

Hash Motivation

Direct Access Array

Hashing

Chaining
chaining 은 해쉬 테이블이 아닌 다른 자료 구조에 아이템을 저장해서 충돌을 해결하는 방법입니다. 해쉬 테이블의 각 인덱스에는 아이템이 아닌 또 다른 자료 구조를 가르키는 포인터가 저장됩니다. 이 자료 구조는 insert, search, 그리고 delete(k) 를 상수 비용으로 지원하는 Set Interface 이고 chain 이라고 합니다. linked list 나 array 를 생각하면 됩니다.
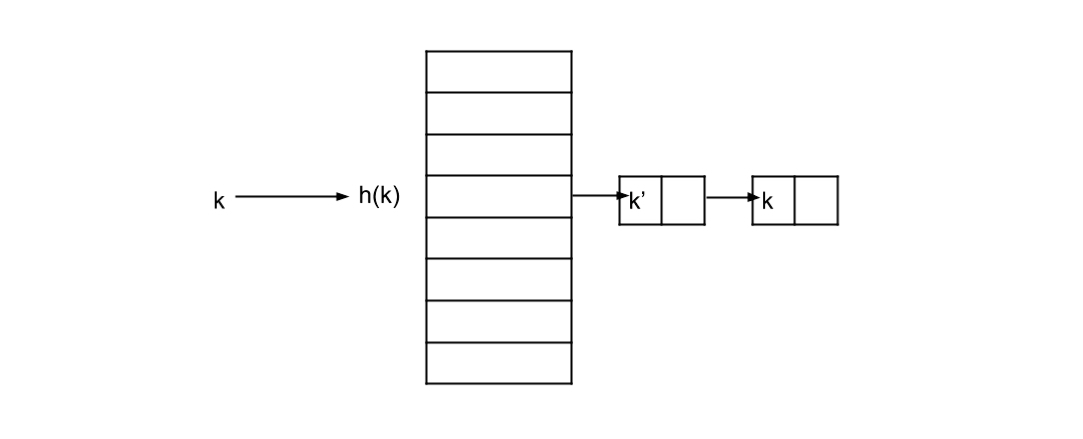
충돌이 발생해도 모든 해쉬 테이블의 chain 의 크기가 상수 이면 insert, serach, 그리고 delete(k) 를 O(1) 으로 수행할 수 있게 되고 이것이 hashing 을 통해 달성하고자 하는 목표인데요. 이를 위해서는 해쉬 함수가 중요합니다. 만약에 아주 안좋은 해쉬 함수를 선택해서 모든 키의 해쉬 값이 동일한 인덱스를 가진다면, 해당 인덱스 chain 의 크기는 O(n) 이 되고 insert, serach, 그리고 delete(k) 의 비용도 O(n) 이 되버립니다. 최악이죠.
이상적으로 어떠한 키 유니버스가 주어져도 충돌의 개수를 줄여서 테이블의 가장 큰 chain 의 크기가 상수인 해쉬 함수를 선택해야 합니다.
Universal Hashing
좋은 해쉬 함수의 기준을 다시 한번 정리하겠습니다.
어떠한 키 유니버스가 주어져도 충돌의 개수를 줄여서 가장 큰 chain 의 크기를 상수로 만드는 해쉬 함수



Dot Product Hash Family


참조
https://www.youtube.com/watch?v=Nu8YGneFCWE&list=PLUl4u3cNGP63EdVPNLG3ToM6LaEUuStEY&index=5
https://www.youtube.com/watch?v=z0lJ2k0sl1g&list=PLTV7NgF818VXpV2P-Px2H74hvEBL2o-G2&index=11
'알고리즘 & 자료구조 > 알고리즘&자료구조' 카테고리의 다른 글
| Time complexity , Big O notation (0) | 2018.05.14 |
|---|---|
| int 숫자를 char 숫자로 변환 (0) | 2016.04.10 |
| Hash Functions (continued) - Fowler/Noll/Vo Hash (0) | 2013.06.04 |
| 해쉬함수 (0) | 2013.05.23 |
| LUT (Lookup Table) 룩업테이블 : 미리 계산된 테이블 (0) | 2013.05.19 |