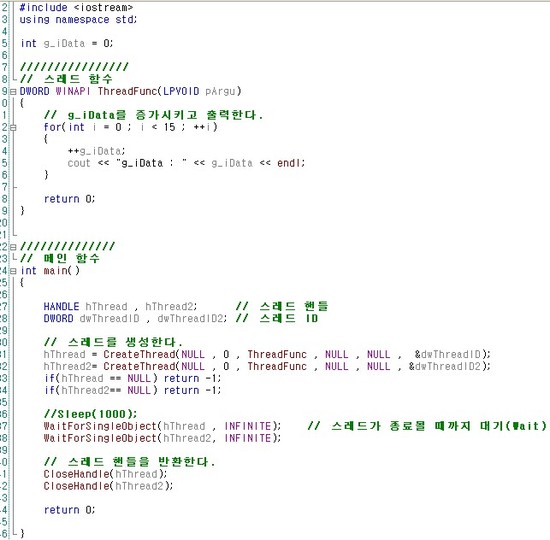
오랜만에 다시 강의를 시작합니다. *^^*
MSXML의 개요만
설명하고, VB와 VC++에서 사용법 예제를 지난 강의에 넣었습니다.
지금 다시보니 VB는 잘 되는 것 같은데, VC++에서는
dll의 포함여부에 따라 제대로 동작하기도 하고, 안하기도 하는 것 같습니다.
그래서 이 부분을 한번 정리해 보려고
합니다.
실제로 MSXML의 쓰임새는 VB가 더 많을 것이라고 생각합니다. ASP를 이용해 웹에서도 쓸 수 있고,
자바스크립트에서도 활용하고 있으니까요.
그러나 C/S 프로그램이나 XML관련 애플리케이션을 VC++로 개발하는 경우, 처음
msxml을 사용하려면 어려움을 겪는 분들이 간혹 있습니다.
특히, 저처럼 COM에 대한 개념이 생소한 분들이
그렇지요..
CoInitialze나 CoCreateInstance.. 이런 함수들이 튀어 나오면 그 순간.. 아주
답답해지죠..
실은 저도 COM에 대해서는 잘 모릅니다. 물론 위의 함수의 정확한 의미도 설명할 정도의 수준은
아니고요..
BUT, MSXML을 사용하기 위한 방법에 대해서는 한번 설명해 보려고 합니다.
VB는 MSDN에 나와있는
예제만 참고해도 잘 활용할 수는 있으니.. VC++을 먼저 알아보죠..
음.. 데브피아나 이런데 가면 좋은 MSXML을 위한
wrapper 클래스들이 많이 있을 테니.. 그걸 사용하셔도 되구요..
(저도 이 강의를 끝내면서 library 하나 만들어 볼까 합니다.
나름대로 편리하게 구성해서.. 쩝~ 생각만... 할려나.. 에궁)
필요작업
일단, VC++을 작업하기 위해서 필요한
것부터 간단히 정리해 보죠..
1. 플랫폼 SDK라는 것 들어봤죠.. 이걸 먼저 설치해야 합니다.
요즘 Visual
C++로 개발하는데, 이게 없으면 안되는 게 너무 많더군요.. 한번 설치해 두는 것도 괜찮을 것 같네요..
MS의 사이트
주소는 맨날 바뀌니.. 그렇더라도 현재 다운로드 할 수 있는 주소를 하나 적어놓을께요..
http://www.microsoft.com/msdownload/platformsdk/sdkupdate/default.htm
플랫폼 SDK를 설치하는 이유는 여기에 <msxml2.h>라는 헤더 파일이 있기 때문입니다.
2. VC++의 환경설정에서
플랫폼 SDK를 지정해 줘야 합니다.
뭐.. 대부분은 잘 아시겠지만, 혹여라도 잘 모르시는 분이 계실까봐~~
[Tools] - [Options] - [Directories]로 가셔서..
Inclue files 와
Library files에 플랫폼 SDK의 Include와 Lib를 지정하시면 됩니다.
이때, 플랫폼 SDK의
Include와 Lib를 가장 위로 올려놓는게 좋기는 합니다.
3. MFC를 사용하는 프로그램이라면, stdafx.h란 파일이
존재할 겁니다.
여기에 다음과 같은 소스를 아래부분에 추가합니다.
만약 stdafx.h가
없다면.. MSXML을 사용할 헤더나 소스 파일에 이걸 추가하면 됩니다.
#include
<MSXML2.H>
#pragma comment (lib, "msxml2.lib")
자.. 이렇게 하면 이제
MSXML을 사용할 준비가 된 것입니다. 그럼.. 시작해 볼까요..
MSXML 이해
MSXML 도움말을 살펴보면
Node나 Attribute를 선언할 때, 변수명이 특이합니다.
이것은 MSXML자체가 DOM 스펙을 따르면서 COM형태로
개발되었기 때문인것 같습니다.
IXMLDOMNode, IXMLDOMAttribute, IXMLDOMDocument
뭔가
공통점이 있죠?
I - 인터페이스를 의미하는 것 같네요
XML - XML이라는 거죠.. 당연한 거죠.. 쩝~
DOM -
DOM 스펙을 따른다는 이야기고..
나머지 - 각각의 의미를 나타내고 있죠..
그럼 자주 사용하는 몇가지 변수명만
설명할께요..
IXMLDOMDocument - XML 문서의 최상위 객체입니다. 다른 XML 객체는 여기에서부터 파생된다고 볼 수
있습니다.
IXMLDOMNode - XML의 각각의 Node를 가리키는 객체입니다. DOM의 가장 기본
요소입니다.
IXMLDOMAttribute - Node의 속성을 나타내는 객체입니다.
IXMLDOMElement - XML의
요소(Element)를 나타내는 객체입니다. 실제로 사용할 때는 Node를 더 많이 쓰는 것 같습니다. 요것
보다는
IXMLDOMNodeList - 주로 자식 노드의 리스트, XPath를 이용해 검색한 노드들의 리스트를 가리는
겁니다.
IXMLDOMNamedNodeMap - 주로 속성들의 리스트를 나타낼 때 사용합니다. NodeList와의 구분은 순서가 중요하냐의
여부에 달려있죠..
이외에도 IXMLDOMComment, IXMLDOMProcessInstruction.. 등이
있는데..
앞의 강좌인 XML 기본 강좌를 읽어보신 분은 대략 이해할 수 있을 거라 생각합니다.
이제 본격적으로 코딩을
해봅시다.
프로젝트는 알아서 만드시고.. 주요부분만 한번 해보도록 하겠습니다.
소스를 간결하게 하기 위해서 에러
처리부분은 생략했습니다.
에러가 포함된 소스는 자료실에서 다운로드 받으시면 됩니다.
그리고 여기에는 COM관련 함수들이 많이
나옵니다.
제가 COM을 잘 모르기 때문에 자세한 설명을 할 수가 없습니다. 혹, COM에 대해 잘 아시는 분이 계시면 코멘트를 달아서
설명해 주시면 고맙겠습니다.
MSXML을 사용하기 위해서 먼저 CoInitialize(NULL)를 실행해야 합니다.
그리고
메모리 해제를 위해 끝나면 CoUninitialize()를 하면 되겠죠..
이건 COM 객체를 사용하기 위해 기본적으로 사용하는 것
같습니다.
CoInitialize(NULL);
... // 이 사이에서 msxml을 활용하면
됩니다.
CoUninitialize();
CoInitialize나 CoUninitialize는 만약 클래스로 만든다면
생성자나 소멸자에 넣어도 되겠죠..
그럼 중간에서 XML을 사용하기 위해서는 XML의 기본 객체를 만들어야겠죠.. 바로
IXMLDOMDocument 입니다.
IXMLDOMDocument* m_pXml;
그리고 나서 인스턴스를
생성합니다.
CoCreateInstance(CLSID_DOMDocument, NULL, CLSCTX_INPROC_SERVER,
IID_IXMLDOMDocument2, (void**)&m_pXml);
이렇게 하면 xml 객체를 활용할 수 있게 됩니다.
바로 m_pXml을 통해서죠...
CoCreateInstance를 살펴보면,
Co - COM 관련 함수라는 의미 같은데요..
Cowork인가? 쩝~~ 암튼 그렇구요..
CreateInstance - 인스턴스를 생성하는 것이죠.. 객체지향 프로그램에서는 객체나
클래스, 인터페이스를 사용할 수 있도록 하기 위해서는 그것의 인스턴스를 생성해야 하죠..
여기까지 소스를 종합해보면 다음과
같습니다.
CoInitialize(NULL);
IXMLDOMDocument*
m_pXml;
CoCreateInstance(CLSID_DOMDocument, NULL, CLSCTX_INPROC_SERVER,
IID_IXMLDOMDocument2, (void**)&m_pXml);
// 필요한 작업을
수행합니다.
CoUninitialize();
그럼 이번 강좌에서는 XML 문서를 가져오는 것만 해보도록
하죠..
XML 문서는 XML 기초강좌에서 사용한 것을 활용하겠습니다.
MSDN에서 IXMLDOMDocument의 load
함수를 살펴보겠슴다.
XML 문서를 로드할 경우, 파일에서 로드하는 경우와 XML 문자열을 로드하는 경우가 있습니다.
일반적으로
XML 문자열을 로드하기 보다는 파일을 로드하는 경우가 많다고 생각되므로 파일 로드에 대해서 자세히 설명하도록
할께요.
HRESULT load(
VARIANT varXmlSource,
VARIANT_BOOL*
varIsSuccessful
);
함수 원형은 위와 같습니다.
VARIANT라는 것이 나오는데요.. 이건 각각의
형별로 union으로 선언한 것이라고 생각하면됩니다.
그러니까 "가변형"이라고 생각하면 되겠네요..
VARIANT
varXmlSource는 XML 파일명을 가리키는 것이고요
VARIANT_BOOL* varIsSuccessful 성공 여부를 가리키는
것입니다.
그럼 한번 적용해 볼까요?
CoInitialize(NULL);
IXMLDOMDocument*
m_pXml;
CoCreateInstance(CLSID_DOMDocument, NULL, CLSCTX_INPROC_SERVER,
IID_IXMLDOMDocument2, (void**)&m_pXml);
// 파일명을 지정합니다.
variant_t
file("test.xml");
VARIANT_BOOL bLoad;
// 파일을 오픈합니다.
HRESULT
hr;
hr = m_pXml->load(file, bLoad);
if (FAILED(hr)) return;
if
(bLoad) {
// 성공
}
CoUninitialize();
이런형태로 사용할 수 있습니다.
VARIANT 구조체에 맞추어 문자열을 변환하기 위해서 variant_t를 사용했네요..
이걸 사용하기 위해서는
#include <comdef.h>를 포함해야 합니다.
그리고 HRESULT라는 리턴값을
사용했습니다.
typedef LONG HRESULT;
MSDN에 보면 이렇게 선언되어 있는데요. 결과를 알려주는
것입니다.
정확하게 S_OK, S_FALSE, S_INVALIDARG로 리턴이 되는데..
성공과 실패여부를 확인하기 위해
SUCCEEDED(hr) 또는 FAILED(hr) 이렇게 사용할 수 있네요.
자.. 이번에는 읽은 XML 문서의 내용을
화면에 출력하는 부분을 해보도록 하겠습니다.
HRESULT get_xml(
BSTR *xmlstring);
여기에서는 BSTR을 사용하는 방법을 잘 살펴보시면 될 것 같습니다.
if (bLoad) {
BSTR bstr;
CString strValue;
// XML 내용
가져오기
m_pXml->get_xml(&bstr);
// BSTR
변환
USES_CONVERSION;
strValue.Format("%s",
W2A(bstr));
SysFreeString(bstr);
// 화면 출력
printf("%s\n",
strValue);
}
USES_CONVERSION이나 W2A와 같은 것을 사용하기 위해서는
#include
<atlconv.h>를 포함해야 함니다.
BSTR을 CString으로 변경하기 위해 위와 같은 방식을
사용했네요..
그냥 Casting을 해도 결과를 보는데는 문제가 없지만, 메모리 누수를 막기위해 저렇게 사용했습니다.
물론
위와 같은 방식이 아니라 VB와 같이 쉽게 VC++을 사용하는 방법이 있기는 합니다만,
전 이방식으로 쭉 설명할
계획입니다.
경우에 따라서는 필요하기 때문이죠.. C++에 대해서 잘 모르시는 분들은 좀 어렵게 느꼈을 것 같네요..
그래도
한번 따라해 보세요.. 한번의 실습이 열번 읽는 것보다 훨씬 나으니까요..
전체 소스를 한번 정리하겠습니다. 자료실에도 이와 관련된
소스를 넣어둘께요..
그럼.. 좋은 하루 되세요~~ 2005/03/29 미니
if
(!SUCCEEDED(CoInitialize(NULL))) return 0;
// Instance 생성
IXMLDOMDocument* m_pXml;
if
(!SUCCEEDED(CoCreateInstance(CLSID_DOMDocument, NULL,
CLSCTX_INPROC_SERVER, IID_IXMLDOMDocument2, (void**)&m_pXml))) {
CoUninitialize();
return 0;
}
// XML 파일 읽어오기
variant_t
file("test.xml");
VARIANT_BOOL bLoad;
HRESULT hr;
hr =
m_pXml->load(file, &bLoad);
if (FAILED(hr)) {
CoUninitialize();
return 0;
}
// XML 내용 출력
if (bLoad) {
BSTR bstr;
CString strValue;
// XML 내용 가져오기
hr =
m_pXml->get_xml(&bstr);
if (SUCCEEDED(hr)) {
// BSTR 변환
USES_CONVERSION;
strValue.Format("%s", W2A(bstr));
SysFreeString(bstr);
// 화면 출력
printf("%s\n",
strValue);
}
}
CoUninitialize();