


전반적인 강화 학습의 형태
강화 학습에는 Agent, Action , State ,Reward , Environment 가 존재한다
Agent 는 알고리즘 이라고 생각하면 되는데

이와 같은것들이 있다
환경을 제작할 수 있는 엔진에는 유니티, 언리얼 등등이 있다

강화 학습에는 Agent, Action , State ,Reward 가 있으며 이것이 Environment에서 돈다

Agent 는 강화학습 딥러닝으로 많이들 한다
이때 딥러닝은 파이썬이나 TensorFlow 등등을 이용함
머신러닝과 가장 큰 차이점은 딥러닝은 분류에 사용할 데이터를 스스로 학습할 수 있는 반면
머신 러닝은 학습 데이터를 수동으로 제공해야한다는점이 딥러닝과 머신러닝의 가장 큰 차이점입니다.
머신 러닝이란?
인공지능의 하위 집한 개념인 머신러닝은 정확한 결정을 내리기 위해 제공된 데이터를 통하여 스스로 학습할 수 있습니다. 처리될 정보에 대해 더 많이 배울 수 있도록 많은 양의 데이터를 제공해야 합니다.
즉, 빅데이터를 통한 학습 방법으로 머신러닝을 이용할 수 있습니다. 머신 러닝은 기본적으로 알고리즘을 이용해 데이터를 분석하고, 분석을 통해 학습하며, 학습한 내용을 기반으로 판단이나 예측을 합니다. 따라서 궁극적으로는 의사 결정 기준에 대한 구체적인 지침을 소프트웨어에 직접 코딩해 넣는 것이 아닌, 대량의 데이터와 알고리즘을 통해 컴퓨터 그 자체를 ‘학습’시켜 작업 수행 방법을 익히는 것을 목표로 한답니다.
환경은 내가 알아서 만듬(유니티, 언리얼 같은것으로)
Agent 와 환경은 둘이 다른 환경(프로그래밍 언어등)인데 이 둘 사이를 연결해주는것을 보고 유니티에서
ML-Agent 라하며 이것을 ToolKit 이라 볼 수 있다
#1

이 그림에서 보면 Learnig Enviroment 유 유니티 같은 환경에서 보상과 관측된 정보를 Python API 로 넘긴다
Python API 에서 넘어온 정보를 기반으로 강화학습 알고리즘을 만들어(Python Low-Level API) 알고리즘을 통하여 Action 을 다시 환경으로 넘겨주게 할 수 있다
그런데 강화학습 알고리즘을 직접 짜곳 싶지 않다면 유니티에서 제공하는 Python Trainer 를 갖고 학습을 시킨후
액션을 선택하여 환경에 넘겨줘 서로 통신할수 있게 할 수 있다

Trainers 를 통해서 할대는 학습이 완료된 .nn 이라는 파일을 유니티로 내장 후 이것을 그대로 사용 할 수 있다

ML-Agent 1.0 에선 다음과 같은것들이 있었음


Agents 스크립트는
환경을 다 구성해 놓고 어떤 정보와 어떤 액션들어오는 지에 따라서 어떻게 행동 할지를 결정 할수 있는 스크립트
보상과 게임 종료 조건도 결정 할 수 있다
Behavior 스크립트(예전에는 Brain 이였다고함) ( 위 그림에서 Behavior Parameters 스크립트)
1.0 에서
예젠에는 Acamedy 가 있었는데(빌드된 화면의 환경크기, 몇프레임마다 화면 업데이트 할지등등)
지금은 Acamedy 가 사라지고 파이썬으로 옮겨갔음
Agent 하나당 하나의 Behavior 스크립트가 붙어야 하며 이 Behavior 는 Agents 에 대한 구체적인 설정을 하게된다
Vector Observation : x,y,z 위치, 속도 등 관측에 필요한 정보개수들 설정
Stacked Vectors : 이전것 그 전전의 것 그 전전전의 것을 쌓아서 행동을 결정할때 쌓는정도를 말함
Space Type : 액션의 타입인데 연속적인 액션 또는 비연속적인 액션등으로 설정 할 수 있음
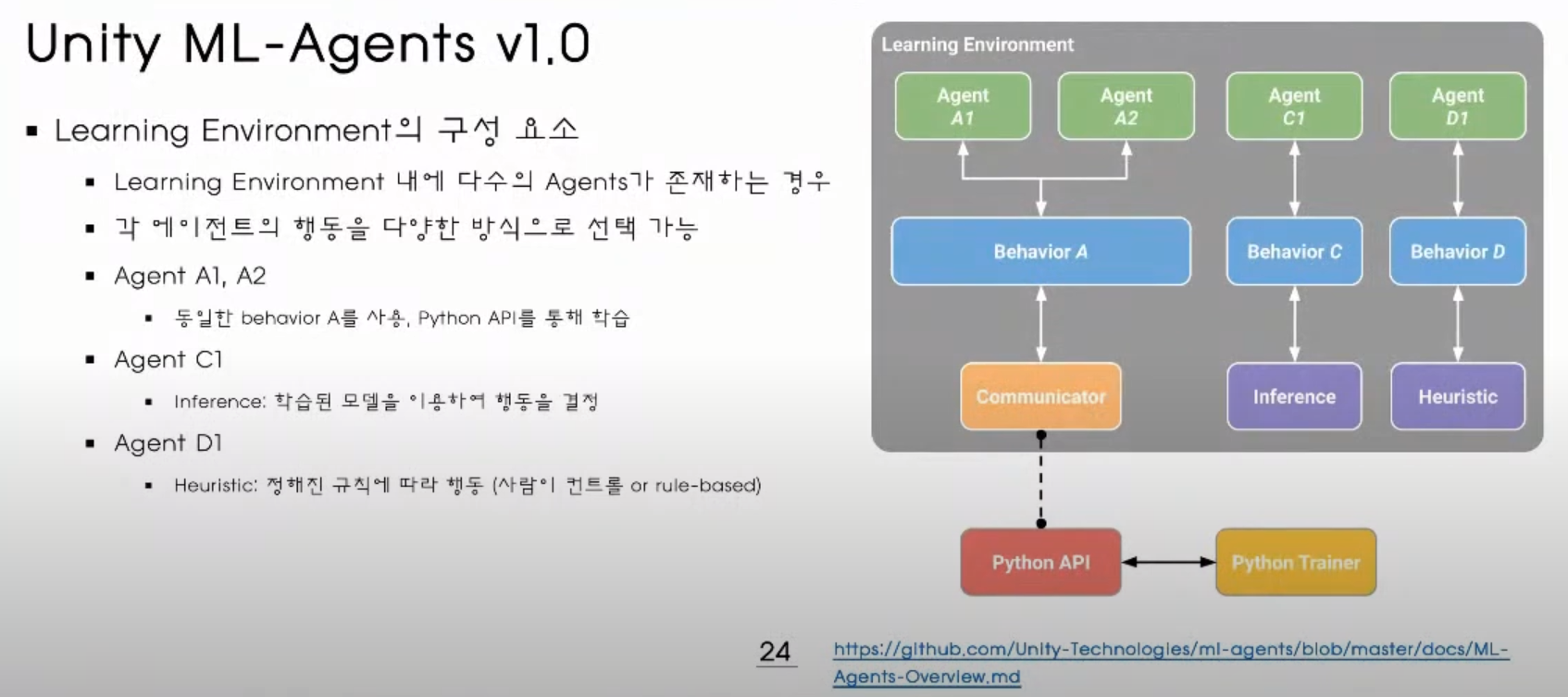
학습환경 내에 있는 Agent A1, Agent A2 가 사용하는 Behavior 가 같다면 Behavior 를 하나로 묶어줘도 된다
그다음 이렇게 묶인 것을 Communicator 를 통해서 Python API 와 통신하게 만든다 (#1)
여기서 오른쪽에 Behavior C 는 inference 와 견결 되어 있는데 inference 는 이미 학습된 강화 학습을 통한 결과를 통해 곧바로 행동 할수 있도록 하는것
Behavior D 는 Heuristic 과 연결 되어 있는데 이것은 정해진 규칙에 의해서 움직이게 할 수 있다
사람이 제어하게 할수 있거나, 규칙에 따라 설정 해줄 수가 있다

유니티와 파이썬 사이에 직접적으로 연관 없는데이터를 교환하는 것이 가능하다
ex ) 자동차를 강화 학습 하는데 자기자신이 아닌 앞차나 뒷차의 정보가 앞차와 뒷차의 거리 등등이 궁금할때(log) Side Channel 을 통해 해볼 수 있다


위 처럼 하나를
Agent 를 하나가 아닌 여러개로 구성하여 강화학습을 좀 더 빠르게 하는 방법들이 존재..
Distributed Agents :

이것처럼 여러개로 만들어 좀 더 빠르고 정확한 결과를 볼 수도있음

Multi-agents : 양 한마리에 여러 사자들이 협력하여 양을 잡을 수 있게 할 수있음

1:1로 붙는 agents 학습을 말함 알파고 바둑 같은 경우를 말함 , 흑/백돌
둘이서 Self play 환경 (ai 끼리 대결하면서 하는 학습방식)
이때 학습 해놓은것에서 하나를 빼고 대신 사람이 플레이하게 해서 학습 할 수 도 있게 할수 있따

파란색이 주황색공을 피하게 한다
limitation Learning 은 사람이 하는 행동을 따라하는 것을 말함
우선 사람이 플레이를 한다음 그때의 행동이나 데이터를 기반으로해서 사람이 한것을 따라해보라고 학습을 시키는 것을 말한다
학습이 이상하면 플레이어의 문제 일 수도 있음

중간 사각형의 색상에 따라서 파란색 삭각형이 색상에 일치하는 문으로 가는 Agent 의 예시이다

이것 같은 경우에는 골기퍼들이 하나씩 있고 스트라이커들이 골을 넣는 환경으로
각자의 Agents 의 역할이 다르다 행동들도 다르다, 즉 Multi Agent 이다

강화 핛브에는 오른쪽 그림 처럼 Exploitation 이냐 Exploration 이냐에 따라서 학습 되는것이 다르다
이것은 강화 학습에서 중요한 문제인데, 오른쪽 그림에서 로봇이 아래로만 가도 reward 를 1 을 얻기 때문에
계속 아래로만 갈 수 있다는것 위로가면 더 좋은 보상을 얻을 수 있지만 위로 가기전까진 모름으로
어떻게 에이전트가 다양한 경험을 하면서 학습할지가 성능등 중요한 문제 중 하나
* 학습과 탐험을 적절히 섞어 행동하도록 하는것이 중요
e : 엡실론 (랜덤하게 액션을 선택할 확률)

x 값이 1에 가까워지면 행동 하던대로만 행동하게 되고 0에 가까워지면 여러 탐색을 먼저 시도를 하게 된다
이것이 엡실론 그리디 방식임
그렇지만 목표에 도달하는데까지 상황이 복잡해질 수록 랜덤하게 탐험 하는것인 목표에 도달하는데 거의 불가능에 가까워진다, 보상획득이 어려워져 학습이 불가

이런것은 랜덤 학습으로 키 까지 도달하는데 어려움(거의 불가)
그런데 호기심(curiosity) 탐험 방식이 있는데
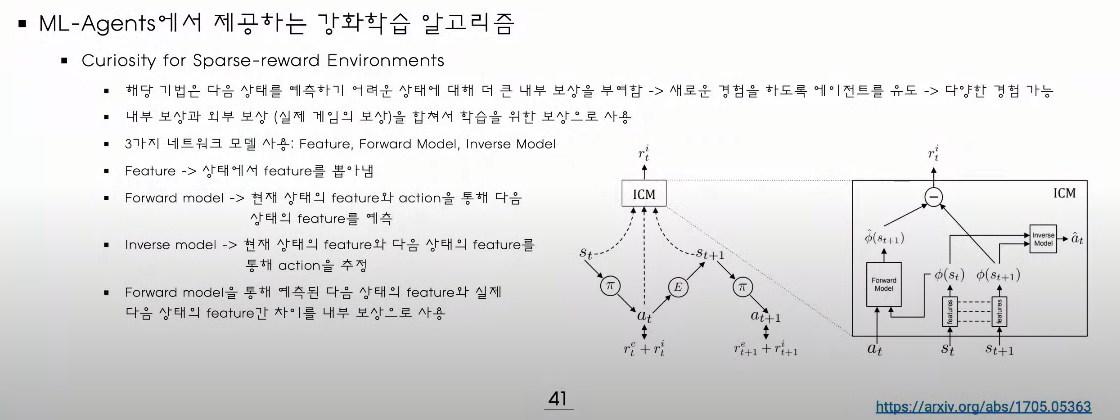
다음 상태를 예측하기 어려워서 내부 보상을 부여하여 새로운 경험을 선택하도록함
외부 보상은 일반적으로 게임에 보이는 보상
스태이트와 다음 스태이트가 있을 경우 이것을 동일한 Feature 라는 네트워크를 몇번 통과 시킨다
(상태에서 Feature 를 뽑아냄)
이렇게 뽑아진 Feature 를 Forward Model 이라는 곳에 넣어서 다음 스태이트를 예측해본다 (즉 예측한 다음 상태가 나옴)
현재 상태와 다음 상태를 뽑고
현재 상태에서 내부 보상을 통하여 다음 상태를예측한다음(Forward Model)
현제에서다음을 예측한것과 다음 상태간의 차이를 구한다
즉 이 차이를 이용하여 내부 보상을 만든다
내부 보상이 큰경우 : 현재 상태의 액션을 갖고 다음 상태를 예측 했을때 다음 상태와의 차이가 큰경우를 말함
내부 보상이 작은경우 : 현재 상태의 액션을 갖고 다음 상태를 예측 했을때 다음 상태와의 차이가 작은경우를 말함
inverse Model :
현재 상태의 state 와 다음 상태의 state 를 둘다 넣고 액션을 해봤을 때 추정하는것으로 추정된 액션과 실제 액션으로 잘 추정하도록 만드는것을 말함 , 즉 이것이 잘 되야 현재에서 다음상태로의 유의미한 Feature 를 뽑아낼수 있는것
정리하자면 다음 상태를 잘 모르겠는 상태일때 내부 보상을 크게 줘서 원하는곳으로 가도록 유도하는것
가본적이 많이 없으면 내부 보상이 작아진다
즉 다른곳으로 가게 하려면 내부 보상을 줄이면 된다(새로운 곳으로 가도록 유도함)
처음 가보는 곳은 내부 보상이 커지게 바꾼다
즉 랜덤하게 돌아다니면 경우의 수가 너무 많기 때문에 이런 식으로 다음 탐험에 대한 방향성을 좁힐 수 있다

imitation
사람의 플레이를 통해서 경험을 쌓는 방식
만약 사람이 플레이를이상하게 하면 agent 도 이상하게 행동을 하게 된다

이미테이션 러닝에서 레퍼런스가 되는 애니메이션이 있고 여기에서 목표하는 타겟을 때리는 것을 강화학습으로 애니시키면 그냥 강화학습으로 목표를 때리는것보다는 자연스럽게 처리 할 수 있다

유니티 ML-Agents 에서 제공 하는 학습 방법은?
Self-Play : Agent 끼리 서로 대결하면서 학습하는 방식
- Symmetric 액션이랑 보상함수가 동일한형태로 Policy 를 공유할수 있음

Agent 의 위치와 속도 , 공의 위치, 속도 등의 요소를 고려하여 학습
https://openai.com/blog/emergent-tool-use/ 같은 사이트에서 제공하는 학습이 있다
빨강애가 못오게 파랑색이 문을 막는다 
Curriculum Learning : 어려운 문제를 한단계씩 쉬운 난이도 부터 학습해서 조금식 어렵게 바꿔나가는 방식
파란색이 초록색 박스를 밀어서 녹색 플러스에 집어 넣어야 한다, 빨간색 플러스쪽으로 밀어 넣으면 안됨
제대로 밀어 넣었으면 좀 더 어려운 다음 스테이지에서도 밀어 넣을 수 있도록 난이도를 점점 높여간다
엡실론 (랜덤하게 액션을 선택할 확률) 값을 적당히 높여서 다음 난이도에서 학습하도록함

Environment parameter Randomization :

사각형 얼굴이 왔다갔다하면서 위에 공을 떨어뜨리지 않도록 할때 Environment parameter 를 쓸 수 있다
공의 크기 또한 바꿀 수 있도로고 파라미터화를 할 수도 있다 (이런 랜덤한 값이 실행활에 있을수 있으니 그런 경우에 유용하다)

자동차가 여러개 가고있는데 그중 하나가 끝착선에서 다른 끝차선으로 차선 변경할대 Multi-Agent 를 사용 할수 있다
차선을 이동하는 차가 아닌 다른 차들도 협력을해야 하는 상황
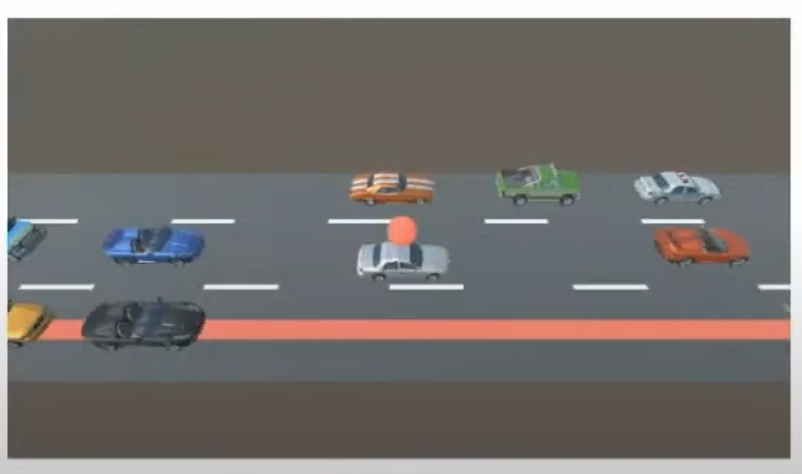
빨간색 공이 있는 차가 빨간선 라인으로 차선 변경을 하기 위해서 다른 차들이 비키거나 속력을 내서 공간을 확보한 이후 차선 변경이 되도록함, 하지만 다른 차들의 속도저하는 최소한으로 처리하도록 함
알까기 : 당구와 비슷
알을 까서 이동하는 동안 상대방은 치면 안됨
액션을 결정하는데 조건이 있음 즉 상대방이 친 돌이 이동하고 멈춰야 내 돌이이동 할 수 있음
이때 어떤 조건에서 알을 까도록 decision 을 설정할 수 있는데 이것을 만들어 주면 가능함
ML-Agent 설계 팁
- Obervation : 최대한 실제적인 것을 사용 하는것이 중요하다, 처음엔 목표달성에 너무 쉬운 정보들을 줬다가 점점 빼는 형태로 가면 학습 속도를 빨리 할 수 있다
- Action : 너무 많을 수록 학습이 잘 안된다, 액션의 조합을 다 합처서 많으면 너무 선택이 많음으로
- Reward : 어떻게 움직이고 싶어하는 목표에 맞춰서 만든다
전체적으로 너무 많은 변수들과 액션 리워드를 세팅 하면 처음 학습 자체가안되거나 어디서 문제가 발생이 됐는지 알기 어려움으로 환경을 과 액션 reward 를 최대한 간단하게 만들고 여기서 학습이 되는 것을 확인한 다음에 차츰 어려운 환경을 만들어 나가는 것이 최종 만들어나가는데 빠른길이 될 수 있다
'게임엔진(GameEngine) > Unity3D' 카테고리의 다른 글
| Android SDK does not include your Target SDK of 28 (0) | 2022.01.15 |
|---|---|
| ScriptableObject 사용 예시 (0) | 2021.11.03 |
| Load prefabs via script and save scene in Unity Editor (0) | 2021.04.28 |
| 부모 자식간의 콜리전 분리 (0) | 2021.04.20 |
| Vector3.Scale : Multiplies two vectors component-wise. (0) | 2021.01.13 |