
원래 데이터는 이렇게 있는데
2004년 도에 가장 많은 홈런을 날린 팀은?
select teamID, sum(HR) as homeRuns
from batting
where yearID=2004
group by teamID
order by homeRuns desc;
group by 는 공통된 것을 하나의 단위로 묶는 것인데
이 묶음으로 하나로 보려 하는 것이 group by 라서
group by 한 것을 select * 할 수는 없다
즉 group 된 것의 정보에서 뭔가 SUM 이나 계량적인 데이터를 종합해 보려고 할때 유용하다

2004년 도에 가장 많은 홈런을 날린 팀은?
select teamID, sum(HR) as homeRuns
from batting
where yearID=2004
group by teamID
having SUM(HR) >= 200
order by homeRuns desc;
여기서 having 을 볼 수 있는데 having 은 group by 다음에 조건을 걸 수 있는 키워드 이다
group 으로 묶은 목록들 중에서 다시 조건을 걸기 위해선 where 로는 충족되지 못하기 때문에 하나 더 있다고 볼 수 있다
명령문은 다음 순서대로 실행 되기 때문에 select 를 가장 최상단에 쓰는 쿼리 문에서는 select 다음에 오는 컬럼명에 올 수 있는 것인지에 대한 판단은 아래 순서를 고려해야 한다 (as 별칭 포함)
- from
- where
- group by
- having
- select
- order by
단일년도에 가장 많은 홈런을 날린 팀은?
select teamID, sum(HR) as homeRuns
from batting
group by teamID
order by homeRuns desc;

이렇게 볼 수 잇는데 이때는 같은 팀은 맞는데 연도가 섞여 있으면서 각 연도별에 대한 홈런을 모두 합한 것이 됨으로
만약 위 상황에서 같은 팀에서도 연도별 분류 한다면?
select teamID, yearID, sum(HR) as homeRuns
from batting
group by teamID, yearID
order by homeRuns desc;같은 팀에서도 단일 연도로 분류하여 구 할 수 있다
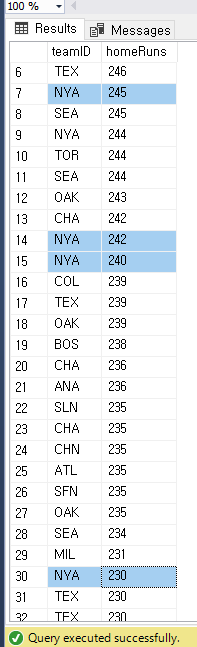
NYA 에 대한 결과는 하단에 더 있지만 생략..
반응형
'서버(Server) > DB' 카테고리의 다른 글
| DB : subquery (0) | 2023.02.04 |
|---|---|
| DB : Insert into , Delete, Update (0) | 2023.02.03 |
| DB : COUNT, DISTINCT 각종 함수들 (0) | 2023.02.01 |
| DB : Case, where (0) | 2023.01.31 |
| DB : 날짜와 관련된 기능들 GETUTCDATE() (0) | 2023.01.30 |