어있고 그것을 for_each 를 통해 순회하면서 total_elements 에 곱하게 됩니다. 이 때 Capture 는 & 로 이므로 total_elements 를 Capture 할 수 있고, 람다 외부 변수인 total_elements 를 성공적으로 바꿀 수 있었던 것이죠. 위 코드를 실행하면 예상하던대로
가 나오게 됩니다.
이번에는 조금 더 복잡한 예제를 살펴보도록 합시다.
template< typename T >
void fill( vector<int> & v, T done )
{
int i = 0;
while( !done() )
{
v.push_back( i++ );
}
}
vector<int> stuff;
fill( stuff,
[&]()->bool{ return stuff.size() >= 8; } );
for_each (stuff.begin(), stuff.end(), [](int i) {cout << i << " " ;});
참고로 클로져 객체는 분명 특정 타입의 객체 이므로 위와 같이 template 에서 typename T 로 받을 수 있습니다. 위의 fill 함수는 특정 타입 T 의 변수 done 으로 클로져 객체를 받았습니다. 이 때, 클로져 객체 자체는 이미 stuff 를 Capture 해서 stuff 에 대한 레퍼런스를 계속 가지고 있는 상태이고, fill 의 while 문에서 돌면서 stuff 의 크기가 8 이하 일 때 까지 수행되게 됩니다. 따라서

로 출력됩니다.
void fill( vector<int> & v, T done )
{
int i = 0;
while( !done() )
{
v.push_back( i++ );
}
}
vector<int> stuff;
fill( stuff,
[&]()->bool{ int sum=0;
for_each( stuff.begin(), stuff.end(),
[&](int i){ sum += i; } );
return sum >= 10;
}
);
for_each (stuff.begin(), stuff.end(), [](int i) {cout << i << " " ;});
머리를 쫌만 굴려보면, 현재 stuff 의 원소 합이 10 이하일 때 까지 stuff 의 원소를 추가하는 람다라고 볼 수 있습니다.
당연히 그 결과는

한 가지 흥미로운 점은 Capture 를 레퍼런스가 아닌 값으로 할 때 언제 Capture 가 되냐는 것입니다.
int v = 42;
auto func = [=]{ cout << v << endl; };
v = 8;
func();
과연 위 소스에서 v 는 func 이 처음 정의될 때, 즉 클로져 객체가 생성될 때 Capture 될까요, 아니면 func 이 실행될 때 일까요? 만일 전자라면 42 가 출력될 것이고 후자라면 8 이 출력될 것입니다.
과연!

흥미롭게도 람다는 클로져 객체가 처음 생성될때 변수들의 값을 Capture 합니다.
Capture 를 값으로 할 때 주의점은 그 변수들에는 자동으로 const 속성이 붙는 다는 것입니다. 즉 값으로 Capture 시 그 변수들의 내용을 바꿀 수 없습니다. 따라서 아래와 같은 코드는
int i = 10;
auto two_i = [=]()->int{ i*= 2; return i; };
cout << "2i:" << two_i() << " i:" << i << endl;
컴파일 오류 " 'i': a by-value capture cannot be modified in a non-mutable lambda " 가 나게 됩니다. 위 코드에서 i 는 분명히 값으로 받았으므로 const 인데, i *= 2 를 통해 i 의 값을 바꾸려 하고 있으니 오류가 발생한 것입니다. 하지만, 함수 내부에서 i 의 값을 바꾸고자 하면 어떨까요? (물론 실제 외부의 i 의 값은 바뀌지 않습니다... 함수 내부에서만 - 마치 지역 변수처럼 말이죠)
답은 간단합니다. 람다에 mutable 속성을 추가해주면 됩니다.
int i = 10;
auto two_i = [=]() mutable ->int{ i*= 2; return i; };
cout << "2i:" << two_i() << " i:" << i << endl;
이로써 람다 내부에서 i 의 값을 변경할 수 있습니다. 물론, 다시 말하지만 외부의 i 의 값이 바뀌는 것이 아닙니다. 오직 람다 함수 내에서 '어떤 다른 i ' 의 값이 두 배가 되는 것이지요. 그 결과

로 나타남을 알 수 있습니다.
이제 그럼 조금 복잡한 코드를 살펴볼까요.
class gorp
{
vector<int> values;
int m_;
public:
gorp(int mod) : m_(mod) {}
gorp& put(int v){ values.push_back(v); return *this; }
int extras()
{
int count = 0;
for_each( values.begin(), values.end(),
[=,&count](int v){ count += v % m_; } );
return count;
}
};
gorp g(4);
g.put(3).put(7).put(8);
cout << "extras: " << g.extras();
사실 위 코드는 상당히 재미있는 코드입니다. extras 함수를 호출하면 람다가 각 원소를 4 로 나눈 나머지들의 합을 구해서 더해주는데요, 한 가지 궁금한점! 과연 람다에서 어떻게 m_ 을 capture 할 수 있었을까요? 람다는 여기서 암묵적으로 (implicit) 클래스의 this 를 Capture 했기 때문에 m_ 을 접근할 수 있었던 것입니다.
따라서 위 코드는

으로 성공적인 결과를 보여줍니다.
이렇게 this 를 암묵적으로 Capture 할 수 있기에 아래와 같은 놀라운 일도 발생할 수 있습니다.
struct foo
{
foo() : i(0) {}
void amazing(){ [=]{ i=8; }(); }
int i;
};
foo f;
f.amazing();
cout << "f.i : " << f.i;
위 코드를 언뜻 보면 i 를 값으로 capture 햇는데 어떻게 8 을 대입할 수 있냐고 물을 수 있는데, 사실 this 를 Capture 해서 this.i = 8 을 통해 mutable 없이도 값을 바꿀 수 있습니다. 왜냐하면 분명 this.i = 8 에서 상수인 this 를 변경한 것은 아니기 때문이죠.
Capture 되는 개체들은 모두 람다가 정의된 위치에서 접근 가능해야만 합니다. 예를 들어
int i = 8;
{
int j = 2;
auto f = [=]{ cout << i/j; };
f();
}
의 코드는 람다의 위치에서 i, j 모두 접근 가능하기 때문에 Capture 가능하므로 정상적으로

가 나옵니다.
그렇다면 아래 코드는 어떨까요?
int i = 8;
auto f =
[i]()
{
int j = 2;
auto m = [=]{ cout << i/j; };
m();
};
f();
바깥의 람다에서 i 를 Capture 하였기에, 바깥의 람다 몸통 안에서 i 를 사용할 수 있겠지요. 따라서 내부의 람다는 i 를 Capture 할 수 있게 됩니다. 그렇기에, 위와 동일한 결과인
가 나오게 됩니다. 하지만, 만일 바깥의 람다에서 i 를 Capture 하지 않았다면 어떨까요.
int i = 8;
auto f =
[]()
{
int j = 2;
auto m = [=]{ cout << i/j; };
m();
};
f();
그러면 예상했던 대로 컴파일 오류 error C3493: 'i' cannot be implicitly captured because no default capture mode has been specified 가 나오게 됩니다.
조금 더 복잡한 예로 아래의 코드를 살펴봅시다.
int i = 8;
auto f =
[=]()
{
int j = 2;
auto m = [&]{ i /= j; };
m();
cout << "inner: " << i;
};
f();
cout << " outer: " << i;
일단 바깥의 람다는 i 를 값으로 Capture 하였기 때문에 바깥의 람다(f) 몸통에서는 i 에 const 속성이 붙습니다. 그런데, 내부의 람다(m) 가 그 i 를 레퍼런스로 Capture 해서 값을 변경하려고 했습니다. 그렇다면, 당연히 오류가 나겠지요. 실제로 컴파일 오류 'i': a by-value capture cannot be modified in a non-mutable lambda 가 발생하게 됩니다.
이를 해결하려면, 당연히도 mutable 속성을 붙여주면 됩니다.
int i = 8;
auto f =
[i]() mutable
{
int j = 2;
auto m = [&, j]() mutable{ i /= j; };
m();
cout << "inner: " << i;
};
f();
cout << " outer: " << i;
i 자체가 값으로 입력 되었기 때문에 outer i 의 값은 바뀌지 않고 8 로 남아 있고, 값으로 받은 i 가 m 에 의해서 2 로 나눠지므로 4 가 됩니다. 따라서, 그 결과

로 나오게 되죠.
모든 클로져 객체들은 암묵적으로 정의된 복사 생성자(copy constructor)와 소멸자(destructor)를 가지고 있습니다. 이 때 클로져 객체가 복사 생성 될 때 값으로 Capture 된 것들의 복사 생성이 일어나겠지요. 아래의 예를 한번 보도록 하겠습니다.
일단
struct trace
{
trace() : i(0) { cout << "construct\n"; }
trace(trace const &) { cout << "copy construct\n"; }
~trace() { cout << "destroy\n"; }
trace& operator=(trace&) { cout << "assign\n"; return *this;}
int i;
};
와 같이 생성, 복사 생성, 소멸, 그리고 대입 연산을 확인할 수 있는 trace 라는 구조체를 정의해놓고
trace t;
int i = 8;
auto f = [=]() { return i / 2; };
를 한다면 어떻게 나올까요? f 에서 t 를 사용하지 않았으므로, t 를 Capture 하지 않게 됩니다. 따라서 그냥

이 나오게 됩니다.
그렇다면 아래의 예는 어떨까요
trace t;
int i = 8;
auto m1 = [=]() { int i = t.i; };
cout << " --- make copy --- " << endl;
auto m2 = m1;
먼저 m1 을 생성하면서, 람다가 t 를 Capture 하였으므로 t 의 복사 생성자가 호출되게 됩니다. 왜냐하면 값으로 받았기 때문이지요. 만일 레퍼런스로 받았다면 복사 생성자가 호출되지 않았을 것입니다 (확인해보세요!) 그리고 아래의 auto m2 = m1; 에서 클로져 객체의 복사 생성이 일어나는데, 이 때, 클로져 객체의 복사 생성자가 값으로 Capture 된 객체들을 똑같이 복사 생성 해주게 됩니다. 따라서 또 한번 t 의 복사 생성자가 호출되겠지요. 그 결과 아래와 같이 출력됩니다.

람다를 저장 및 전달하는 방식으로 앞에서 두 가지 방법을 보았습니다. 바로
template<typename T> void foo(T f)
auto f = []{};
이지요. 우리가 만들어낸 클로져 객체의 타입이 정확히 무엇인지 몰라도 위와 같은 방법으로 성공적으로 처리할 수 있습니다.
또 다른 방법으로는 함수 포인터를 이용하는 방법이 있는데요, 이 경우 람다가 Capture 하는 것이 없어야만 합니다.
typedef int(*f_type)(int);
f_type f = [](int i)->int{ return i+20; };
cout << f(8);
(참고로 위 기능은 Visual Studio 2010 에서 지원되지 않습니다 - 그 후의 버전에서만 가능합니다)
위 역시 성공적으로 28 을 출력함을 알 수 있습니다.
그런데, C++ 11 에서는 클로져 객체를 전달하고 또 저장할 수 있는 막강한 기능이 제공됩니다. 바로 std::function 인데요, 그 어떤 클로져 객체나 함수 등을 모두 보관할 수 있는 만능 저장소 입니다. (참고로 std::function 은 Visual Studio 2010 에서 <functional> 을 include 해야 합니다)
std::function< int(std::string const &) > f;
f = [](std::string const & s)->int{ return s.size(); };
int size = f("http://itguru.tistory.com");
cout << size << endl;
std::function 은 위와 같이 std::function < 반환 타입 ( 인자 ) > 와 같은 형태로 쓰며, Capture 가 있어도 상관이 없습니다. 물론 위 코드는 실행하면

와 같이 잘 나오지요.
이 std::function 을 통해 아래와 같이 재밌는 코드도 짤 수 있습니다.
std::function<int(int)> f1;
std::function<int(int)> f2 =
[&](int i)->int
{
cout << i << " ";
if(i>5) { return f1(i-2); }
};
f1 =
[&](int i)->int
{
cout << i << " ";
return f2(++i);
};
f1(10);
이것이 가능한 이유는 만일 auto 를 이용하였더라면 auto f1 을 한 시점에서 f1 이 명확히 구현이 되어야 컴파일러에서 타입을 추정할 수 있는데, 위와 같은 경우 f1 을 구현하려면 f2 를 먼저 구현해야 하고, 또 f2 를 구현하려면 다시 f1 을 먼저 구현해야 하는 순환적인 논리 딜레마에 빠지게 됩니다. 따라서 function 을 이용해서 f1 을 선언만 해 놓은 뒤, f2 를 구현하고, 다시 f1 을 구현하면 됩니다.
위 코드를 실행하면

와 같이 잘 나옴을 알 수 있습니다.
마찬가지로 아래와 같은 재귀 호출 함수도 구현할 수 있습니다.
std::function<int(int)> fact;
fact =
[&fact](int n)->int
{
if(n==0){ return 1; }
else
{
return (n * fact(n-1));
}
};
cout << "factorial(4) : " << fact(4) << endl;
이 역시 auto 를 이용했더라면, 처음 Capture 부분에서 Capture 하는 대상의 타입이 명확히 정해지지 않은 상태이므로 컴파일러가 타입을 추정할 수 없게 됩니다. 하지만 function 을 이용해서 성공적으로 구현할 수 있습니다. 위 계산 결과는 당연히

가 나오겠지요.
C++ 에 새롭게 추가된 람다는 기존의 C++ 과 전혀 다른 새로운 개념 입니다. 하지만 람다를 이용하면 수십줄의 코드도 한 두 줄로 간추릴 수 있는, 엄청난 기능이 아닐 수 없습니다.
이제 여러분들 손에는 람다라는 막강한 도구가 주어졌습니다. 이를 어떻게 사용하느냐는 여러분의 몫이지요 :)
그리고 이런 훌륭한 강의를 제공해주신 Michael Caisse 님에게 감사의 말을 전합니다.

















.gif) 참고
참고