

제공 : 한빛 네트워크
저자 : 최흥배
http://www.hanb.co.kr/network/view.html?bi_id=1618
이번에는 이전 회에 설명한 hash_map과 같은 연관 컨테이너 중의 하나인 map에 대해서 설명합니다. 사용법이 hash_map과 대부분 비슷해서 앞으로 할 이야기가 별로 어렵지 않을 것입니다.
이전 회에서 설명했던 것은 가급적 또 설명하지 않을 테니 앞의 글들을 보지 않은 분들은 꼭 봐 주세요. 그럼 map에 대한 이야기를 시작 하겠습니다.
7.1 map의 자료구조
map의 자료구조는 '트리(tree)'입니다(정확하게 말하면 트리 자료구조 중의 하나인 '레드-블랙 트리(Red-Black tree)'입니다).
트리는 한글로 '나무'입니다. 나무는 뿌리에서 시작하여 여러 갈래의 가지가 있고, 가지의 끝에는 나무 잎이 있습니다. 트리 자료구조도 이와 같은 형태를 가지고 있어서 루트(root), 리프(leaf)라는 용어를 사용합니다. 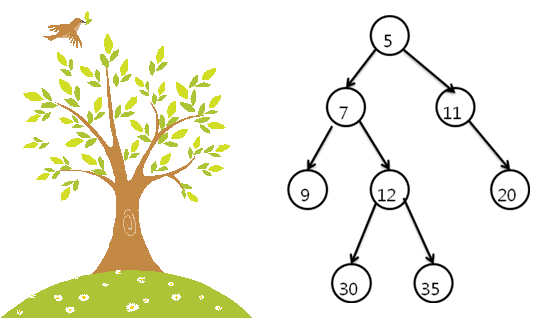
[그림 1] 실제 나무(왼쪽)와 트리 자료구조의 모습(오른쪽)
오른쪽의 트리 자료구조에서 제일 최상 위의 '5'는 루트 노드(root node)라고 하며, 노드'5'와 노드'7'의 관계에서 노드'5'는 부모 노드(parent node), 노드'7'은 자식 노드(child node)라고 합니다. 또한 노드 '12'와 노드 '30'의 관계에서는 부모 노드는 노드'12'입니다. 자식이 없는 노드는 리프 노드(leaf node)라고 합니다. 그림 1에서는 '9', '30', '35', '20'이 리프 노드입니다.
7.2 트리 자료구조의 특징
트리는 노드를 균형 있게 가지는 것이 성능에 유리하기 때문에 기본 트리에서 변형된 B-트리, B+ 트리, R-트리, 레드 블랙 트리, AVL 트리 등 다양한 종류의 트리 자료구조가 있습니다.
균형을 이룬 트리는 자료를 정해진 방식에 따라서 분류하여 저장하기 때문에 시퀸스(일렬로)하게 자료를 저장하는 연결 리스트에 비해서 검색이 빠릅니다. 그렇지만 정해진 규칙에 따라서 자료를 삽입, 삭제 해야 되기 때문에 삽입과 삭제가 간단하지 않으며 구현이 복잡합니다.
7.3 map을 언제 사용해야 될까?
map은 많은 자료를 정렬하여 저장하고 있고 빠른 검색을 필요로 할 때 자주 사용합니다. 많은 자료를 빠르게 검색한다고 하는 부분은 앞 회에서 설명한 hash_map과 비슷합니다. 그러나 hash_map과 크게 다른 부분이 있습니다. map은 자료를 저장할 때 내부에서 자동으로 정렬을 하고, hash_map은 정렬하지 않는다라는 것입니다. 정렬이 필요하지 않는 곳에서 map을 사용하는 것은 불 필요한 낭비입니다.
map은 아래 조건일 때 사용하면 좋습니다.
1. 정렬해야 한다.
2. 많은 자료를 저장하고, 검색이 빨라야 한다
3. 빈번하게 삽입, 삭제하지 않는다.
7.4 map 사용 방법
가장 먼저 map의 헤더파일을 포함합니다.
#include보통 map을 사용하는 방법은 아래와 같습니다.
map< key 자료 type, value 자료 type > 변수 이름 map< int, int > map1;value는 저장할 자료이고, key는 value를 가리키는 것입니다. 위에서는 key의 자료형 int, value 자료형 int인 map을 생성합니다.
앞에서 map은 자료를 저장할 때 정렬을 한다고 말했습니다. 정렬의 대상은 key를 대상으로 하며오름차순으로 정렬합니다. 그래서 내림차순으로 정렬하고 싶거나 key의 자료형이 기본형이 아닌 유저 정의형(class나 struct로 정의한 것)인 경우는 정렬 방법을 제공해야 합니다.
위에 생성한 map1은 오름차순으로 정렬하는데 이것을 내림차순으로 정렬하고 싶다면 아래와 같이 하면 됩니다.
map< key 자료 type, value 자료 type, 비교 함수 > 변수 이름 map< int, int, greater<int> > map1;위에서 사용한 비교 함수 greater는 제가 따로 만든 것이 아니고 STL에 있는 템플릿입니다.
greater와 같은 것을 STL 알고리즘 이라고 하는데 이것들은 다음 시간에 자세하게 설명할 예정이니 여기서는 이런 것이 있다는 것만 아시면 됩니다.
다른 컨테이너와 같이 map도 동적 할당을 할 수 있습니다. 사용 방법은 앞서 소개한 컨테이너들과 비슷합니다.
앞 회의 hash_map과 비교를 하면 사용 방법이 거의 같다라는 것을 알 수 있습니다. 이후 소개하는 map의 멤버함수도 일부분만 제외하고는 hash_map과 같습니다. 이전에도 이야기 했지만 서로 다른 컨테이너가 사용방법이 서로 비슷하여 하나만 제대로 배우 나머지 것들도 배우기 쉽다라는 것이 STL의 장점 중의 하나입니다.
7.4.1 map의 주요 멤버들
| 멤버 | 설명 |
| begin | 첫 번째 원소의 랜덤 접근 반복자를 반환 |
| clear | 저장하고 있는 모든 원소를 삭제 |
| empty | 저장 하고 있는 요소가 없으면 true 반환 |
| End | 마지막 원소 다음의(미 사용 영역) 반복자를 반환 |
| erase | 특정 위치의 원소나 지정 범위의 원소들을 삭제 |
| Find | key와 연관된 원소의 반복자 반환 |
| insert | 원소 추가 |
| lower_bound | 지정한 key의 요소를 가지고 있다면 해당 위치의 반복자를 반환 |
| operator[] | 지정한 key 값으로 원소 추가 및 접근 |
| rbegin | 역방향으로 첫 번째 원소의 반복자를 반환 |
| rend | 역방향으로 마지막 원소 다음의 반복자를 반환 |
| size | 원소의 개수를 반환 |
| upper_bound | 지정한 key 요소를 가지고 있다면 해당 위치 다음 위치의 반복자 반환 |
[표 1] map의 주요 멤버들
7.4.2. 추가
map 에서는 자료를 추가 할 때 insert를 사용합니다.
원형 : pair <iterator, bool> insert( const value_type& _Val ); iterator insert( iterator _Where, const value_type& _Val ); template<class InputIterator> void insert( InputIterator _First, InputIterator _Last );첫 번째 방식이 보통 가장 자주 사용하는 방식입니다.
map< int, int > map1; // key는 1, value는 35를 추가. map1.insert( map< int, int >::value_type(1, 35)); // 또는 STL의 pair를 사용하기도 합니다. typedef pair < int, int > Itn_Pair; map1.insert( Int_Pair(2, 45) );두 번째 방식으로는 특정 위치에 추가할 수 있습니다.
// 첫 번째 위치에 key 1, value 35를 추가 map1.insert( map1.begin(), map< int, int >::value_type(1, 35) ); // 또는 map1.insert( map1.begin(), Int_Pair(2, 45) );세 번째 방식으로는 지정한 반복자 구간에 있는 것들을 추가합니다.
map< int, int > map2; // map1의 모든 요소를 map2에 추가. map2.insert( map1.begin(), map1.end() );map은 이미 있는 key 값을 추가할 수 없습니다(복수의 key 값을 사용하기 위해서는 multi_map을 사용해야 합니다). 가장 자주 사용하는 첫 번째 방식으로 추가하는 경우는 아래와 같은 방법으로 결과를 알 수 있습니다.
pair< map<int, int>::iterator, bool > Result; Result = map1.insert( Int_Pair(1, 35));만약 이미 key 값 1이 추가 되어 있었다면 insert 실패로 Result.second 는 false이며, 반대로 성공하였다면 true 입니다.
operator[]를 사용하여 추가하기
insert가 아닌 operator[]를 사용하여 추가할 수도 있습니다.
// key 10, value 80을 추가 map1[10] = 80;7.4.3. 반복자 사용
다른 컨테이너와 같이 정 방향 반복자 begin(), end()와 역 방향 반복자 rbegin(), rend()를 지원합니다.
사용 방법은 다음과 같습니다.
// 정 방향으로 map1의 모든 요소의 value 출력
map< int, int >::iterator Iter_Pos;
for( Iter_Pos = map1.begin(); Iter_Pos != map1.end(); ++Iter_Pos)
{
cout << Iter_Pos.second << endl;
}
// 역 방향으로 map1의 모든 요소의 value 출력
map< int, int >::reverse_iterator Iter_rPos;
for( Iter_rPos = map1.rbegin(); Iter_rPos != map1.rend(); ++Iter_rPos)
{
cout << Iter_rPos.second << endl;
}
위에서 map을 정의할 때 비교함수를 사용할 수 있다고 했습니다. 만약 비교함수를 사용한 경우는 반복자를 정의할 때도 같은 비교함수를 사용해야 합니다.map< int, int, greater<int> > map1; map< int, int, greater<int> >::iterator Iter_Pos;7.4.4. 검색
map에서 검색은 key 값을 대상으로 합니다. key와 같은 요소를 찾으면 그 요소의 반복자를 반환하고, 찾지 못한 경우에는 end()를 가리키는 반복자를 반환합니다.
원형 : iterator find( const Key& _Key ); const_iterator find( const Key& _Key ) const;두 방식의 차이는 반환된 반복자가 const냐 아니냐는 차이입니다. 첫 번째 방식은 const가 아니므로 찾은 요소의 value를 변경할 수 있습니다(참고로 절대 key는 변경 불가입니다). 그러나 두 번째 방식은 value를 변경할 수 없습니다.
// key가 10인 요소 찾기.
map< int, int >::Iterator FindIter = map1.find( 10 );
// 찾았다면 value를 1000으로 변경
if( FindIter != map1.end() )
{
FindIter->second = 1000;
}
7.4.5. 삭제 저장하고 있는 요소를 삭제할 때는 erase와 clear를 사용합니다. erase는 특정 요소를 삭제할 때 사용하고, clear는 모든 요소를 삭제할 때 사용합니다.
erase
원형 : iterator erase( iterator _Where ); iterator erase( iterator _First, iterator _Last ); size_type erase( const key_type& _Key );첫 번째 방식은 특정 위치에 있는 요소를 삭제합니다.
// 두 번째 위치의 요소 삭제. map1.erase( ++map1.begin() );두 번째 방식은 지정한 구역에 있는 요소들을 삭제합니다.
// map1의 처음과 마지막에 있는 모든 요소 삭제 map1.erase( map1.begin(), map1.end() );세 번째 방식은 지정한 키와 같은 요소를 삭제합니다.
// key가 10인 요소 삭제. map1.erase( 10 );첫 번째와 두 번째 방식에서는 삭제하는 요소의 다음을 가리키는 반복자를 반환하고(C++ 표준에서는 반환하지 않습니다만 Microsoft의 Visual C++에서는 반환합니다), 세 번째 방식은 삭제된 개수를 반환합니다. map에서는 세 번째 방식으로 삭제를 하는 경우 정말 삭제가 되었다면 무조건 1이지만, multi_map에서는 삭제한 개수만큼의 숫자가 나옵니다.
clear
map의 모든 요소를 삭제할 때는 clear를 사용합니다.
map1.clear();이것으로 map에서 자주 사용하는 멤버들에 대한 설명은 끝났습니다. [표 1]에 나와 있는 멤버들 중 사용 방법이 간단한 것은 따로 설명하지 않으니 [리스트 1]의 코드를 봐 주세요.
[리스트 1] 정렬된 아이템 리스트 출력
#include <map>
#include <string>
#include <iostream>
using namespace std;
struct Item
{
char Name[32]; // 이름
char Kind; // 종류
int BuyMoney; // 구입 가격
int SkillCd; // 스킬 코드
};
int main()
{
map< char*, Item > Items;
map< char*, Item >::iterator IterPos;
typedef pair< char*, Item > ItemPair;
Item Item1;
strncpy( Item1.Name, "긴칼", 32 );
Item1.Kind = 1; Item1.BuyMoney = 200; Item1.SkillCd = 0;
Item Item2;
strncpy( Item2.Name, "성스러운 방패", 32 );
Item2.Kind = 2; Item2.BuyMoney = 1000; Item2.SkillCd = 4;
Item Item3;
strncpy( Item3.Name, "해머", 32 );
Item3.Kind = 1; Item3.BuyMoney = 500; Item3.SkillCd = 0;
// Items에 아이템 추가
Items.insert( map< char*, Item >::value_type(Item2.Name, Item2) );
Items.insert( ItemPair(Item1.Name, Item1) );
// Items가 비어 있지않다면
if( false == Items.empty() )
{
cout << "저장된 아이템 개수- " << Items.size() << endl;
}
for( IterPos = Items.begin(); IterPos != Items.end(); ++IterPos )
{
cout << "이름: " << IterPos->first << ", 가격: " << IterPos->second.BuyMoney << endl;
}
IterPos = Items.find("긴칼");
if( IterPos == Items.end() ) {
cout << "아이템'긴칼'이 없습니다." << endl;
}
cout << endl;
cout << "올림차순으로 정렬되어있는 map(Key 자료형으로string 사용)" << endl;
map< string, Item, less<string> > Items2;
map< string, Item, less<string> >::iterator IterPos2;
Items2.insert( map< string, Item >::value_type(Item2.Name, Item2) );
Items2.insert( ItemPair(Item1.Name, Item1) );
// operator[]를 사용하여 저장
Items2[Item3.Name] = Item3;
for( IterPos2 = Items2.begin(); IterPos2 != Items2.end(); ++IterPos2 )
{
cout << "이름: " << IterPos2->first << ", 가격: " << IterPos2->second.BuyMoney << endl;
}
cout << endl;
cout << "해머의 가격은 얼마? ";
IterPos2 = Items2.find("해머");
if( IterPos2 != Items2.end() ) {
cout << IterPos2->second.BuyMoney << endl;
}
else {
cout << "해머는 없습니다" << endl;
}
cout << endl;
// 아이템 "긴칼"을 삭제한다.
IterPos2 = Items2.find("긴칼");
if( IterPos2 != Items2.end() ) {
Items2.erase( IterPos2 );
}
cout << "Items2에 있는 아이템 개수: " << Items2.size() << endl;
return 0;
}
결과 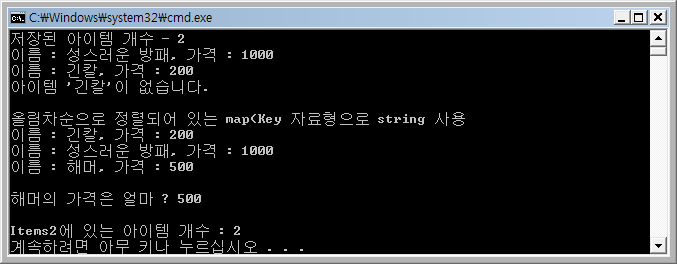
[리스트 1]의 Items에서 '긴칼'을 검색을 하면 찾을 수가 없습니다. 이유는 key의 자료형으로 char*을 사용했기 때문입니다. 그래서 Items2에서는 STL의 문자열 라이브러리인 string을 사용하였습니다. String에 대해서는 다음 기회에 설명할 예정이니 문자열을 처리하는 라이브러리라고 알고 계시면 됩니다.
이것으로 map에 대한 설명이 끝났습니다. 이전 회의 hash_map과 비슷한 부분이 많아서 hash_map에 대한 글을 보셨던 분들은 쉽게 따라왔으리라 생각합니다. 그리고 map과 hash_map에 대하여 잘못 알고 있어서 정렬이 필요하지 않은 곳에서 map을 사용하는 경우가 있는데 조심하시기 바랍니다. 제가 미쳐 설명하지 않은 부분에 대해서는 MSDN에 있는 map 설명을 참조하시기를 바랍니다(http://msdn.microsoft.com/ko-kr/library/xdayte4c.aspx).
과제
1. [리스트 1]은 아이템 이름을 key 값으로 사용하였습니다. 이번에는 아이템 가격을 Key 값으로 사용하여 아이템을 저장하고 내림차순으로 출력해 보세요.
앞서 중복된 key를 사용할 수 있는 multi_map 이라는 것이 있다고 이야기 했습니다. 이번 과제는 multi_map을 사용해야 합니다. multi_map에 관한 설명은 아래 링크의 글을 참조하세요. http://msdn.microsoft.com/ko-kr/library/1y9w8dz4.aspx
'STLTemplate > STL & EffectiveSTL' 카테고리의 다른 글
| 기초 : C++ STL 프로그래밍(9)-알고리즘1 (0) | 2012.12.27 |
|---|---|
| 기초 : C++ STL 프로그래밍(8)-셋(Set) (0) | 2012.12.27 |
| 기초 : C++ STL 프로그래밍(6)-해시 맵(Hash Map) (0) | 2012.12.27 |
| 기초 : C++ STL 프로그래밍(5)-덱(deque) : (2) (0) | 2012.12.27 |
| 기초 : C++ STL 프로그래밍(5)-덱(deque) : (1) (0) | 2012.12.27 |