
use Northwind;
SELECT *
FROM [Order Details]
ORDER BY OrderID;
select *
into TestORderDetails
from [Order Details];
select *
from TestORderDetails;
--복합 인덱스 추가
create index Index_TestOrderDetails
ON TestOrderDetails(orderID, ProductID);
--인덱스 정보 보기
exec sp_helpindex 'TestORderDetails';
--Index Seek 이건 인덱스를 활용해 빨리 찾는 것인데
--Index Scan 은 Index Full Scan 으로 전체 다 찾는 거라 느리다
--아래 처럼 and 를 쓰면서 인덱스통하여 검색을 하면 Index Seek 가 일어난 다는 걸 알 수 있다
select *
from TestORderDetails
where OrderID = 10248 and ProductID = 11;
--index seek 으로 검색
select *
from TestORderDetails
where OrderID = 10248;
--table scan 으로 찾음
--이유는 ON TestOrderDetails(orderID, ProductID) 이렇게 생성했을대 orderID 가 첫번째에 있었기 때문에
--orderID 로 찾기를 시작할땐 index seek 로 1차적으로 찾는데
--그렇지 않으면 ProductID 로 찾게 되면 2차적으로 정렬하여 table scan 으로 찾게 된다
select *
from TestORderDetails
where ProductID = 10248;
--index 정보 보기
DBCC IND('Northwind', 'TestORderDetails', 2);
DBCC PAGE('Northwind', 1 , 9160, 3);
복합 인덱스를 두개에대해 추가(orderID, ProductID) 했다
create index Index_TestOrderDetails
ON TestOrderDetails(orderID, ProductID);
이렇게 하면 데이터를 찾을때 성능에 대한 차이가 발생 하는 이유는 데이터를 정렬 하는데 있어서 차이가 있어서 그런것인데 인덱스가 두개라서 어떻게 검색에 대한 처리를 하는지 보면
--index 정보 보기
DBCC IND('Northwind', 'TestORderDetails', 2);
9200이 가장 상단이고 나머지는 모두 자식 즉 Leaf 노드 인 것을 알 수 있다(IndexLevel 이 0 임으로)
Leaf 노드의 순서가 트리상 동일한 레벨에서 9168 -> 9169 -> 9170-> 이런 순으로 나가기 때문에
9160에 대한 노드 정보를 보면
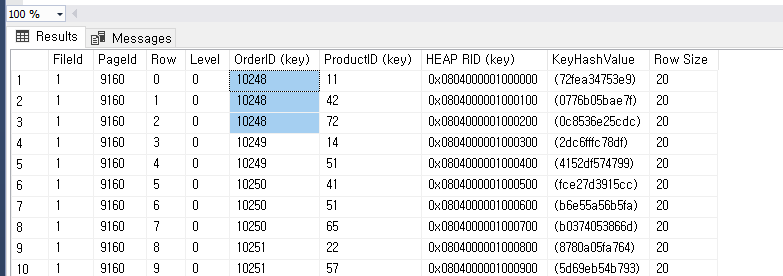
OrderID 와 ProductID 두개를 보면 우선 OrderID 로 정렬을 하는데 만약 같은 ID 라면 그다음 ProductID로 비교하는 걸 알 수있다
OrderID 는 정렬이 되어 있는 반면 ProductID 는 첫번째 것을 기준으로 정렬 되어 있어서
바로 ProductID로 찾으려 하면 정렬이 안되어 있는것과 마찬가지 임으로
ProductID 로 검색 기준을 삼으면 Scan 이 되는 것 => 느림
인덱스(A, B) 를 글었다면 인덱스 A 에 대해 따로 인덱스를 걸어줄 필요는 없는데
B로도 검색이 필요하다면 인덱스(B) 에 대해 별도로 걸어줘야 빨라지게 된다
주의 : A,B 둘다 인덱스가 독립적으로 걸려있는게 아니다
페이지 분할(SPLIT) : 정리하면 인덱스를 생성하면 원소들이 페이지 단위로 관리 되는데 이 페이지 단위마다 관리 개수를 넘어가면 추가 페이지를 만들어 원소들을 관리하는 구조가 된다
데이터 50개 강제로 추가 해보면
인덱스 데이터 추가 /갱신/ 삭제시 그 중에서 추가 하는 경우를 보자
DECLARE @i INT = 0;
WHILE @i < 50
BEGIN
INSERT INTO TestORderDetails
VALUES (10248, 100 + @i, 10, 1, 0);
SET @i = @i +1;
END
이렇게 하면 추가 페이지가 만들어지는데 그 이유는 한 페이지에 내용이 너무 많아 지면 기존 페이지에 있던 요소 를 두개,세개 로 분할하여 담기 때문이 새로 페이지가 추가된것을 알 수 있고 이것을 페이지 Split 이라 한다
주의 : 인덱스를 Name 에 대해 걸어 놓았을때 SUBSTRING(NAME,1 ,2) 을 하게 되면 인덱스를 사용하는 최적화 사용이 불가능함으로 Index Scan 을 하게 되는 경우가 발생할 수 있다
SUBSTRING 으로 문자를 일부 가져와 어떤 문자를 찾는 것이 아닌
WHERE Name LIKE 'Ba%' ; 식으로 찾으면 Name 에 대해 최적화를 적용 받을 수 있다
실행 할때 Ctrl + L 로 Index Seek 인디 Index Scan 인지 확인하는 것이 좋다
'서버(Server) > DB' 카테고리의 다른 글
| [MSSQL] 예상 실행계획 (0) | 2023.04.02 |
|---|---|
| Clustered(바로 찾기), Non-Clustered (경유해서 찾기) (0) | 2023.03.03 |
| DB : INDEX (0) | 2023.03.01 |
| DB : 윈도우함수 (0) | 2023.02.28 |
| Northwind and pubs sample databases for Microsoft SQL Server (0) | 2023.02.23 |