
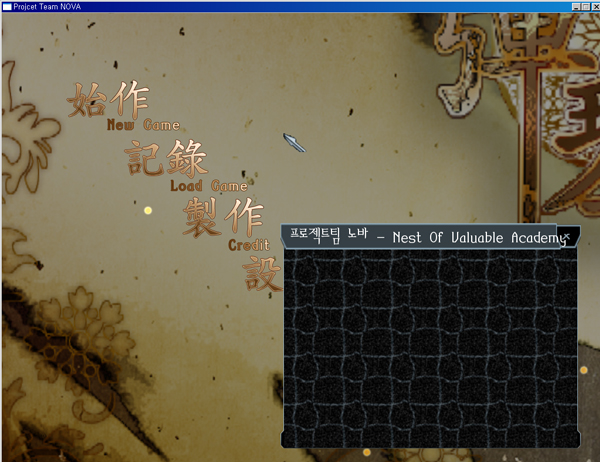
폰트가 정말 깔끔하게 나온다. 맘에 들어 꺄악.
CEGUI포럼을 검색하다 보니 중국어 출력 관련 질문이 있었는데 그 부분을 참고 했다.
원문 : http://www.cegui.org.uk/phpBB2/viewtopic.php?t=2503&highlight=language
1. 한글폰트를 포함하는 .font를 만들고 그것을 FontManager로 로드합니다.
폰트 정보를 로드한 후 폰트의 이름을 기본 폰트로 설정해 줍니다. 여기에서 한 가지 팁은 CEGUI에서 한글 폰트를 사용하면 폰트를 비트맵으로 변환하여 읽어들인다는 것입니다. 비트맵으로 변환하는 과정에서 폰트의 사이즈가 크거나, 한자를 포함하여 폰트자체의 용량이 크게되면 안된다는 것입니다. 한자를 포함하는 폰트를 사용하게 되면 폰트를 비트맵으로 변환하는 과정에서 데드락이 걸린다고 하는군요. 실질적으로 소스를 살펴보겠습니다.
- .font
<?xml version="1.0"?>
<Font Name="Tahoma-12" Filename="HMKMAMI.TTF" Type="FreeType" Size="24" NativeHorzRes="1024" NativeVertRes="768" AutoScaled="true" AntiAlias="true"/>
- .cpp
CEGUI::FontManager::getSingleton().createFont ("Tahoma-12.font");
CEGUI::System &sys = CEGUI::System::getSingleton();
sys.setDefaultFont((CEGUI::utf8*)"Tahoma-12");
2. 소스를 살펴보면 출력할 폰트를 UTF8로 변환하는 코드를 볼 수 있다.
std::wstring szWstring(L"노바 - Nest Of Valuable Academy");
char *szUtf8String = NULL;
int iLengthAnsiString = 0;
iLengthAnsiString = WideCharToMultiByte(CP_UTF8, 0,szWstring.c_str(), szWstring.capacity(), NULL, 0, NULL, NULL);
szUtf8String = new char[ iLengthAnsiString];
memset(szUtf8String, 0, sizeof(char)*(iLengthAnsiString));
WideCharToMultiByte(CP_UTF8, 0,szWstring.c_str(), szWstring.length(), szUtf8String, iLengthAnsiString, NULL, NULL);
wnd->setText((CEGUI::utf8*)szUtf8String);
delete [] szUtf8String;
szUtf8String = NULL;
위의 코드처럼 unicode -> UTF8로 변환하는 작업을 거쳐야 한글 출력이 가능합니다.
3. 2007년 10월 19일 추가작성
위의 코드는 수 많은 UI를 코드에 단다고 했을 때 범용성이라고는 누꼽만큼도 없는 코드입니다. 단지 한글 출력이 가능하다라는 정도의 소스가 되겠습니다. 그래서 필요한 것은 시스템인코딩된 멀티바이트를 UTF8로 인코딩을 시키는 코드를 작성해야 합니다. 그런데! (시스템인코딩)멀티바이트 -> (UTF8)멀티바이트로 변환을 시키는 함수가 없기 때문에 멀티바이트->유니코드->멀티바이트로 변환 과정을 거쳐 UTF8로 변환 시켜야 합니다.
이번 작업으로 한글변환에 대한 기본지식은 어느정도 생긴것 같습니다. widechar가 유니코드. multybyte가 완성형 그러니깐 일반적인 char형 변수. UTF8은 char형이나 UTF8인코딩 변환 과정을 거친다는 것입니다.
멀티바이트 문자열의 길이는 strlen()함수를 통해 알 수 있고 유니코드는 lstrlen()함수를 통해 알 수 있습니다. 하루 동안 삽질 하면서 정말 많은 문서를 봤지만 기억에 남는건..그닥없습니다.ㅎ
그냥 두서 없이 함수 구현부만 적어 놓겠습니다.
char* CEGUIApplication::ANSI_TO_UTF8(char *szANSI)
{
int nLen = MultiByteToWideChar(CP_ACP, 0, szANSI, -1, NULL, NULL);
LPWSTR lpwsz = new WCHAR[nLen];
MultiByteToWideChar(CP_ACP, 0, szANSI, -1, lpwsz, nLen);
int nLen1 = WideCharToMultiByte(CP_UTF8, 0, lpwsz, nLen, NULL, NULL, NULL, NULL);
LPSTR lpsz = new CHAR[nLen1];
WideCharToMultiByte(CP_UTF8, 0, lpwsz, nLen, lpsz, nLen1, NULL, NULL);
delete []lpwsz;
return lpsz;
}
이런식으로 해 놓고!
CEGUI에서의 사용은 아래와 같이 하면 되겠습니다.
wnd->setText((CEGUI::utf8*)ANSI_TO_UTF8("윤경옥-NOVA"));
궂이 UTF8로 변환을 시켜주는 이유는 CEGUI::String형이 UTF8로 인코딩 되어 있기 때문입니다.
2003버젼에서는 이런 변환 과정이 필요없지만 2005는 프로그램의 버그로 보이는 문제 때문에 UTF8로 인코딩을 해도 한글 출력이 잘 되지 않는다고 하는군요. 이런 공개용 라이브러리를 공부 하는데 가장 좋은 방법은 외국 사이트의 포럼을 통해서가 가장 효과적인 것 같습니다.
짧은 프로그래머 생활 이었지만 코딩을 할 때마다 뼈저리게 느끼는건 하늘 아래 새로운 것이 없다는 말 처럼 내가 지금 겪고 있는 문제를 과거에 누군가는 반드시 겪었었고, 앞으로도 반드시 겪게 될거라는 것입니다. 이런 논리속에서 프로그래머에게 필요한 기술의 하나가 정보수집 능력에 있는것 같습니다.
멀티바이트를 유니코드로 바꾸고 유니코드를 UTF8로 바꾸는것은
inline
std::wstring convMbcs2Uni(const std::string &mstr)
{
USES_CONVERSION;
std::wstring wstr(A2W(mstr.c_str()));
return wstr;
}
inline
std::string convUni2Utf8(const std::wstring &wstr)
{
USES_UTF8_CONVERSION;
std::string ustr(W2A(wstr.c_str()));
return ustr;
}
#define CONV_MBCS_UTF8(a) convUni2Utf8(convMbcs2Uni(a)).c_str()
이런식으로 할수도 있더군요
'프로그래밍(Programming) > GUI' 카테고리의 다른 글
| Win32 콘솔 응용 프로그램 및 CLR 설정 (0) | 2013.01.06 |
|---|---|
| CEGUI 사용시 GUI를 제외한 렌더링화면이 나오지 않거나 이상하게 렌더링될때 (0) | 2012.12.06 |
| CEGUI 그냥 사용하기엔 정말 무겁습니다 (0) | 2012.12.02 |
| CEGUI 한글설정 (0) | 2012.12.02 |
| CEGUI 메모리 해제(릴리즈) (0) | 2012.11.27 |