

안녕하세요. 삼성 소프트웨어 강남 멤버십 19-1기이자, 엘리트 멤버 2기 김주영 입니다. 지난 시간에 이어 이번에는 유전알고리즘을 활용한 순회 세일즈맨 문제(Traveling Salesperson Problem : TSP)의 해결을 포스팅하려 합니다.
1. 순회 세일즈맨 문제란?
먼저 위키피디아의 글을 첨부하여 순회 세일즈맨 문제를 소개하고자 합니다.
“여러 도시들이 있고 한 도시에서 다른 도시로 이동하는 비용이 모두 주어졌을 때, 모든 도시들을 단 한 번만 방문하고 원래 시작점으로 돌아오는 최소 비용의 이동 순서는 무엇인가? 그래프 이론의 용어로 엄밀하게 정의한다면, ‘각 변에 가중치가 주어진 완전 그래프(weighted complete graph)에서 가장 작은 가중치를 가지는 해밀톤 회로(Hamiltonian cycle)을 구하라’ 라고 표현할 수 있다.” - Wikipedia <외판원 문제 中>
위의 설명에서 보듯이 N개의 도시가 있을 때 어떤 경로로 도시들을 순회하는 것이 최적화된 경로일까를 고민하는 문제입니다. 아래 사진과 같이 5개의 도시가 있는 경우 5도시의 번호 조합으로 최적화를 수행하게 됩니다. 예를 들어 1-2-3-4-5 순서로 방문할 수도 있고, 4-3-1-2-5 처럼 얼핏 보기에도 길게 돌아가는 듯한 경로로 문제를 해결할 수도 있습니다.

위와 같은 조합최적화에서 경우의 수는 N! (5! = 5*4*3*2*1) 에 해당하여, 도시의 수 N이 커질수록 계산 량이 기하급수적으로 증가하게 됩니다. 잠깐 살펴보자면 도시의 개수가 5개인 경우에야 120가지의 경우의 수를 모두 계산해서 최적의 해를 구하면 그만이지만, 한국에 있는 시 단위의 행정구역만 세어도 84개입니다. 각 도시의 최적 순회 경로를 판단하기 위한 84!는 3.3142401345653532669993875791301e+126입니다. 3으로 시작하는 126자리의 수네요.. 1000개의 조합을 1초내로 계산할 수 있는 컴퓨터를 사용하더라도 3.3142401345653532669993875791301e+123초의 수행시간이 필요합니다...
최소값을 구하기 위한 모든 경우의 수를 고려하는 방법은 포기하고, 유전자 알고리즘을 이용하여 근사값을 구할 수 있도록 해봅시다!
2. 유전 알고리즘 설계
a. 유전자 설계
각 해는 도시의 순회 경로를 표현하도록 합니다. 5개의 도시 문제에서 사용할 유전자의 모양은 12345,23541,13245 등이 될 것입니다. 12345는 도시를 1->2->3->4->5 순으로 순회하는 해를 뜻합니다. 앞으로 코딩할 예제에서는 40개의 도시를 이용할 예정이니, 유전자의 길이는 40개가 되겠죠!
b. 적합도 함수 (Fitness Function)
적합도 함수를 계산하기 위해 각 도시별 이동비용을 계산하기 위해 40개의 도시에 단순히 2차원 좌표값을 지정해, 각 도시의 거리로 비용을 계산하려고 합니다. 각 도시는 Matlab 예제에서 지원하는 미국 지도 내의 임의의 점으로 표현을 하고, 각 도시의 위치는 해당 점의 위치로 표현을 하고자 합니다.
c. 선택 방법
선택 방법은 이전 포스팅에 사용했었던 룰렛 휠 방법을 그대로 사용하도록 합니다! 다만 달라진 것은 이전의 룰렛휠 기반은 적합도의 높고 낮은 비중에 따라 선택압이 높고 낮게 결정되었다면, 이번 포스팅의 예제는 해의 순위에 따라 선택압이 조절된다는 점입니다.
d. 교차 방법
두 해의 교차의 경우에는 꽤 복잡하게 진행됩니다. 이전의 유전자 알고리즘 예제에서는 랜덤하게 선택된 여러개의 점을 이용해 번갈아 가며 각 부모 유전자를 유전하는 자식을 생성하였습니다. (더 자세히 알고 싶으시면, 이전 포스팅을 참고해 주세요).

하지만 이전에 적용하였던 방식은 이번 예제와 같은 조합 최적화 문제에서는 유효하게 적용되지 않습니다. 그림으로 쉽게 설명 드리자면, 기존의 다점 교차방식을 사용하게 되면 왼쪽과 같이 자식해에 같은 도시의 번호가 중첩하는 경우가 생기게 되므로 도시 순회 시 같은 도시를 반복하게 되는 경우가 생기게 됩니다.
조합 최적화 문제처럼 순열을 이용한 유전자 표현을 하게 되는 경우 PMX(Partially Mapped Crossover) 방법이 보통 쓰이게 되는데 이 방법은 교환되는 유전자마다 원래 위치의 유전자를 치환해 줌으로써 유전자가 서로 중첩되는 경우를 방지해주며 교차하는 방법입니다.

하지만 저는 이번 예제에서 더욱 간단한 교차를 위해 두 부모의 교배를 포기하고,
e. 변이 방법
변이는 교차와 비슷한 방법을 사용하여 선택된 두 점의 유전정보를 서로 교환해주는 형식으로 채택하였습니다.
f. 기타
(1) Elitism을 적용하여 매 세대마다 가장 높은 적합도를 가진 2개의 엘리트를 다음 세대로 보존하도록 설계되었습니다.
(2) 한 세대의 해의 개수를 100개로 고정하여 진행하였습니다.
3. 구현
MATLAB 2009a
지난 포스팅과 같이 C#을 이용해서 코딩을 완성했다가.. 소스코드를 모두 날리는 바람에 홧김에 MATLAB으로 다시 코딩했습니다.(프로젝트는 절대 USB에 보관하지 맙시다..) MATLAB의 Optimization Toolkit 내의GA를 이용하면 편하게 할 수 있겠다라는 생각에 시도를 했는데.. SGA(Simple Genetic Algorithm)의 경우에는 정말 몇 개의 파라미터만 던져주면 잘 동작하더라구요.. 하지만 이번 예제와 같이 유전자의 모양자체가 특이한 경우는 거의 대부분을 Custom 해줘야해 시간이 상당히 오래 걸렸습니다. Matlab이 익숙하지 않은 탓도 너무나 크고요!
4. 결과 분석
a. 초기 도시 모습

그림과 같이 40개의 도시의 최적 순회 경로를 찾기 위해 최적화를 수행했습니다. 위에서 설명드린 바와 같이 각 도시간의 거리를 이용해서 적합도를 계산합니다.
b. 반복 결과 과정
17회 반복 최적 경로 | 21회 반복 최적 경로 |


다음과 같은 경로가 현재의 Best Fitness에 해당합니다. 아직은 정말 아무렇게나 효율없이 이동하고 있습니다. 몇 세대를 더 진행해보며 유전알고리즘의 수렴이 어떻게 이루어지고 있는지 살펴보도록 합시다!
50회 반복 최적 경로 | 61회 반복 최적 경로 |


점점 경로의 가닥이 잡혀가기 시작합니다. 21회~50회의 반복을 거치면서 가장 최적이 되는 해의 모양이 급격히 변경되었고 일반적으로 전체 지도를 한바퀴돌면서 경로를 찾아가는 모양의 경로가 나타나기 시작합니다.
73회 반복 최적 경로 | 93회 반복 최적 경로 |


104회 반복 최적 경로 | 129회 반복 최적경로 |


해의 모양이 우리가 생각하는 최적 경로 모양과 비슷하게 잡혀갑니다. 129회의 최적 경로가 최종적으로 발견된 최적 경로의 것으로 판단되고 유전자 알고리즘이 171회까지 해를 유지한 후 종료합니다. (평균 적합도의 변화량이 기준보다 낮을 경우 유전 알고리즘의 반복이 종료되도록 설정되었습니다. 최대 반복수는 1000 세대 입니다.)

171회 반복 최적 경로<수렴 완료>
해의 모양에 있어서 조금 아쉬운 부분들이 보이긴 하지만, 대체적으로 유전자 알고리즘의 수렴을 알아볼 수 있는 좋은 모양을 보여주며 수렴을 종료합니다. 171회 반복 종료 후의 해의 모양이 전역해의 모습은 아닌 듯 하니 더욱더 해의 품질을 높일 수 있는 방법을 생각해보고자 합니다.
c. 한 세대 최대 해 수에 따른 수렴 정도 관찰
한 세대당 100개의 해를 가지는 유전 알고리즘과 세대당 10000개의 해를 가지는 유전 알고리즘의 수렴정도를 비교해 보았습니다.
10000개의 해 | 100개의 해 |


상대적으로 10000개의 해를 가진 왼쪽 그림이 확실히 수렴이 빠른 것을 알 수 있습니다. 뿐만 아니라, 해의 분포가 넓게 위치하기 때문에 평균 적합도(파란 점)의 이동이 적고, 전역해를 찾기에 더욱 유리한 모습을 보이고 있습니다. 100개의 해를 가진 유전 알고리즘은 해의 분포가 전체적으로 고르지 못하기때문에 평균의 이동이 비교적 불규칙적으로 보입니다. 또한 적합도의 수렴이 10000개의 해에 비해 느려 더 많은 반복을 수행하게 됩니다.
5. 마치며..
이번 포스팅에서는 유전알고리즘을 활용한 TSP의 해결에 대한 이야기를 풀어봤습니다. 코딩에 걸린 시간에 비해 포스팅으로 설명할 수 있는 부분이 좀 적었다고 생각되네요. 포스팅에 대한 지적사항은 정말 겸허히 받아들이고 더 좋은 학습을 위해 수정을 하도록 하겠습니다! 질문이나 지적사항은 ohgreat11@gmail.com 으로 보내주시면 감사하겠습니다!
이번 포스팅은 코딩으로 많은 시간을 쏟은 탓일까 아쉬움이 큽니다.. 이 아쉬움을 다음 포스팅에서 풀도록 하겠습니다. 다음 포스팅은 아마도 이번 예제의 소스코드 설명과 함께 MATLAB Optimization Toolkit 사용법에 관련된 내용일듯 하네요!
TSP (Traveling Salesman Problem) 이란 문자 그대로,
물건을 판매하기 위해 여행하는 세일즈맨의 문제입니다.
물건을 팔기 위해서 어떤 도시를 먼저 방문해서 최소한의 비용으로
도시들을 모두 순회하고 돌아올 수 있는 지를 구하는 것이 이 알고리즘의 핵심입니다.
TSP는 컴퓨터 사이언스의 대표적인 난제로, 컴퓨터 사이언스에서 가장 많은 연구가 이루어지고 있는 주제 중 하나 입니다.
문제를 직관적으로 이해하기란 간단하지만 답을 도출 시키는 것은 쉽지 않기 때문입니다.
TSP는 가장 대표적인 NP-Hard 문제입니다.
번외로, NP-Hard란 Nondeterministic Polynomial - Hard의 약자입니다.
즉 결정석 다항식으로 구성할 수 없다는 것이죠.
e.g) x-2 = 8 이것은 대표적인 다항식 문제입니다. 답을 도출해내기도 쉽죠.
하지만 A, B, C라는 도시 세가지를 놓고 어떤 도시를 먼저 방문하는 것이 총 비용상으로
가장 효율적인가(Optima)를 구하는 것에 대해서는 방정식을 세울 수 없습니다.
물론 다항식으로 나타낼 수 있을 수도 있습니다. NP하드라고 해서 다항식이 아니라는 것은 아닙니다.
다만 다항식으로 표현될 수 있을 지의 여부가 아직 알려지지 않았다라는 것입니다.
오늘날의 컴퓨터는 P(Polynomial)에 관한 문제는 일정 term을 주면 해결가능 할 것입니다.
하지만 NP는 그와 반대로 엄청난 실행 사이클을 잡아 먹을 것입니다.
즉, NP-Hard란 TSP문제와 같이 모든 경우의 수를 일일히 확인해보는 방법이외에는 다항식 처럼 답을 풀이 할 수 없는 문제들을 말합니다.
지금까지 알려진 방법으로는 Polynomial time내에 어느 성능 이상의 TSP 최적해를 보장할 수 있는 방법이 없습니다.
이론적인 근사 알고리즘이 있을 뿐입니다. <Christofides, 1976>

<그림 1>
그림 1과 같이 원으로 저렇게 산발적으로 퍼진 점들을 어떤 점의 순서로 이어야 최소한의 비용으로 모든 점을
순회할 수 있는 지를 구하는 것이 바로 TSP의 목적입니다.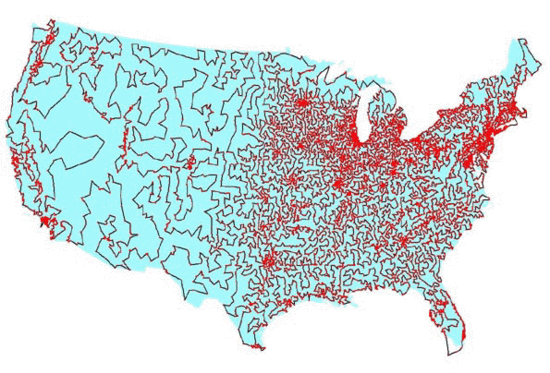
<그림 2>
그림 2와 같이 미대륙 내의 모든 도시를 방문하는 것도 TSP의 문제중 하나입니다.
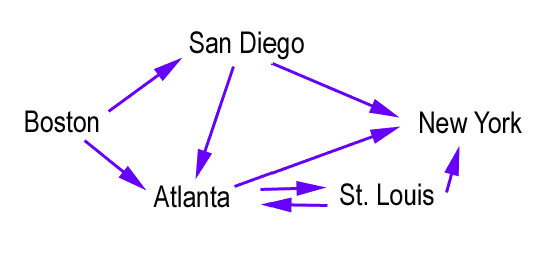
보스턴에서 시작을 하고 모든 도시를 방문한다고 가정을 합시다.
Boston -> San Diego -> Atlanta -> St.Louis -> New York 의 경로로 갈 수 있겠지만
Boston -> San Diego -> Atlanta -> St.Louis -> Atlanta -> New York의 경로가 더 나을 수도 있습니다.
이 처럼 도시간의 비용을 모두 따져서 최적의 순회 방법을 찾는 것이 TSP입니다.
위와 같은 문제는 쉽게 풀이 할 수 있습니다.
왜냐하면 n의 숫자가 너무 작고 (n이란 도시의 숫자를 말합니다.) 방향성을 띄고 있기 때문입니다.
위의 문제에서 업그레이드를 해서 쌍방향으로 이동이 가능하다고 가정하고 n이 100이상으로 커진다고 하면
사람이 풀이하는 데 많은 시간이 걸릴 것입니다.
'알고리즘 & 자료구조 > 알고리즘&자료구조' 카테고리의 다른 글
| K-d 트리 (0) | 2013.04.14 |
|---|---|
| P vs NP 문제 이야기 (0) | 2012.12.23 |
| 해밀턴회로 (0) | 2012.12.23 |
| 근의 공식 알고리즘 소스코드 (0) | 2012.11.02 |
| Red-Black Tree (0) | 2012.11.01 |