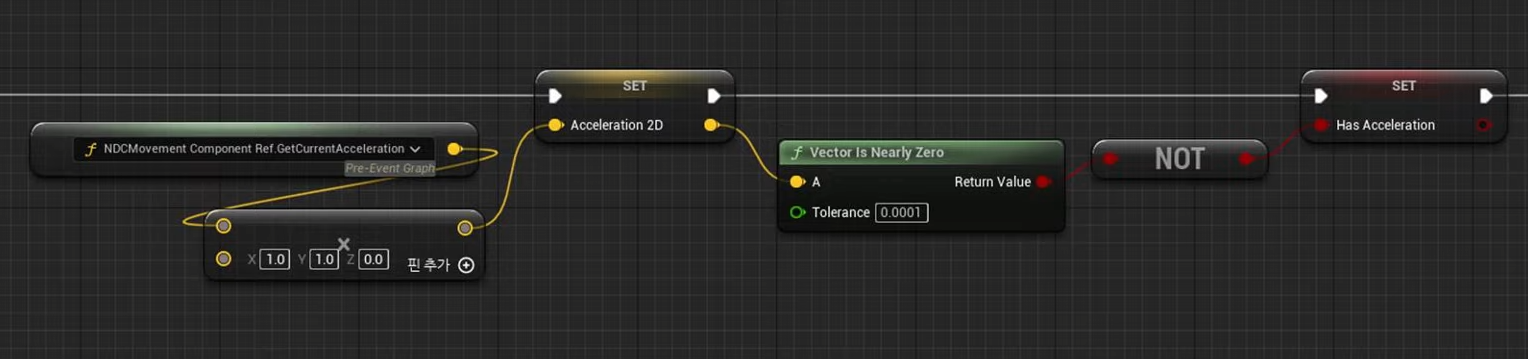
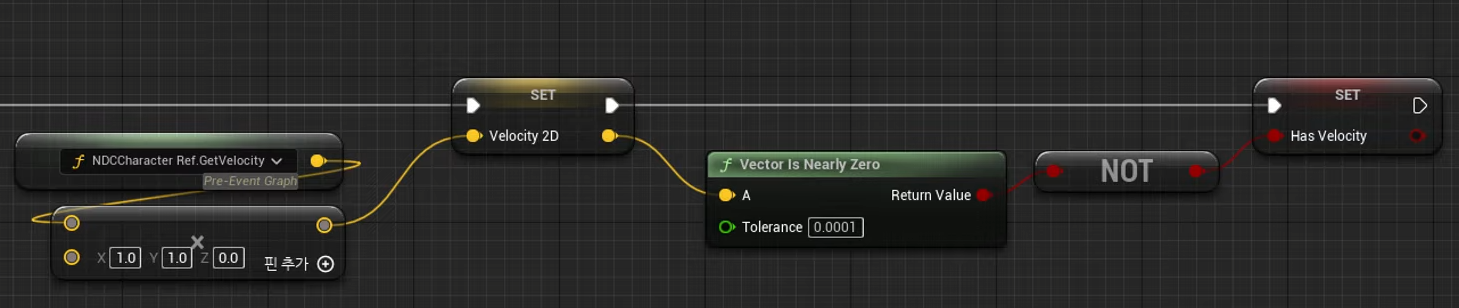
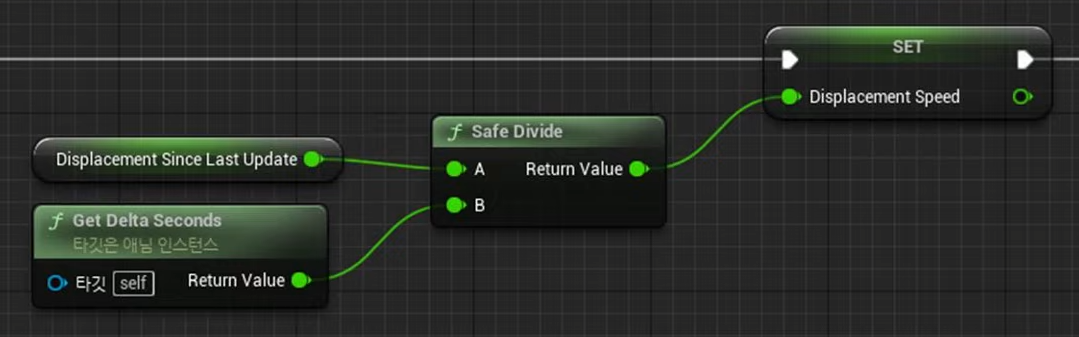
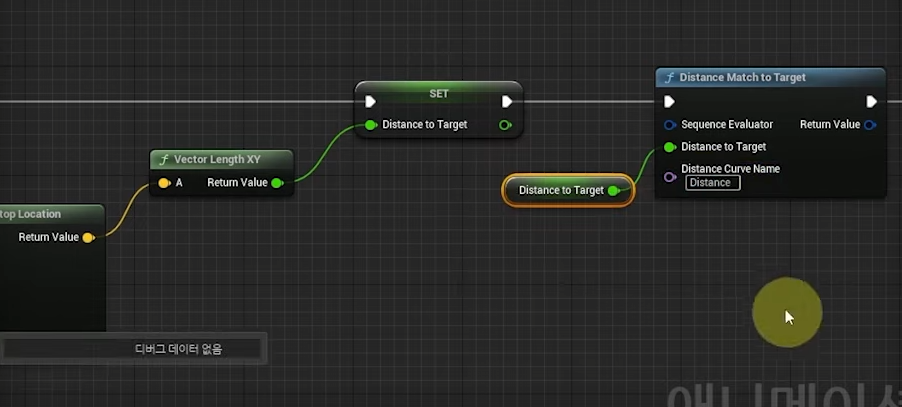
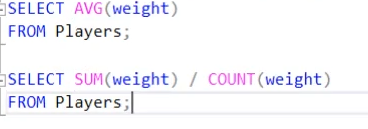
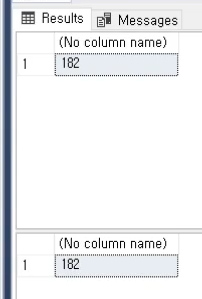
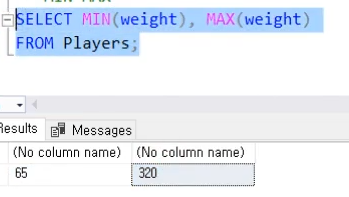
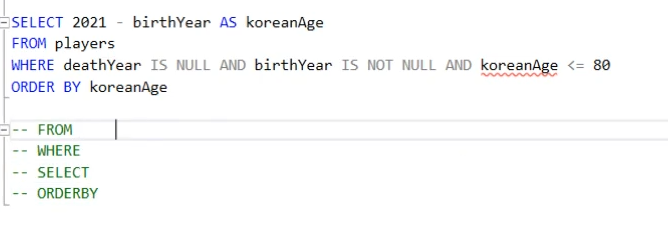
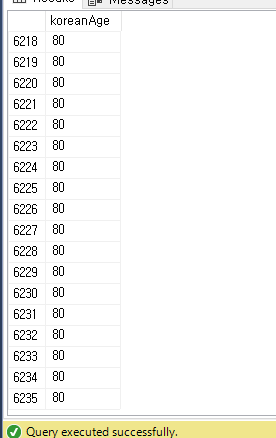
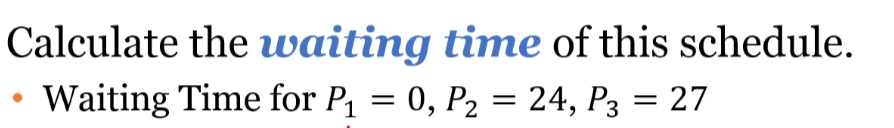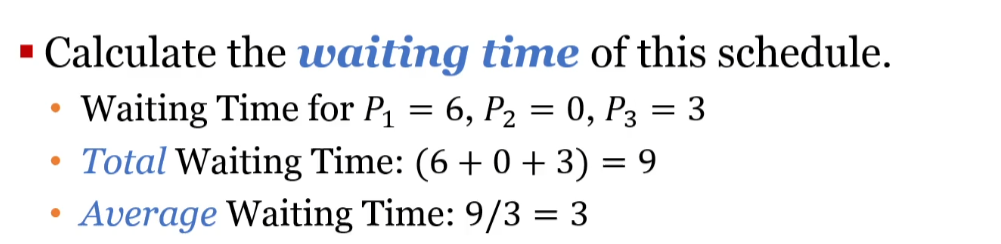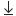Non-preemptive : 못 쫓아내는 것 , 이것은 프로세스가 cpu 를 선점하고 나면 그 프로세스가 릴리즈 끝날때까지 기다린다는 것
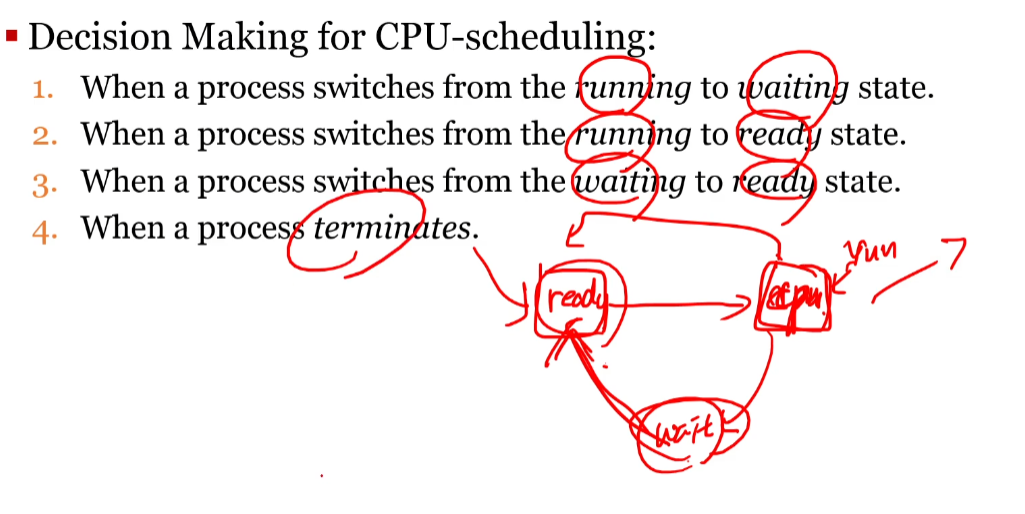
1,4번의 경우를 보면 자발적으로 wait 으로 가거나 terminate 상태로 간다 즉 non-preemptive 하기 때문에 non-preemptive 나 preemptive를 고민할 필요가 없다
2,3 번의 경우는 2번은 돌다가 레디로 가니 쫓아내어지게 되는 것이고 3번은 대기하고 있는것이 준비가 갔을때 준비로간 프로세스 우선순위가 높다면 바로 실행으로 가기 때문에 쫓아내는 형태가 될수 있다
디스패처(Dispatcher) 란? : 컨텍스트 스위치를 해주는 모듈을 디스패처라고 한다
디스패처는 당연히 빨라야 한다
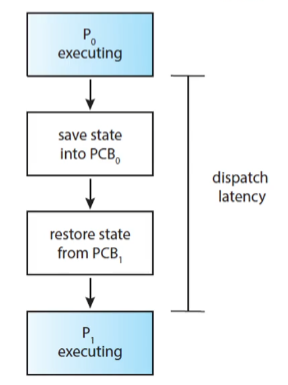
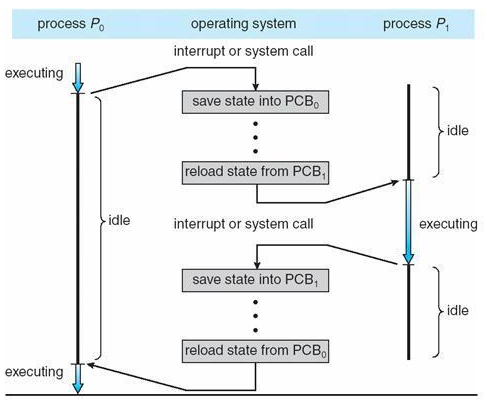
P0, P1 이 컨텍스트 스위칭 할때
PCB 란 운영체제가 프로세스를 제어하기 위해 정보를 저장해 놓은 곳으로 프로세스의 상태 정보를 저장하는 구조체이다
Context Switching 할대 필요하다
PCB 는 프로세스 생성 시 만들어지며 주기억장치에 유지된다
PCB0 번 블럭과 PCB1 번 블럭이 교체 되면서 컨텍스트 스위칭이 일어난다
그리고 이렇게 교체 되는 딜레이 시간을 dispatch latency 라고 한다 그리고 이 시간은 가금적 짧아야 한다
-------PCB에서 유지되는 정보---------- ● PID : 프로세스의 고유 번호 ● 상태 : 준비, 대기, 실행 등의 상태 ● 포인터 : 다음 실행될 프로세스의 포인터 ● Register save area : 레지스터 관련 정보 ● Priority : 스케줄링 및 프로세스 우선순위 ● 할당된 자원 정보 ● Account : CPU 사용시간, 실제 사용된 시간 ● 입출력 상태 정보 -------------------------------------------
CPU의 레지스터들의 값이 다른 것로 바뀌기 전에 어딘가에 저장을 하고 나가야해요. 이때 PCB에 CPU에서 수행되던 레지스터 값들이 저장이 됩니다. 내가 수행하던 프로세스가 어디까지 수행됐는지(프로그램 카운터), stack pointer의 위치가 어디인지, 그 외 register들의 집합 정보들을 잠시 저장한다는거죠. 어디에? PCB에! 그림을 보면 executing되다가 다른 프로세스 P1)을 수행시키기 위해 PCB0에다가 P0프로세스 정보를 저장하네요. 그리고 레지스터에 PCB1에 저장되어있던 process 1 정보를 가져와 P1을 수행시킵니다. 이런 저장 공간을 PCB라고 하고 사실 이렇게 수행중인 프로세스를 변경할 때 레지스터에 프로세스의 정보가 바뀌는 것을 Context Switching 문맥교환이라고 합니다.
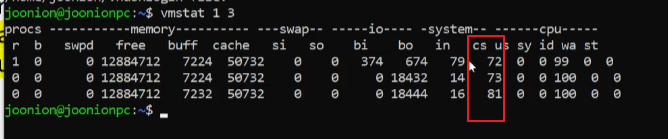
위 그림은 컨텍스트 스위치가 얼마나 자주일어나는지 알수 있는 내용이다
vmstat 1 3 은 1초에 3번 확인한것
1초에 72번 1초에 73번 1초에 81번은 CW 가 일어났다는 것
스케줄링 기준
CPU utilization : cup 가 놀지 않고 최대한 CPU 를 돌리는 방식을 말한다
Throughput : 이 수치를 높이는 것인데 단위시간 내에 프로세스의 완결되는 숫자를 높이는 것
Turnaround time : 프로세스가 실행하면서 종료 될때까지 즉 실행에서 종료되는 시간까지의 시간을 최소화 시키는 것
Waiting time : 어떤 프로세스가 Ready Queue 에서 대기 시간을 최소화 시켜주는 것으로 Ready queue 에 있는 대기 시간의 합을 최소화 시켜주는 방식
Response time : 응답 시간을 최소화 하는 것 (UI 같이 반응이 즉각 일어 나는 것들의 반응 시간을 최소화 하는것)
스케줄링 프로블럼 : Ready Queue 에 있는 프로세스 중에서 어떤걸 CPU 에 올릴것인지에 대한 문제
해결방법
FCFS : 처음 들어온걸 먼저 올려준다
SJF : SRTF : 의 방식은 짧은 잡을 먼저 올린다
이렇게 둘은 전체의 해당 프로세스의 시간이 있을때 그 시간 전체를 모두다 할당해 주는 방식이다
RR :Round-Robin : 시분할로 시간을 분할하여 정해진 시간 만큼 실행되고 해당 시간이 종료되면 다른것이 올라와 실행 되는 방식
Priority-based : RR 을 쓰는데 우선순위를 부여하여 선점하는 방식
MLQ : Multi-Level Queue : 경우에 따라서 위의 방식들 중에서 스케줄링 방식을 선택하는 것
DECLARE @i AS INT =100;
IF @i = 100
PRINT('100')
ELSE
PRINT('NOT')
여러줄 묶을땐 BEGIN END 로 묶어야 한다
DECLARE @i AS INT =100;
IF @i = 100
BEGIN
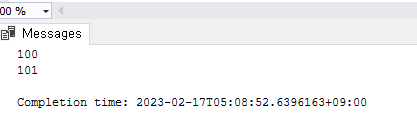
PRINT('100')
PRINT('101')
END
ELSE
PRINT('NOT')
WHILE 문 또한 사용가능하고 CONTINUE 와 BREAK 또한 있다
GO
DECLARE @i AS INT =0;
WHILE @i <= 10
BEGIN
SET @i = @i + 1;
IF @i = 6 CONTINUE;
PRINT @i;
END
원래 CREATE TABEL 명령어는 이런 형태였다
EX)
--테이블 만들기
create table accounts(
accountId integer not null,
accountName varchar(10) not null,
coins integer default 0,
createdTime DATETIME
);
그런데 테이블도 변수로 만들 수 있다 create table accounts 과 비슷하지만 다른건 tempDB 라는 곳에 임시로 데이터 베이스가 저장된다
--테이블도 변수로 만들 수 있다
--create table accounts( 과 비슷하지만 다른건 tempDB 라는 곳에 임시로 데이터 베이스가 저장된다
--
GO
DECLARE @test TABLE
(
name VARCHAR(50) NOT NULL,
salary INT NOT NULL
);
INSERT INTO @test
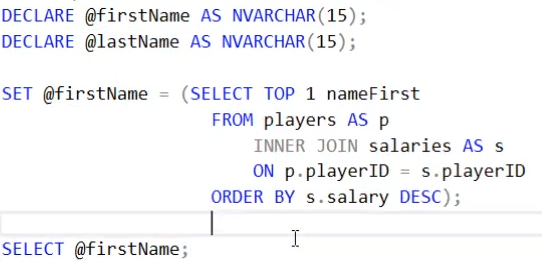
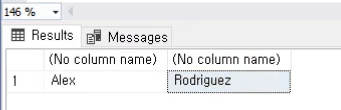
SELECT p.nameFirst + ' ' + p.nameLast, s.salary
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID = s.playerID;
SELECT *
FROM @test;
--변수 선언 , 생성함과 초기화 할수도있고
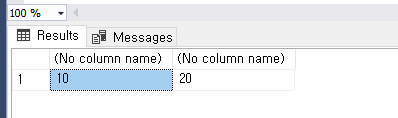
DECLARE @i as INT = 10;
--생성만 한다음, 나중에 넣을 수도 있다
DECLARE @j as INT;
SET @j = 20;
SELECT @i, @j;
---배치---
--이전에 썼던 변수는 없는걸로 치고 다시 변수를 선언할수 있는 명령어 go
GO
DECLARE @i AS INT =100;
SELECT @i;
A의 골드 감소 이렇게 모두 처리되야 하는데 중간에 실패가 난다면 완전히 거래가 처리 되는것이 아니고 오류가 되어버리는데 이렇게 되면 테이블 데이터가 잘못되게 된다, 강화 하는 경우에도 비슷한 케이스 All or Nothing 이런걸 해결 하기위해 TRANSACTION 이 있다 아무것도 쓰지 않으면 기본 적으로 TRANSACTION 이 있고 그 뒤에 COMMIT 이 있는 것인데 (EX : INSERT INTO ...) BEGIN TRAN; 을 명시하면 뒤에 COMMIT 또는 ROLLBACK 을 적어 처리할지 되돌릴지를 정할 수 있다
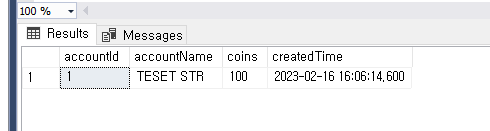
INSERT INTO accounts VALUES(1, 'TESET STR', 100, GETUTCDATE());
BEGIN TRAN;
INSERT INTO accounts VALUES(2, 'TESET STR', 100, GETUTCDATE());
ROLLBACK;
결과를 보면 두번째 것은 추가 안된것을 알수 있다 ROLLBACK 되었음으로
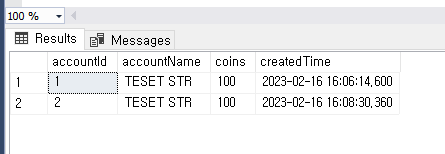
INSERT INTO accounts VALUES(1, 'TESET STR', 100, GETUTCDATE());
BEGIN TRAN;
INSERT INTO accounts VALUES(2, 'TESET STR', 100, GETUTCDATE());
COMMIT;
추가된 경우
아래 구문을 실행하기 전 데이터
--TRY CATCH 와 비슷한 구문
BEGIN TRY
BEGIN TRAN;
INSERT INTO accounts VALUES(1, 'T1', 100, GETUTCDATE());
INSERT INTO accounts VALUES(2, 'T2', 100, GETUTCDATE());
COMMIT;
END TRY
BEGIN CATCH
IF @@TRANCOUNT > 0
ROLLBACK;
END CATCH
@@TRANCOUNT 는 TRAN 이 몇개 인지 알수 있는 매크로인데
BEGIN TRAN;
TRAN;
이렇게 TRAN 을 중첩시키면 1이상이 될 수가 있는데 이때 이 개수를 리턴해주는게 @@TRANCOUNT 이다
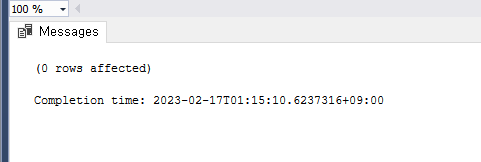
그리고 INSERT 는 accountId 가 primary key 임으로 이미 존재하는 키가 있을 경우 또다시 추가 하려고 하면 에러가 발생되어 catch 로 잡히게 된다
실행후 상황
아무 영향이 없었다는 걸 알 수 있다
PRINT('TTT') 를 ROLLBACK 구문 쪽에 써서 ROLLBACK 된 이유를 적어줄 수도 있다
중요한건 TRAN 으로 묶어놓은건 한번에 다 실행하거나 아니면 중간에 오류/예외가 발생하면 모두 실행되지 않는 다는 것이다
그리고 TRANSACTION 은 보통 두개 이상의 테이블에 어떤 변경이나 영향을 줄때 사용된다
사용시 주의 할점은
TRAN 안에는 꼭 원자적으로 실행될 애들만 넣어야 한다
즉 성능적으로 문제가 될 수 있기 때문인데
LOCK이 되기 때문
만약
BEGIN TRAN;
INSERT INTO accounts VALUES(2, 'TESET STR', 100, GETUTCDATE());
이렇게 까지 되어 있으면 위코드는 COMMIT 이나 ROLLBACK 을 만나기 전까지 계속 LOCK 리 걸린 상태가 되며
다른 구문에서 accounts 를 조회하려는 구문을 실행한다 해도 select 구문은 실행 되지 않고 계속 대기하게 된다
대기상태에 빠지게 됨 commit 이나 rollback 을 만나지 않는다면 원자적 특성때문에
같은 얘기지만 TRAN 과 COMMIT/ROLLBACK 사이의 구문은 길지 않게 작성하는 것이 좋다
CROSS JOIN (교차 결합) 서로 교차를 하면서 하나씩 결합을 한다는 것 (1,A), (1,B), (1,C), (2,A)... 총 9개
CREATE TABLE testA
(
a INTEGER
)
CREATE TABLE testB
(
B VARCHAR(10)
)
INSERT INTO testA VALUES(1);
INSERT INTO testA VALUES(2);
INSERT INTO testA VALUES(3);
INSERT INTO testB VALUES('A');
INSERT INTO testB VALUES('B');
INSERT INTO testB VALUES('C');
SELECT *
FROM testA;
SELECT *
FROM testB;
--CROSS JOIN (교차 결합)
--서로 교차를 하면서 하나씩 결합을 한다는 것
--(1,A), (1,B), (1,C), (2,A)... 총 9개
SELECT *
FROM testA
CROSS JOIN testB;
SELECT *
FROM testA, testB;
결과화면
기본 데이터 보기
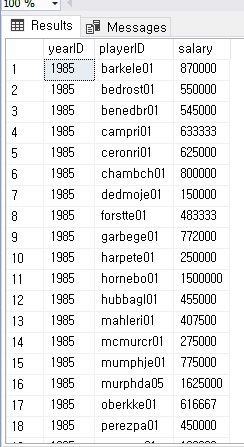
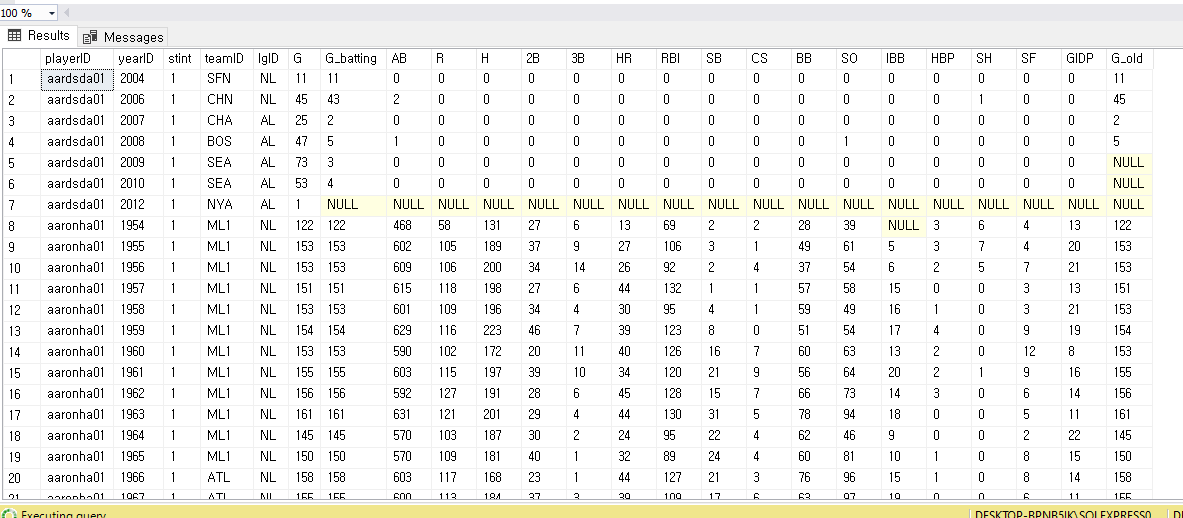
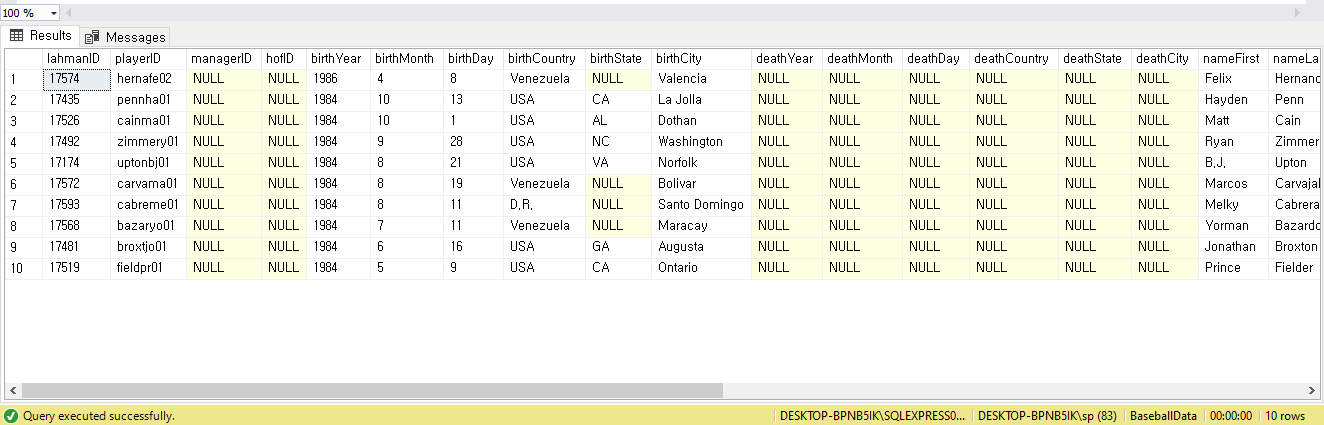
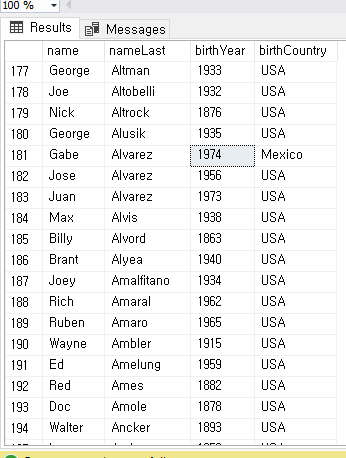
USE BaseballData;
SELECT *
FROM players
ORDER BY playerID;
SELECT *
FROM salaries
ORDER BY playerID;
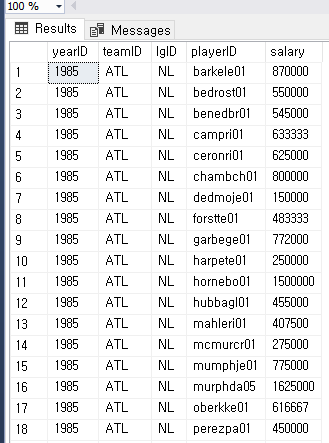
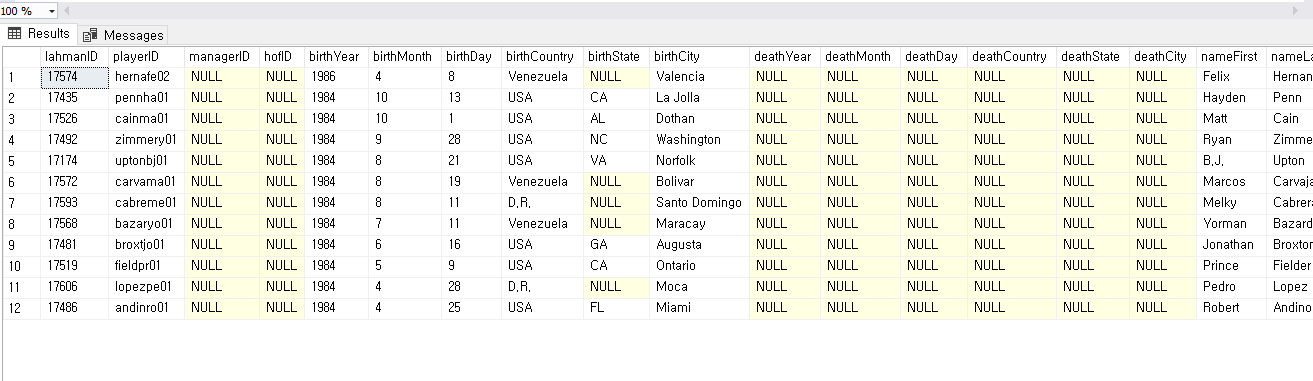
INNER JOIN(두개의 테이블을 가로로 결합 + 결합 기준을 ON 으로 한다) UNION 은 세로 즉 위아래로 합치는 것이였다면 INNER JOIN 은 옆으로 합치는 것
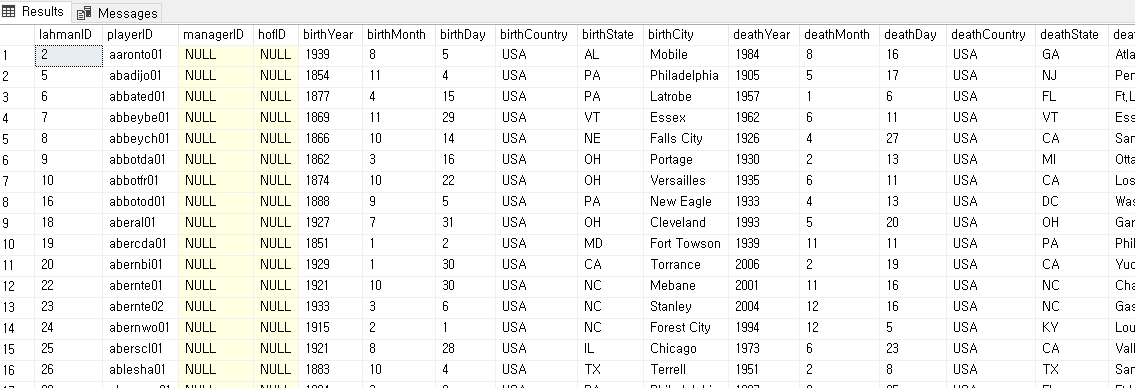
SELECT *
FROM players AS P
INNER JOIN salaries AS S
ON P.playerID = S.playerID;
players 의 playerID 와 salaries 의 playerID 가 같은 행 끼리 합치는 것
주의 할점은 조건이 = 인데 양쪽 모두에 playerID 가 있어야 붙여지게 되지 한쪽이라도 id 값이 없다면 해당 행은 걸러진다
즉 양쪽에 모두 정보가 있을때만 나온다
결과를 보면 뒤에 추가 된걸 볼 수 있다
inner join 을 한다는 건 새로운 테이블을 만든 것
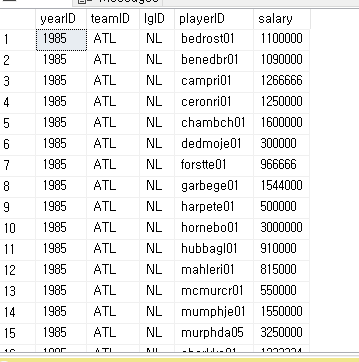
-- outer join (외부 결합) --어느 한쪽에만 존재하는 데이터가 있을때 정책을 어떻게 할것인지에 대한 것 -- left join 인경우로 예를 들어보면 두개를 조인 할때 왼쪽에만 있고 오른쪽에는 없다면 --왼쪽 정보를 그대로 채워 넣고 없는 오른쪽 정보는 null 로 채워 넣어서 join 을 한다는 것으로 --inner join 과 유사한데 비어 있는 것을 어떻게 처리 할것인가에 대한 내용이다
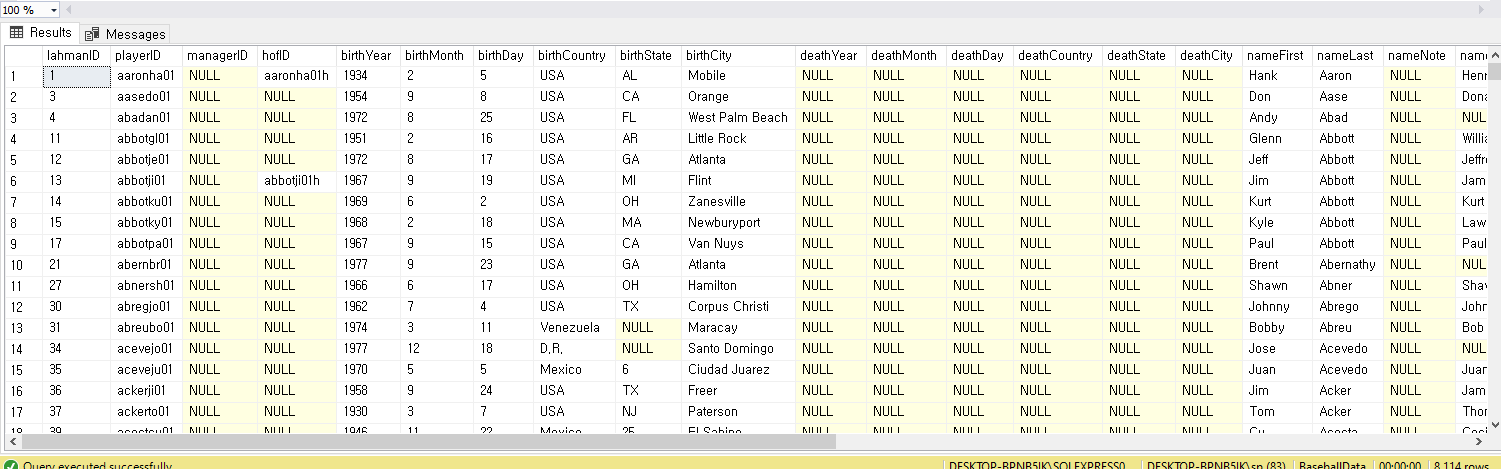
SELECT *
FROM players AS P
LEFT JOIN salaries AS S
ON P.playerID = S.playerID
ORDER BY P.playerID;
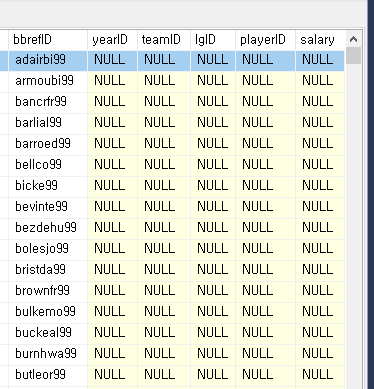
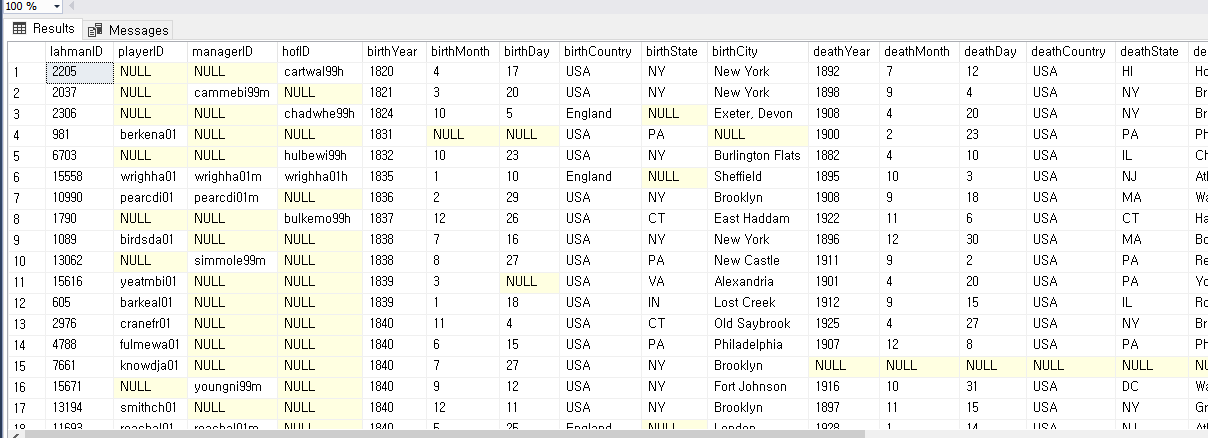
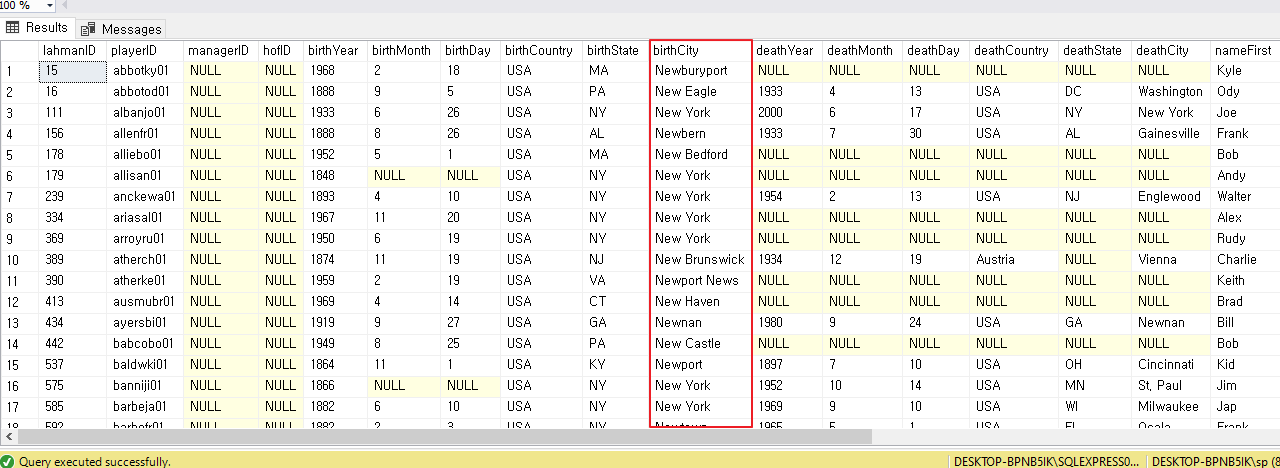
아래는 playerID 로 정렬하여 두 테이블(players과 salaries )을 본것이고
LEFT JOIN 한다음의 모습이다
adairbi99m 의 줄에서 끝을 보면
salaries 에는 adairbi99m 이 없기 때문에 끝에 NULL 로 채워진것을 볼 수 있다
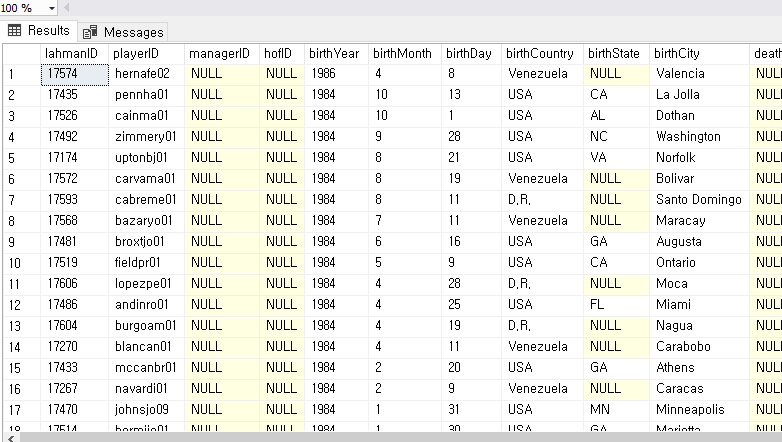
RIGHT JOIN 은 반대의 개념이 된다
정보가 오른쪽에 있다면 표시되고 그 이후에 같은 행에 왼쪽(plyaer)에 없으면 왼쪽 정보는 NULL 로 채워진다
예시 이미지
오른쪽에 정보는 있지만
왼쪽이 null 로 채워진 경우
그런데 left 나 right 나 테이블 순서를 바꿔주면 동일한 효과가 된다
정리하자면
cross join 은 * 이고
inner join, left join right 조인은 같은 행에 추가 하여 테이블을 만드는 것이다
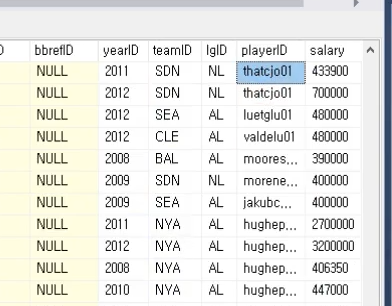
select playerID, AVG(salary)
from salaries
group by playerID
having AVG(salary) >= 3000000
UNION
--12월에 태어난 선수들의 playerID
select playerID, birthMonth
from players
where birthMonth = 12
order by playerID asc
;
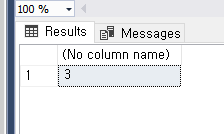
아래는 위 결과를 실행했을때의 결과인데 avg 와 birthmonth 때문에 합쳐지지 않아
silvaca01 이 별도 있는 거을 볼 수 있다
union 열을 같게끔 해주면 중복은제거된다
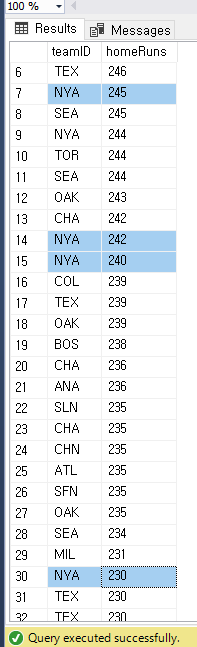
--커리어 평균 연봉이 3000000 이상인 선수들의 playerID
select playerID
from salaries
group by playerID
having AVG(salary) >= 300000
UNION
--12월에 태어난 선수들의 playerID
select playerID
from players
where birthMonth = 12
order by playerID asc
;
이렇게 하면 합쳐진 하나만 나오는 것을 알수 있다 ( 중복 제거 )
union all 은 중복을 허용한다
select playerID
from salaries
group by playerID
having AVG(salary) >= 300000
UNION all
--12월에 태어난 선수들의 playerID
select playerID
from players
where birthMonth = 12
order by playerID asc
;
union 을 쓰게 되면 order by 는 가장 하단에 와야 한다
교집합(intersect) 을 구한다 즉 양쪽 모두 만족하고 존재하는것을 구한다
--교집합(intersect) 을 구한다 즉 양쪽 모두 만족하고 존재하는것을 구한다
--커리어 평균 연봉이 3000000 이상이거나 (&&) 12월에 태어난 선수들
select playerID
from salaries
group by playerID
having AVG(salary) >= 300000
intersect
--12월에 태어난 선수들의 playerID
select playerID
from players
where birthMonth = 12
order by playerID asc
;
--차집합
--커리어 평균 연봉이 3000000 이상이거나 (-) 12월에 태어난 선수들
select playerID
from salaries
group by playerID
having AVG(salary) >= 300000
except
--12월에 태어난 선수들의 playerID
select playerID
from players
where birthMonth = 12
order by playerID asc
;
현업 3D게임엔진 프로그래머가 전수해드리는 고농축 고퀄리티의 과외를 만나 보실 수 있습니다
※ 제대로 된 곳이 아닌 다른곳에서 어설프게 배웠거나 이해가 완벽하게 가지 않은 상태에서 계속 진행이 되어 시간과 비용만 낭비만 한채 또는 중도에 포기한 채 이곳을 찾아93%이상 분들이 원하는 결과를 얻고 가셨습니다 요행 길이라는 것은 없으며 제대로 된 곳에서 제대로된 진로를 고민해보시기 바랍니다.
타교육기관에서 한계를 느끼신 분 질문에 대한 답 : 여기 저기서 찾아도 무엇이 맞는지 모르겠는 분에게 정확한 답변을 드립니다
최근실적 : 넷마블 게임프로그래머 부문 1위로 입사 신입프로그래머를 1:1 교육하여 연봉 1600만원 인상 이직
노하우를 아낌없이 알려드리겠습니다
[ 이력 ]
넥슨, 크래프톤, NHN, 넷마블 다수 동종/타종 근무경험 및 다년간 현업 개발자
3D,2D게임 엔진,컨텐츠 프로그래머/ 언리얼4,5/네트워크 동기화 프로그래머/애니메이션 메인, 물리엔진개발/ 다수와 다양한 장르의 모바일, PC 게임개발/서버/Shader 등등의 개발 경험/ UE,Unity
현업 3D게임엔진 프로그래머가 전수해드리는 고농축 고퀄리티의 과외를 만나 보실 수 있습니다
※ 제대로 된 곳이 아닌 다른곳에서 어설프게 배웠거나 이해가 완벽하게 가지 않은 상태에서 계속 진행이 되어 시간과 비용만 낭비만 한채 또는 중도에 포기한 채 이곳을 찾아93%이상 분들이 원하는 결과를 얻고 가셨습니다 요행 길이라는 것은 없으며 제대로 된 곳에서 제대로된 진로를 고민해보시기 바랍니다.
타교육기관에서 한계를 느끼신 분 질문에 대한 답 : 여기 저기서 찾아도 무엇이 맞는지 모르겠는 분에게 정확한 답변을 드립니다
[ 이력 ]
넥슨, NHN, 넷마블 다수 동종/타종 근무경험 및 다년간 현업 개발자
3D게임 엔진 프로그래머/ 3D,2D 게임/ 언리얼엔진/ 엔진 프로그래머/ 메인 PC 게임 개발 / 모바일 게임/엔진 개발
Artificial Intelligence (AI) is one of the hottest topics in the tech industry today. With rapid advancements in machine learning, natural language processing, and computer vision, AI has the potential to revolutionize a wide range of industries, from healthcare and finance to retail and transportation.
The rise of AI has also sparked discussions about its ethical and societal implications. While AI has the potential to greatly improve our lives, it also raises important questions about privacy, security, and the impact on jobs. For example, some worry that widespread use of AI could lead to job loss and increased inequality.
Despite these concerns, the trend towards AI is undeniable, with companies investing heavily in developing and deploying AI technologies. In many industries, AI is already being used to automate manual processes, enhance customer experience, and make better-informed decisions.
One of the key challenges in the adoption of AI is the availability of skilled talent. There is a growing demand for data scientists, machine learning engineers, and AI experts who can develop and deploy AI solutions. This shortage of talent has led to increased competition for skilled workers and a growing need for education and training in AI.
Overall, the rise of AI is set to have a major impact on the tech industry and our lives. As we continue to explore the potential of AI, it is important to address the ethical and societal implications of this technology and ensure that it is used for the benefit of all.
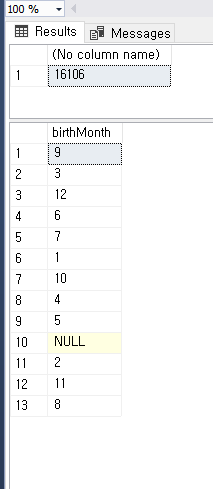
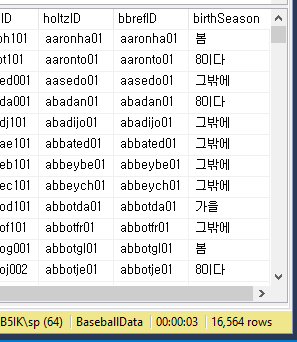
use BaseballData;
select birthMonth
from players;
select *,
case birthMonth
when 1 then N'겨울'
when 2 then N'봄'
when 3 then N'가을'
when 8 then N'8이다'
else N'그밖에'
end as birthSeason
from players;
switch case 와 비슷한걸 알 수 있다
위에서 end as birthSeason 끝에 새로 추가된 컬럼의 이름을 birthSeason 으로 지정하겠다는 얘기다
case 의 where 조건에 맞춰 문자로 변환되어 추가 된것을 볼 수 있다
아래 처럼 조건문을 추가 하는 구문 또한 있다
select *,
case
when birthMonth <=1 then N'back'
when birthMonth <=3 then N'나이스'
when birthMonth <=6 then N'앜'
when birthMonth <=9 then N'9이하'
when birthMonth <=12 then N'12이하'
else N'그밖에'
end as birthSeason
from players;
위 구문들에서 else 구문이 없다면 else 에 에 해당 하는것ㅇ느 birthSeason 에서 NULL 이 된다
주의 할점 birthMonth = NULL 이렇게 조건문을 쓸 수 없고 birthMont is NULL 이렇게 비교를 해야한다
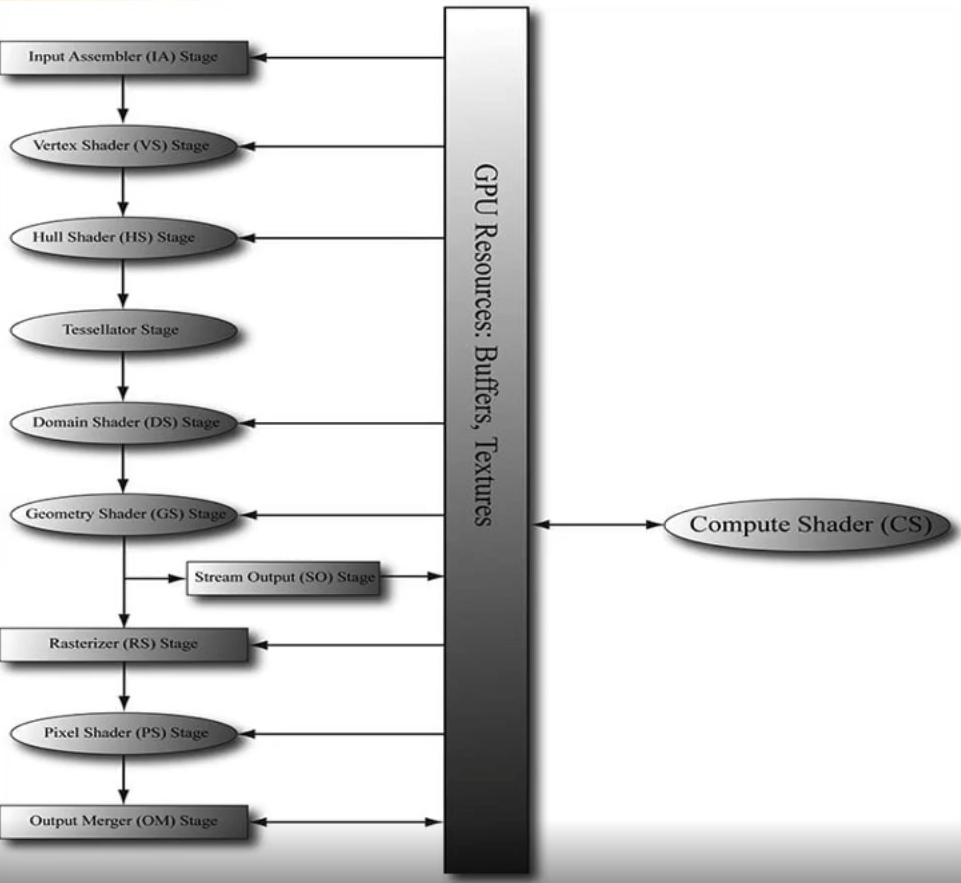
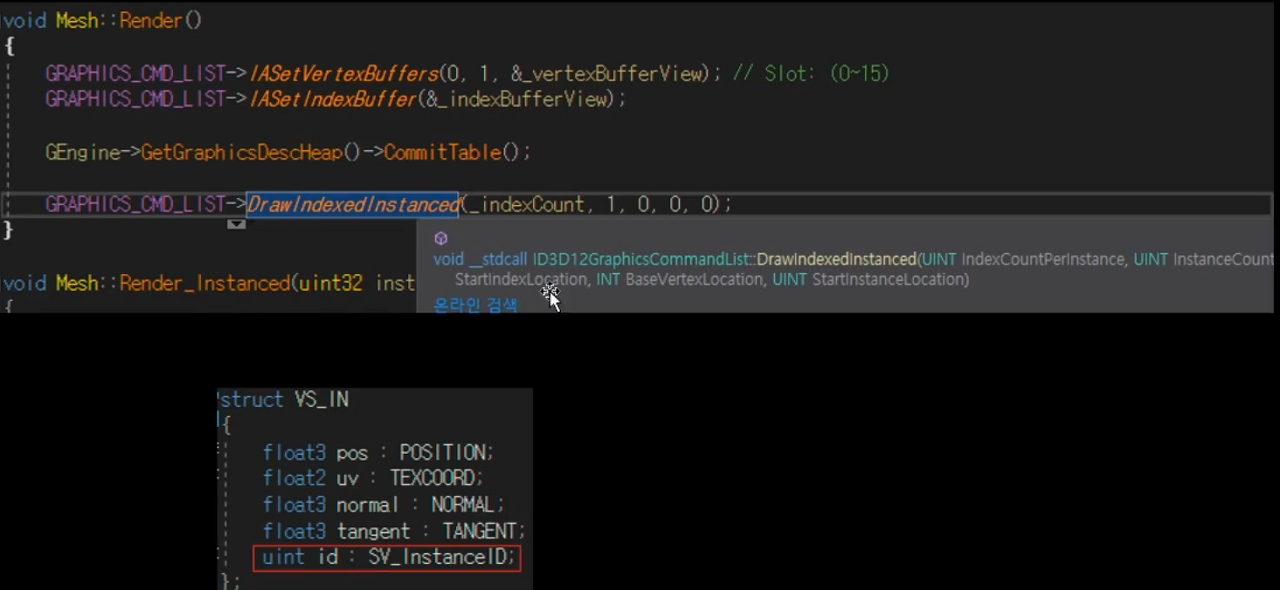
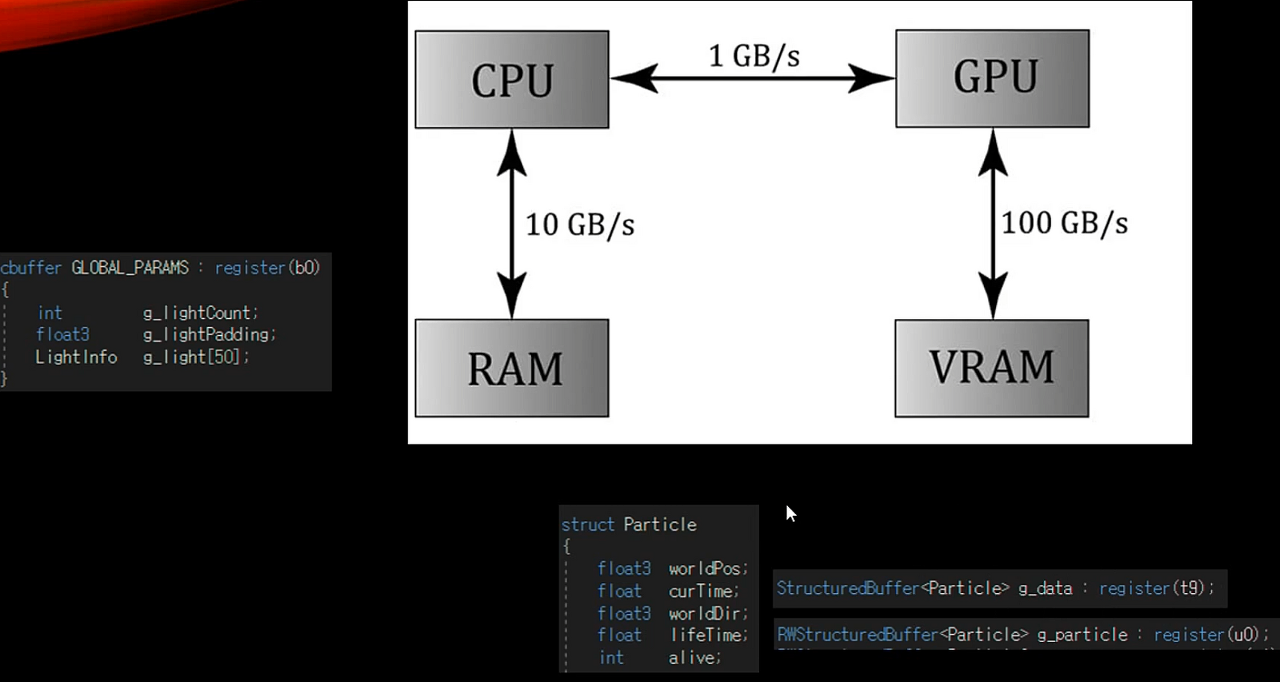
인스턴싱 개수만큰 파이프라인에서 정점셰이더이후의 과정을 개수만큼 반복하게 되어 cpu 에서 gpu 로의 전송 과정을 아낄 수 있다
각 인스턴싱된 오브젝트들은 SV_InstanceID 로 구분할 수 있다
파티클들의 위치나 방향을 cpu 에서 gpu 로 넘겨주는게 아니라 gpu 내부에서 SturcturedBuffer 를gpu 쪽에 만들어 놓으면 gpu 내에서 현재 파티클의 정보를 g_data 에 넣고 이것에 대한 움직이는 정보를 RWStructuredBuffer 에다가 기록을 하여 파티클을 움직이도록 처리 할수 있다, GPU 내에서.
[t9 는 t 는 텍스처 같은 형태로 자료의 크기가 상수버퍼 처럼 정해져 있지 않는 것을 사용한다는 것 또한 알 수 있다]
그리고 물체들의 위치는 이전 단계인 Compute Shader 에서 위치를 먼저 계산해 놓게 된다
그려질 필요가 없다면 지오메트리 셰이더에서 파티클을 그리지 않는다
GS 는 도형 정보를 수정 할수 있따, 추가 및 제거
최적화를 위해 정점 하나만 받아서 정점이 살아 있지 않다면 정점을 더이상(메시를) 그리지 않는다 그려질 필요가 없다면 모든 정점을 받을 필요가 없기 때문
outputSteam 은 정점을 생성 할거라면 이곳에 정점들을 추가해 이 정점에 대한 메시를 그리게 된다
즉 outputSteam 이것이 비어져 넘겨지게 되면 아무것도 그리지 않는다는것
VIew space 주석이 있는 곳이 정점을 뷰시점에서 사각형을 만들어 outputSteam 에 추가해 사각형을 만들고 있다는 것을 알 수 있다
이렇게 처리하면 CPU 와 GPU 의 병복 현상을 많이 줄일 수 있어서 성능향상이 될 수있다
전체적인 순서를 컴퓨트 셰이더를 통하여 위치나 방향 생명주기를 먼저 계산한다음 이 정보를 GPU 배열에 저장해 놓고
USE [BaseballData]
GO
INSERT INTO [dbo].[DateTimeTest]
([time])
VALUES
--('20090909')
(CURRENT_TIMESTAMP)
GO
use BaseballData;
SELECT *
FROM DateTimeTest;
-- 은 주석이다
SELECT *
FROM DateTimeTest;
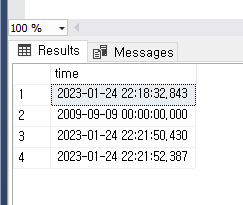
몇번 추가한 모습
조건식으로 비교할때 다음 처럼 할 수 있다 두개의 결과는 같다
use BaseballData;
SELECT *
FROM DateTimeTest
where time >= CAST('20200101' as DATETIME);
SELECT *
FROM DateTimeTest
where time >= '20200101';