
Clustered 는 Leaf Page 에 데이터가 들어가고 이전까지 보던 방식
Non-Clustered 같은 경우는 RID 를 통해 한번 경유하여 데이터를 저장하는 방식이다
Clustered 영한사전 , Non-Clustered 색인
Clustered : 실제로 논리적으로 정렬 되는 데이터 순서가 키 값 정렬 순서가 된다
Leaf Page = Data Page 끝 노드에 실제 데이터가 들어가는 형태
데이터는 clustered index 키 순서로 정렬
Non-Clustered 는 clustered index 유무에 따라서 다르게 동작한다
- Non-Clustered 인데 clustered index 가 없는 경우(추가 안한 경우)
leaf page 에는 heap table 에 대한 heap rid가 존재하여 이 rid 로 -> Heap table 에 접근 데이터 얻어온다
> heap rid = Heap table 에서 어느 주소에 몇번째 슬롯에 데이터가 있는지를 알 수 있는 RID
> 데이터는 heap table 이 있고 이곳에 데이터들이 저장된다
(즉 leaf Page 가 인덱스 페이지가 아니고 데이터 페이지가 아니라는 얘기) - Non-Clustered 가 키가 있는데 이때 clustered index 를 추가 하게 되면
heap table 이 없고 leaf page 에 데이터가 있는 상태이다 => leaf table 에 실제 데이터가 있게된다
> heap table 이 없는 대신에 Clustered Index 의 실제 데이터 키 값을 들고 있게 된다, 이 키 값을 통해 cluster page 에서 데이터를 찾게 된다
> Non clustered 에서 먼저 트리를 통해서 자식 중에서 cluster id에 를 찾고 이 id를 통해 cluster index 가 이루고 있는 트리 부모로 가서 여기서 다시 id 를 찾는 형태가 된다
Non-Clustered 가 기존에 있을때 clustered index 를 추가 하면 기존에 Non-Clustered 도 영향을 주어 한단계 더 찾게 된다
기존 테이블을 지우고 테이블을 새로 하나 만든 다음
non clustered index 를 생성 하여 테스트
select *
into TestORderDetails
from [Order Details];
select *
from TestORderDetails;
--non clustered index 를 생성
create index Index_OrderDetails
ON TestOrderDetails(orderID, ProductID);
--TestORderDetails 테이블에 있는 인덱스 정보 보기
exec sp_helpindex 'TestORderDetails';
TestORderDetails 테이블에 있는 인덱스 정보는 다음과 같다는걸 알 수 있다

인덱스 번호를 찾아 보려면 다음 처럼 작성하면 된다
sys.indexes 에서 오브젝트 id 를 비교하여 TestORderDetails 오브젝트 id 롸 같은 오브젝트의 index_id 들을 가져올 수 있다
select index_id, name
from sys.indexes
where object_id = object_id('TestORderDetails');
TestORderDetails 의 index_id 는 2 번이고 2 번으로 인덱스를 담고 있는 인덱스 페이지들을 볼 수 있다
--Index_OrderDetails Index_id 가 2 임으로 2를 인저로 넣어 페이지들을 보기
DBCC IND('Northwind', 'TestORderDetails', 2);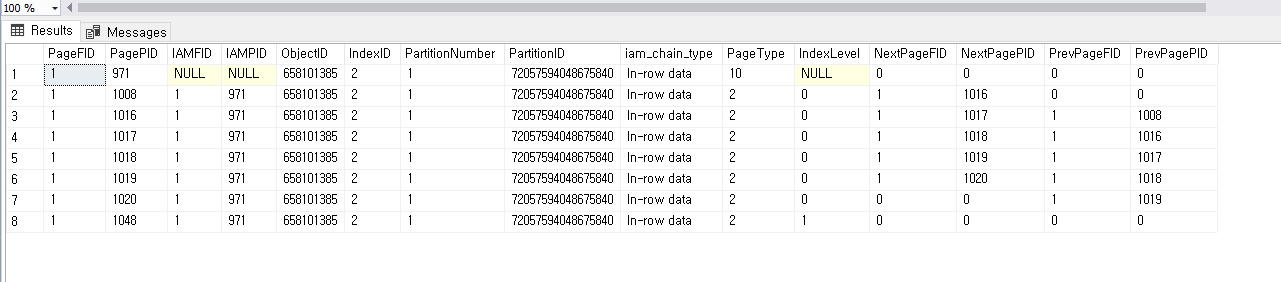
1048 이 root 고 나머지가 자식으로 들어간 걸 indexLevel 을 통해 알 수 있다
1048
1008 1016 1017 1018 1019 1020
이 중에서 1008 페이지 정보를 보면
--페이지 정보 보기
DBCC PAGE('Northwind', 1 , 1008, 3);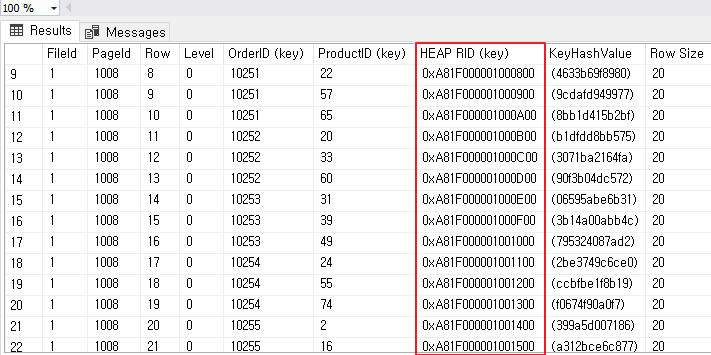
이 처럼 HEAP RID 가 있는 것을 알 수 있다 (index 를 non clustered index 로 생성했기 때문)
Heap RID = ([페이지 주소(4)[파일ID(2)[슬롯(2)] ROW) 의 바이트들로 구성 되는데이 ID 를 통해 Heap Table 테이블에서
Heap Table = [{page} {page} {page} {page}]
몇번째 페이지 몇번 슬롯으로 되어 있는지를 Heap RID가 가리키고 있기 때문에
1008 에서 Heap RID 를 통해서 Heap Table 에 있는 데이터를 바로 검색해 찾을 수 있게 된다
DBCC 로 페이지 정보를 볼때 나오는 PageType 은
- 1 : Data Page
- 2 : Index Page
를 나타낸다

현재 까지 상황은
NonClusted Index 가 추가 된 상황이고 여기서 Clustered index 를 추가 해보면
-- clustered index 추가
create clustered index Index_OrderDetails_Clustered
ON TestOrderDetails(orderID);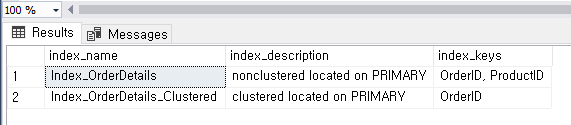
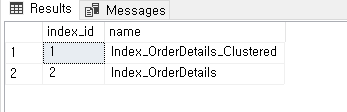
이렇게 추가 된것을 볼 수 있다
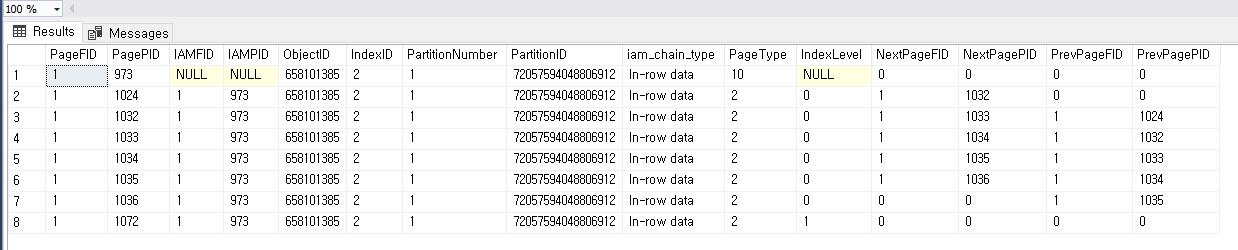
이때 다시 2번 Non Clustered index 를 살펴보면 어떻게 달라져는지를 보면
cluster index 추가 하기 전 |
cluster index 추가 한후 |
페이지 번호가 바뀐 것을 알 수 있다
기존에는
1048
1008 1016 1017 1018 1019 1020
이런 번호였지만
1024 부터 자식이 시작 하는 걸 알 수 있는데 clustered index 를 추가 하게 되면
1072
1024 1032 1033 1034 1035 1036
로 바뀌었다, 이때 1024 페이지 정보를 보면
--페이지 정보 보기
DBCC PAGE('Northwind', 1 , 1024, 3);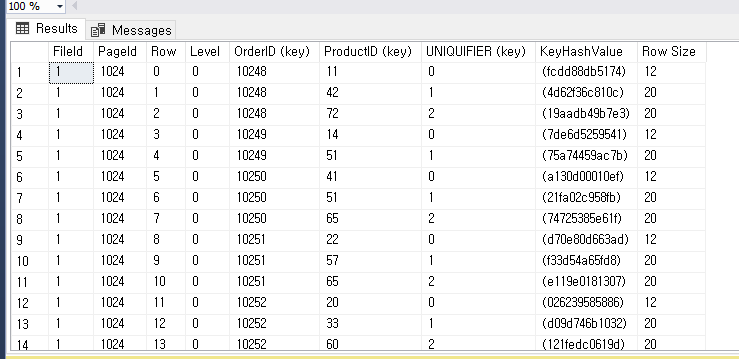
원래는 Heap Rid 가 기존엔 있었지만 clustered index 를 추가하여 Heap Rid 가 없어진 것을 알 수 있다
그리고 페이지 id 가 전과 후가 달라진 것도 이전엔 Heap Rid로 heap table 을 찾는 형식이였지만
이젠 직접적으로 찾게 되니 PagePid 또한 달라지게 된 것
clustered index 를 생성할때 OrderID 에 대해 만들었는데
중복된 OrderID 를 볼 수 있는데 이것은 같은데이터에 한하여 동일한 ID 가 붙는 것이고 동일한 데이터를 구분하기 위하여
UNIQUIFIER 필드가 추가 되어 이들을 구분하게 끔 되어 있다
OrderID + UNIQUIFIER 조합으로 식별한다
정리하자면 Non clustered index 에서 Clustered index 를 추가 하면 기존 Heap RID 가 날라가게 된다는 것이다
위에서 본건 Non clusteered 인덱스 가 있었던건 본것이였는데
이번엔 그에 반해 위에서 새로 추가 했던 clustered 를 보면
--TestORderDetails 테이블에 있는 Index_id 보기
select index_id, name
from sys.indexes
where object_id = object_id('TestORderDetails');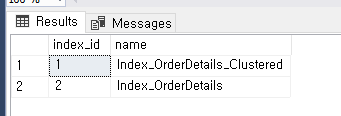
테이블에 있는 인덱스 중에서 인덱스 1번은 검색
--Index_OrderDetails Index_id 가 2 임으로 2를 인저로 넣어 페이지들을 보기
DBCC IND('Northwind', 'TestORderDetails', 1);
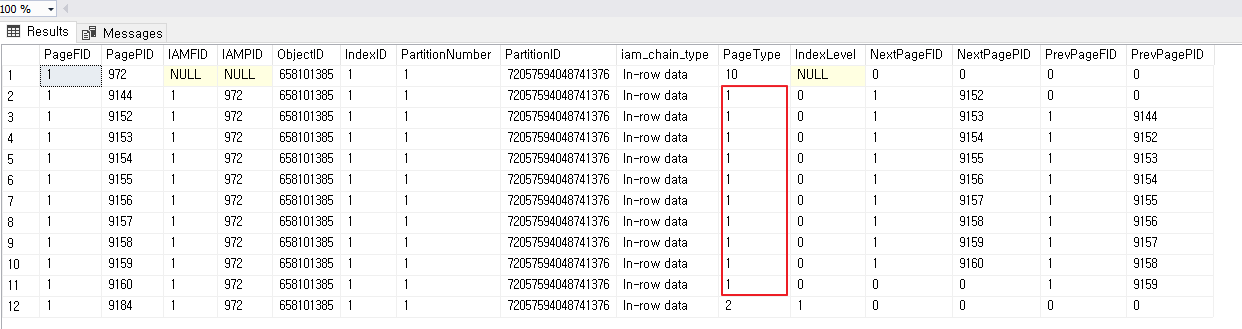
9184
9144 9152 9153 9154 9155 9156 9157 9158 9159 9160
이렇게 구성 되어 있다 즉 여기서 알수 있는건
DBCC 로 페이지 정보를 볼때 나오는 PageType 은
- 1 : Data Page
- 2 : Index Page
였기 때문에 PageType 을 보면 PagePID 가 갖고 있는것이 바로 데이터 페이지가 된다는 걸 알수 있다
정리하자면
- Clustered index 있으면 leaf page 가 바로 데이터가 되는것이고, Heap Table 또한 없다
- Clustered index 가 없다면 Heap RID로 Heap Table 을 검색해서 데이터를 찾는 한번 경유하는 형태가 된다는 것이다
이때는 Heap Table 또한 생성되게 된다
'서버(Server) > DB' 카테고리의 다른 글
| [DB] 쓰기와 읽기, 스래드와 캐시 & 대기와 락, 트랜잭션 (0) | 2023.04.03 |
|---|---|
| [MSSQL] 예상 실행계획 (0) | 2023.04.02 |
| DB : 복합 인덱스 (0) | 2023.03.02 |
| DB : INDEX (0) | 2023.03.01 |
| DB : 윈도우함수 (0) | 2023.02.28 |