
테이블과 데이터들을 추가한다
USE Northwind;
--db 정보 보기
EXEC sp_helpdb 'Northwind';
create table Test
(
EmployeeID INT NOT NULL,
LastName NVARCHAR(20) NULL,
FirstName NVARCHAR(20) NULL,
HireDate DATETIME NULL,
);
SELECT *
FROM Test;
--Employees 데이터를 Test 에 추가한다
INSERT INTO Test
SELECT EmployeeID, LastName, FirstName, HireDate
FROM Employees;RESULT

--index 를 걸 컬럼= LastName
--FILLFACTOR 리프 페이지 공간 1%만 사용 , 전체 사용 공간 중에 1%만 사용 하겠다는 것, 이러면 데이터가 다 안들어가기 때문에 별도 트리구조로 데이터를 저장함
--PAD_INDEX (FILFACTOR 가 중간 페이지에도 적용되게 하는 것) => 결과적으로 공간을 비효율적으로 사용하게끔 하는 것인데 목적이 테스트 하는 것임
CREATE INDEX Test_Index ON Test(LastName)
WITH (FILLFACTOR = 1, PAD_INDEX = ON)
--인덱스가 만들어진 sys.indexes 에서 index_id와 name 을 출력하는데 조건이
--Test 에 만든 인덱스 id 와 같은것만 출력한다
SELECT index_id, name
FROM sys.indexes
WHERE object_id = object_id('Test');
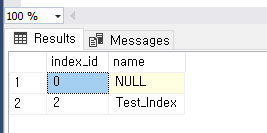
결과 화면은 이런데 여기서 인덱스 Test_Index 를 조사해보면
--2번 인덱스 정보 살펴보기
DBCC IND('Northwind','Test', 2);
빨간색 박스의 IndexLevel 이
가장 높은 숫자가 트리의 Root 이고
2 -> 1 -> 0
순으로 자식을 이루고 있는 인덱스 트리를 생각 하면 된다
2 가 가장 상단 그다음에 1에 해당 하는 것이 PagePID 보면 1008, 984 두개가 있는데
이 중에서 NextPagePID 를 1 레벨에서 다음을 말하는 것이 984 라고 나와 있는 것
즉 순서가 985 -> 1008 -> 984 로 되어 있다는 것을 알 수 있다
트리 형태로 보면 가장 상단 레벨 1에 1개 2 레벨에 2개 3 레벨에 3개의 노드가 있다고 생각하면 된다
그런데 각 노드는 페이지들인데 이 정보들 또한 볼 수 있다
끝단 3개의 노드를 출력해보면
--1 파일번호, 968 페이지 번호, 3 출력 옵션
DBCC PAGE('Northwind',1, 968, 3);
DBCC PAGE('Northwind',1, 976, 3);
DBCC PAGE('Northwind',1, 977, 3);

위 처럼 되고
원래 추가된 9개 와 비교해보면 3개씩 나뉘어져 들어가 있는 것을 알 수 있다
HEAP RID 라는 걸 볼 수 있는데
HEAP RID = 페이지주소(4바이트) , 파일 ID(2), 슬롯번호(2), 로 조합된 8바이트 ROW 식별자이고 이걸로
테이블에서 정보를 추출한다
TABLE [{PAGE} {PAGE} {PAGE} ....] 여기서 찾는 형태이다
RANDOM ACCESS (한건을 읽기 위해 한 페이지씩 접근 하는것 으로 트리 위에서 부터 아래로 노드를 찾아가는 과정)
BOOKMARK LOOKUP : 노드를 찾은다음 RID를 통해 행을 실제 TABLE 에서 찾는 것을 말함
반응형
'서버(Server) > DB' 카테고리의 다른 글
| Clustered(바로 찾기), Non-Clustered (경유해서 찾기) (0) | 2023.03.03 |
|---|---|
| DB : 복합 인덱스 (0) | 2023.03.02 |
| DB : 윈도우함수 (0) | 2023.02.28 |
| Northwind and pubs sample databases for Microsoft SQL Server (0) | 2023.02.23 |
| DB : 테이블을 변수에, IF 문, WHILE 문, BREAK , CONTINUE (0) | 2023.02.20 |